
안녕하세요? HyperAccel ML팀 소속 박현준입니다. 2022년 11월 ChatGPT가 출시된 이래 AI 기술들이 기하급수적으로 빠르게 발전하며 하루가 멀다하고 새로운 AI tools가 출시되고 있습니다.

하드웨어에는 반도체 칩의 집적도가 2년마다 2배씩 증가한다는 무어의 법칙이 있다면, 최근에는 LLM의 자율 작업 수행 능력이 7개월마다 2배씩 증가한다는 연구 결과가 발표되고 있습니다. 초기 서비스가 이순신의 스마트폰에 대해 장황하게 설명하여 비웃음을 샀다면, 최근 서비스는 자연어는 물론이고 사진, 동영상, 오디오 등 거의 모든 입력을 높은 완성도로 처리해내고 있습니다. 이러한 기술 개발의 중심에 있는 아키텍처가 Transformer 입니다.

어떤 도구라도 잘 쓰기 위해서는 도구가 어떻게 생겼는지 자세하게 알아야 한다고 생각합니다. 따라서 이번 글에서는 Transformer 연산이 어떤 배경에서 등장하게 되었는지 먼저 알아봅니다. 그다음으로 연산이 어떻게 생겼는지 이해하고, 마지막으로 연산의 병목과 이를 해결하기 위한 기초적인 최적화 기법 몇 가지를 살펴보겠습니다.
Part 1: 등장 배경
세상을 바꾼 아키텍처, Transformer
2017년 Google 연구팀은 “Attention Is All You Need” 라는 논문을 발표하였습니다. 해당 논문은 문장을 한꺼번에 행렬로 처리하는 방식으로 기존 모델인 RNN/LSTM에 있었던 속도 한계를 해결하였을 뿐만 아니라 인간이 시퀀스를 이해하는 방법을 모방한 “Attention"이라는 기법으로 성능도 크게 향상시켰습니다. 요즘 핫한 Gemini , ChatGPT 를 비롯한 오늘날 대부분의 LLM이 이 논문에서 제시한 Transformer 구조를 기반으로 하고 있습니다.
LLM이 하는 일: 다음 단어 예측

Large Language Model(LLM) 의 동작 방식을 수학적으로 표현하면 “주어진 텍스트에 이어질 다음 단어를 예측하는 정교한 수학 함수"입니다. 단, 한 단어를 확정적으로 고르는 것이 아니라, 가능한 모든 다음 단어에 확률 을 부여합니다. 그 확률 분포에서 매번 하나를 샘플링하기 때문에, 같은 질문을 해도 실행할 때마다 다른 답이 나올 수 있습니다. 학습은 엄청난 양의 텍스트를 처리하면서 이 예측을 점점 정확하게 만드는 과정입니다. 실 사용에서 LLM은 “어떤 문장이든 넣으면 그다음에 올 단어를 그럴듯하게 예측해 주는 마법의 기계"입니다. 사람이 LLM에게 짧은 영화 대본을 물어보는 장면으로 예시를 들어보겠습니다. 사용자는 LLM에게 대본을 입력하면, 이 마법의 기계는 예측된 단어를 이어 붙이고, 다시 넣는 과정을 반복해 대본을 완성합니다. 이것이 바로 우리가 채팅봇과 대화할 때 실제로 일어나는 일입니다.
Part 2: Transformer 기본 구조 쪼개보기
전체 구조 개관
모델마다 세부 사항은 다르지만, 이번 글에서는 가장 간단한 모델인 GPT-2를 기준으로 작성하겠습니다. Transformer는 크게 Token Embedding, Decoder Block, LM Head 세 단계로 나눌 수 있으며, 이때 Decoder Block은 일반적으로 동일한 n개(GPT-2의 경우 24개)의 블록이 쌓여 있습니다. 하나의 블록은 또 다음과 같이 여섯 단계로 나눌 수 있습니다. 이를 그림으로 표현하면 다음과 같습니다.

Token & Positional Embedding
Transformer의 첫 단계는 사람의 언어를 컴퓨터가 이해할 수 있는 언어로 바꾸는 것입니다. 이를 Token Embedding 이라고 부르며, 각 토큰(token) 을 긴 숫자 리스트, 즉 벡터로 바꿉니다. (실제로는 한 단어가 한 토큰으로 1:1 대응되지는 않습니다만, 이해의 편의를 위해 1:1 대응된다고 가정하겠습니다.) 이렇게 변환을 하게 되면 각 단어가 긴 숫자 리스트로 변환되고, 이를 벡터라고 부르며, 이 벡터가 대응되는 단어의 의미를 갖게 됩니다. 같은 단어라도 문장 안에서 어디에 있느냐에 따라 의미가 달라지기 때문에 Positional Embedding 이라는 작업도 수행합니다.

여기서도 역시 GPT-2 Medium의 예시를 보겠습니다. 이 모델이 인식할 수 있는 토큰의 갯수(Vocab size)는 50,287개이고, 각 토큰은 크기가 1024인 벡터(embedding dimension)로 인코딩 됩니다. (이를 우리는 1024차원이라고도 부릅니다.) 이 역할을 수행하는 Word Token Embedding Table(WTE) 는 크기가 [50287, 1024]로, 각 토큰을 1,024차원 벡터로 매핑합니다.
Word Positional Embedding Table(WPE) 는 [1024, 1024]로 시퀀스 내 해당 단어의 위치를 1,024차원 벡터로 매핑합니다. 토큰 ID 시퀀스를 WTE에 넣어 [seq_len, 1024]를 얻고, 위치 인덱스를 WPE에 넣어 [seq_len, 1024]를 얻은 뒤, 두 행렬을 더하면 Decoder Block으로 들어갈 준비가 끝이 납니다.
Layer Normalization

Layer Normalization(LayerNorm) 은 Decoder Block의 첫 단계로, 각 토큰마다 평균과 분산을 맞춰 주는 정규화입니다. 저희가 중고등학교 수학시간에 배웠던 정규화(Normalization)와 같은 개념입니다. 입력 분포가 레이어마다 크게 달라지면 학습이 불안정해지고, 기울기 폭주나 소실이 생기기 쉽기 때문에 LayerNorm을 통해 각 위치의 벡터를 “적당한 스케일과 분포"로 맞춰 학습을 안정시키고, 깊은 네트워크에서도 층을 많이 쌓을 수 있게 합니다.
Self-Attention: Query, Key, Value의 의미
Attention이 해결하는 문제: 문맥에 따른 의미 결정

tower 로 예시를 들어보겠습니다. 처음에는 임베딩을 수행하면 “높은 구조물"이라는 일반적인 의미 방향으로 1024차원의 벡터가 생성됩니다. 이때 바로 앞에 Eiffel 이 오면, 그 벡터가 tower 쪽으로 정보를 보내 “에펠 탑"에 가까운 방향으로 갱신됩니다. 앞에 miniature 까지 있으면 “큰 것"과의 연관이 줄어들고 더 구체적인 의미로 바뀝니다. 한 토큰에서 다른 토큰으로의 정보 전달은 단어 하나를 넘어 긴 거리, 풍부한 문맥까지 포함할 수 있습니다. 추리 소설 끝부분 “Therefore the murderer was…“에서 다음 단어를 맞추려면, 마지막 벡터 was 가 앞선 전체 문맥의 정보를 흡수해야 합니다. Attention이 바로 그 “어떤 토큰이 어떤 토큰을 얼마나 참조할지"를 계산합니다.
Q, K, V 생성과 직관적 의미
GPT-2 Medium의 입력토큰은 1024개를 넘을 수 없습니다. 각 토큰은 크기가 1024인 벡터로 변환되므로, 해당 모델의 Attention Input은 최대 [1024, 1024](=[seq_len, N_embed])가 됩니다. 여기에 서로 다른 가중치 행렬 W_Q, W_K, W_V를 곱해 Query(Q) , Key(K) , Value(V) 라는 행렬을 만듭니다. 임베딩 차원(N_embed=1024)은 헤드 수(N_head=16)와 헤드당 차원(head_dim=64)로 나눠져 최종적으로 Q·K·V 행렬은 각각 [seq_len, N_head, head_dim] 형태가 됩니다.

직관을 위해 “Hello, my name is ____” 라는 문장에서 마지막 빈칸을 예측하는 상황을 생각해 보겠습니다. Part 1에서 LLM은 다음 단어를 예측하는 기계라고 했습니다. 빈칸을 채우려면 마지막 위치의 토큰 is 가 앞선 단어들의 정보를 끌어모아야 합니다. 이때 Q, K, V가 각각 다음 역할을 합니다.
- Query(Q) — is가 던지는 질문입니다. “다음에 올 단어를 맞추려면, 앞 문맥에서 어떤 정보를 가져와야 할까?” 이 질문이 is의 Q 벡터에 인코딩됩니다.
- Key(K) — 앞선 각 단어가 내미는 명찰입니다. Hello는 “나는 인사말이야”, my는 “나는 소유격이야”, name은 “나는 이름에 관한 단어야” 같은 태그를 K 벡터에 담고 있습니다. is의 Q와 각 단어의 K를 비교(내적)하면, name 의 점수가 가장 높게 나옵니다. “이름이 뭔지"를 맞춰야 하니까요.
- Value(V) — 점수가 높은 단어가 실제로 전달하는 내용입니다. name의 V에는 “이름"이라는 의미가 담겨 있고, 이 정보가 점수 비중대로 합쳐져서 is의 벡터를 갱신합니다.
이렇게 갱신된 is 벡터에는 “인사 + 나의 + 이름 + ~이다"라는 문맥이 응축되어 있고, 이 벡터가 LM Head를 거치면 빈칸에 John 같은 사람 이름이 높은 확률로 나오게 됩니다. 요약하면 Q는 “다음 단어를 맞추기 위해 무엇이 필요한가(질문)”, K는 “나는 어떤 종류의 단서를 갖고 있는가(명찰)”, V는 “내가 실제로 넘겨줄 의미(내용)“입니다.
Query · Keyᵀ: 유사도 Score와 마스킹

아까 N_head개만큼 헤드가 있다고 말씀드렸는데요, 하나의 헤드 안에서 Q와 K의 크기는 [N_position, head_dim] 입니다. K를 전치해 Kᵀ [head_dim, N_position]로 두고 Score = Q · Kᵀ 를 계산하면 [N_position, N_position] 행렬이 나옵니다. 행은 “현재 Query를 가진 토큰”, 열은 “참조 가능한 모든 위치"이고, (i, j) 원소는 i번째 토큰이 j번째 토큰을 얼마나 중요하게 보는지에 대한 스코어입니다. Query와 Key 벡터가 가까울수록(정렬될수록) 내적이 커집니다.
사람도 왼쪽에서 오른쪽으로 글을 읽듯, Attention 연산에서도 과거 토큰이 미래 토큰을 알 수 없도록 해야 하고, 이를 위해 마스킹 기법을 사용합니다. “나보다 뒤에 있는 위치"의 Score를 Softmax 전에 −∞로 두면, Softmax 후에는 0이 되어, 뒤쪽 토큰은 앞쪽 토큰에 영향을 주지 않습니다. 즉 “뒤 토큰이 앞 토큰을 바꾸는 것"을 막는 것입니다.
Softmax & Value 가중합

거의 다 왔습니다 조금만 더 힘을 내볼까요! Score 행렬의 각 행 (각 Query 위치)에 Softmax 를 적용합니다. softmax 연산 특성으로 인해 한 행의 합이 1이 됩니다. 그리고 이 값들은 “다른 토큰들을 얼마나 비중 두고 볼지"에 대한 확률 분포를 의미하게 됩니다. 예를 들어 “헬스 2, 테니스 1, 침대 0.1” 같은 점수를 “헬스 0.7, 테니스 0.2, 침대 0.1"로 바꾼다면, 각 숫자는 값에서 확률값이 됩니다. 각 Query 위치에서, 모든 위치의 Value 벡터에 위에서 구한 가중치를 곱해 가중합 하면, 그 위치에 더해 줄 갱신 벡터(ΔE)가 나옵니다.
Multi-Head Attention과 Output Projection

Attention Layer에 들어갈 때 [seq_len, N_embed]를 [seq_len, N_head, head_dim]으로 쪼갰었습니다. 헤드라는 개념은 모델 성능을 향상시키기 위해 채택되었습니다. 한 head는 “형용사–명사” 같은 한 종류의 관계에 특화될 수 있지만, 언어에서 문맥이 바뀌는 방식은 매우 다양합니다. 그래서 서로 다른 Q·K·V 행렬을 가진 여러 head로 분할하고, 각 head를 병렬로 처리함으로써 문맥 이해 능력을 향상시킨 것입니다. 각 head는 서로 다른 서브스페이스에서 [N_position, head_dim] 출력을 만든 뒤, 이들을 concatenate 하여 [N_position, N_embed]로 만듭니다.
마지막으로 Output Projection(FC): ConcatenatedAttention · W_O + b_O 로 [N_embed, N_embed] 가중치를 적용해, 여러 head에서 나온 정보를 하나의 표현 공간으로 다시 묶습니다. 이것이 한 블록의 Multi-Head Attention 최종 출력입니다. 이제 어려운 부분은 다 끝났습니다!
Residual Connection

Self-Attention 출력과 원래 입력을 더하는 연결을 Residual Connection(skip connection) 이라고 합니다. y = x + AttentionOutput 형태로, 이름은 거창하지만 본질은 행렬 덧셈입니다. 원래 정보 x를 유지한 채 Attention이 포착한 변화분 만 더하는 구조이기 때문에, 깊은 네트워크에서도 기울기가 잘 전달되고 학습이 안정적입니다.
Feed-Forward Network (FFN)
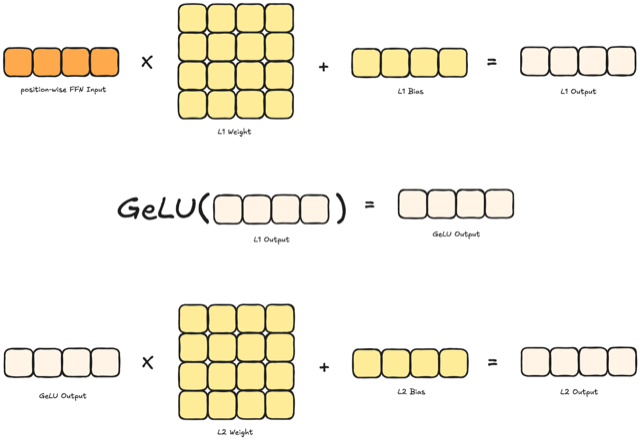
이쯤되서 다시 리마인드해보면, 하나의 디코더 레이어는 총 6단계(Layernorm-Attention-Residual-Layernorm-FFN-Residual)로 이루어져 있습니다. Layernorm과 Residual은 중복이므로 Feed-Forward Network(FFN) 을 마지막으로 살펴보겠습니다. FFN은 두 개의 Linear 레이어와 그 사이의 Activation Function 로 구성됩니다. 입력 [N_position, N_embed]에 첫 번째 Linear로 차원을 확장 하고, 활성화(예: GeLU)를 거친 뒤, 두 번째 Linear로 다시 차원을 축소 하여 [N_position, N_embed]를 만듭니다. 각 위치마다 독립적으로 같은 MLP가 적용된다고 보시면 되고(position-wise FFN), 이 연산은 Attention에서 모인 정보를 비선형 변환으로 더 복잡한 특징 공간에 매핑하는 역할을 합니다. 앞에서 말했던 6단계를 모두 수행하면 하나의 디코더 블록 연산이 끝이 나고, 동일 과정을 N번(GPT-2의 경우 24번) 반복하면 Decoder Block 연산이 모두 끝이 나게 됩니다.
LM Head: 다음 토큰 예측

마지막 단계인 LM Head는 벡터를 다시 인간이 이해할 수 있는 단어로 변환하는 단계입니다. 보통 Token Embedding Table(WTE) 의 전치(transpose)를 사용해 logit 을 계산합니다. 이 logit에 Softmax 를 적용하면 다음 토큰으로 어떤 토큰을 출력하면 좋을지에 대한 확률 분포가 나오게 됩니다.
물론 확률이 가장 높은 토큰을 출력하는 방식도 있지만, 일반적으로 sampling 을 사용하여 확률에 따라 하나를 뽑아 다음 토큰으로 씁니다. 이때 샘플링 범위를 조절하는 대표적인 파라미터가 top_k 와 top_p 인데, 두 파라미터를 함께 쓰면 “너무 엉뚱한 단어가 뽑히는 것"을 막으면서도 자연스러운 다양성을 유지할 수 있습니다.
축하드립니다! 여기까지 이해하셨다면 Transformer의 기본 구조를 모두 파악하신 겁니다. 한 번에 모든 내용이 와닿지 않더라도 괜찮습니다. Transformer는 최근 아키텍처인 만큼 결코 쉬운 주제가 아닙니다. 이 글에서는 구체적인 수치와 연산의 의미를 중심으로 설명드렸지만, 다양한 관점의 글들을 꾸준히 접하시다 보면 점점 익숙해지실 겁니다. 이제 마지막 파트로 가서 대표적인 최적화 기법에 대해 다뤄보겠습니다.
Part 3: 최적화 기법
KV Cache와 메모리·대역폭 이슈
Part 2에서 가장 중요한 연산은 단연 Attention인데요, Query와 Key를 곱하여 나오는 Score 행렬의 크기는 context size의 제곱 입니다. 토큰이 N개면 N×N 행렬이므로, 문맥이 길어질수록 연산량과 메모리가 빠르게 늘어납니다. 추론 시에는 이전 스텝에서 계산한 Key 와 Value 를 다시 쓰기 위해 KV cache 에 저장하지만, 문맥이 길수록 이 캐시가 너무나 커져서 문맥 길이·메모리·대역폭이 큰 병목이 됩니다.
예를 들어 LLaMA-3-70B 를 bfloat16(bf16) 기준으로 100만 토큰 문맥으로 돌린다고 하겠습니다. 모델 파라미터 70B × 2 byte ≈ 140GB입니다. KV cache는 2(K,V) × 배치 1 × 레이어 80 × KV head 8 × head 차원 128 × 시퀀스 1M × 2 byte 식으로 잡으면 약 328GB 수준이 될 수 있습니다. 한 토큰을 생성할 때 읽어야 할 메모리가 모델 + KV cache로 약 468GB이고, 초당 20 토큰을 만들려면 이론상 10TB/s급 메모리 대역폭이 필요하다는 식으로 이해하시면 됩니다. 최신 GPU인 NVIDIA B100의 메모리 대역폭이 최대 8TB/s이며 메모리 용량은 192GB에 불과하다는 것을 생각하면 어느정도 수준인지 감이 오실 겁니다.
KV Cache Architecture 비교 (MHA, MQA, GQA, MLA)
KV를 어떻게 저장·공유하느냐에 따라 크게 4가지 방식(MHA, MQA, GQA, MLA)으로 나눌 수 있습니다. 핵심 trade-off는 정확도(표현력) 와 KV cache 크기(메모리·대역폭) 사이의 균형이며, 이 차이를 시각적으로 잘 풀어준 논문이 있어 사진자료 첨부드립니다.

Multi-Head Attention (MHA)
원래 Transformer 논문에서 제안된 구조입니다. Query head마다 자기 전용 K, V head가 있어 1 Query : 1 KV 관계입니다. GPT-3, LLaMA 1/2 등이 이 방식을 씁니다.
- 장점: head마다 독립적인 K, V를 가지므로 표현력이 가장 높고, 다양한 패턴을 동시에 포착할 수 있습니다. 정확도 면에서 가장 유리합니다.
- 단점: KV cache를 head 수만큼 전부 저장해야 하므로, 문맥이 길어지면 메모리 사용량과 대역폭 요구가 급격히 커집니다.
Multi-Query Attention (MQA)
모든 Query head가 하나의 K, V head를 공유합니다. N Query : 1 KV 관계이며 PaLM, Falcon, StarCoder 등에서 사용합니다.
- 장점: KV cache 크기가 MHA의 1/N_head 수준으로 줄어들어, 추론 시 메모리·대역폭 부담이 크게 감소합니다. 배치 크기를 늘리거나 긴 문맥을 처리하기 훨씬 유리합니다.
- 단점: 모든 head가 같은 K, V를 보기 때문에, head별로 서로 다른 관계를 포착하는 능력이 떨어집니다. MHA 대비 정확도가 다소 하락하는 trade-off가 있습니다.
Grouped-Query Attention (GQA)
Query head를 여러 그룹 으로 나누고, 그룹마다 하나의 KV 쌍을 공유합니다. MHA(1:1)와 MQA(N:1)의 중간으로, N Query : M KV 관계입니다. 예를 들어 Query head 32개, KV head 8개면 Query 4개가 KV 1개를 공유합니다. LLaMA-2-70B, LLaMA-3, Mistral 등이 GQA를 씁니다.
- 장점: MQA보다 KV head가 많아 표현력이 높으면서, MHA보다 KV cache가 작습니다. 정확도와 효율 사이에서 실전적으로 가장 균형 잡힌 선택지로 평가받고 있습니다.
- 단점: MHA에 비하면 여전히 head 간 KV를 공유하므로 표현력이 제한되고, MQA만큼 메모리를 줄이지는 못합니다.
Multi-Head Latent Attention (MLA)
K, V를 저차원 latent 벡터로 압축(projection)한 뒤, 그 latent 공간에서 Attention을 수행합니다. KV cache에는 원래 K, V 대신 이 작은 latent 벡터만 저장하면 됩니다. DeepSeek-V2/V3 등에서 사용합니다.
- 장점: KV cache를 원래 차원보다 훨씬 작은 latent 차원으로 압축하므로, GQA보다도 메모리 효율이 좋습니다. 동시에 head마다 독립적인 Q를 유지해 표현력을 크게 희생하지 않습니다.
- 단점: latent projection을 위한 추가 연산(압축·복원 행렬곱)이 필요하고, 구현 복잡도가 높습니다. 압축 과정에서 정보 손실이 발생할 수 있어, 압축 비율을 잘 조절해야 합니다.
언제 무엇을 쓸까? (상황별 선택 가이드)
위 네 가지 방식은 “항상 이것이 정답”이라기보다(물론 대세는 있지만) 문맥 길이·메모리·품질 요구·구현 환경에 따라 선택이 달라집니다. 빠르게 변하는 LLM 생태계에서는 예전에 쓰이던 조합이 지금은 잘 언급되지 않기도 하고, 반대로 “지금은 GQA가 대세”라고만 알고 있으면 왜 MHA나 MQA를 쓸 때가 있는지 헷갈리기 쉽습니다. 아래는 각 방식을 어떤 상황에서 고려할 수 있는지 정리한 가이드입니다.
- MHA — 문맥이 짧고(예: 수백~수천 토큰), 정확도·표현력을 최우선으로 할 때. 연구·실험용 소형 모델, 또는 KV cache 부담이 상대적으로 작은 서비스에서 여전히 의미 있습니다. 초기 Transformer·GPT-3·LLaMA 1/2 시절의 기본 선택이었고, “head마다 독립적인 K·V”라는 원론적 구조를 유지하고 싶을 때 참고할 수 있습니다.
- MQA — 메모리·대역폭이 극한이고, 문맥이 매우 길거나 배치 크기를 크게 잡아야 할 때. PaLM·Falcon·StarCoder처럼 “KV를 하나만 두고 모든 Query가 공유”하는 구조라 cache가 가장 작습니다. 표현력은 MHA·GQA보다 떨어질 수 있으므로, 품질보다 처리량·규모 확장이 더 중요한 배포 환경에서 고려합니다.
- GQA — 일반적인 프로덕션에서 정확도와 효율의 균형이 필요할 때. LLaMA-2-70B·LLaMA-3·Mistral 등 대부분의 최신 오픈 LLM이 채택한 방식으로, “어떤 걸 쓸지 모르겠다”면 GQA를 기본으로 두고, 문맥이 극단적으로 길거나 메모리가 극히 부족한 경우에만 MQA·MLA를 검토하는 식으로 쓰면 됩니다.
- MLA — 긴 문맥 + 메모리 효율을 동시에 요구하되, GQA보다 더 aggressive한 cache 절감이 필요할 때. DeepSeek-V2/V3처럼 latent로 K·V를 압축하는 방식이라 구현·튜닝 난이도는 있지만, “head별 Q는 유지하면서 cache만 줄이고 싶다”는 요구에 잘 맞습니다. 인프라와 실험 리소스가 충분한 팀에서 도입을 검토하기 좋습니다.
정리하면, 모든 튜닝이 항상 맞는 것은 아니고 적절한 상황에 맞게 선택해야 의미가 있습니다. 짧은 대화 위주 서비스와 100만 토큰급 문서 서비스는 같은 “Attention 최적화”라도 다른 구조가 어울릴 수 있다는 점만 기억해 두면 도움이 됩니다.
정리
이 글에서는 LLM의 동작 원리부터 LLM을 구성하는 각 연산의 의미를 적절한 비유와 함께 살펴보았습니다. 다시 한번 요약하자면, Transformer architecture는 크게 Token Embedding, Decoder Block, LM Head 세 단계로 구성되어 있고, Decoder Block은 다시 LayerNorm, Attention, Residual, LayerNorm, FFN, Residual로 쪼개서 살펴볼 수 있습니다. 마지막으로 문맥 길이에 따른 O(N²) 비용과 KV cache 메모리·대역폭 이슈, 그리고 이를 해결하기 위한 MHA·MQA·GQA·MLA 같은 KV Cache 관련 기본적인 구조 변형을 비교해보았습니다.
Reference
https://arxiv.org/pdf/2209.10797
https://arxiv.org/pdf/2503.11486
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
HyperAccel 채용 중!
저희는 LLM 추론 최적화의 최전선에서 성장하고 있는 NPU 설계 스타트업입니다. 이번 글은 하이퍼엑셀 내부 교육자료를 바탕으로 작성되었는데요, 이처럼 서로의 전문성을 공유하며 함께 성장하는 문화가 저희의 강점입니다.
저희가 다루는 기술에 관심이 있고, 이 흐름에 함께하고 싶다면 아래 링크에서 지원해 주세요. HyperAccel Career