이 글은 AI 시대의 필수 소비재, 메모리 이해하기 시리즈의 1편입니다.
들어가며
안녕하세요, HyperAccel에서 RTL Designer로 재직 중인 신승빈입니다.
최근 주식 시장에서 “메모리, 반도체 관련주"가 연일 화제입니다.
최근에는 “HBF"라는 새로운 단어가 들리기 시작하며 “그게 뭔데?”, “그래서 사라고?” 이런 이야기가 많이 나오고 있죠.
그렇다면 여기서 High Bandwidth Flash(HBF) 란 무엇일까요?
HBF를 이해하려면 먼저 한 가지 질문에 답할 수 있어야 합니다.
“컴퓨터에는 왜 이렇게 많은 종류의 메모리가 있는 걸까?”
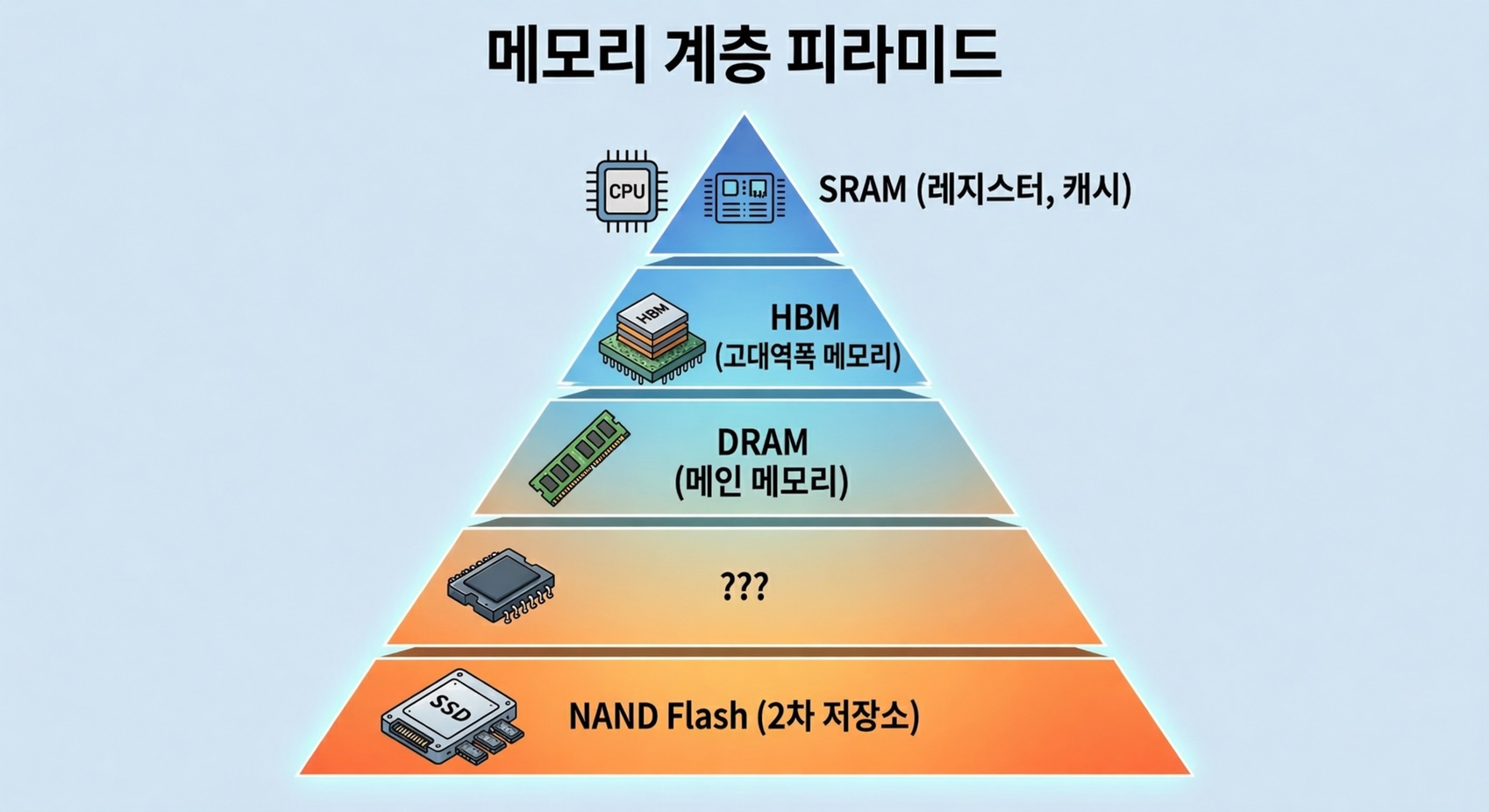
우리가 쓰는 컴퓨터 안에는 SRAM, DRAM, HBM, SSD 등 이름부터 복잡한 메모리들이 여러 계층으로 나뉘어 존재합니다. 전부 “데이터를 저장하는 것"인데 왜 하나로 통일하지 않을까요?
이 질문에 답하다 보면, HBF가 왜 등장했고 어디에 위치하는지가 자연스럽게 보이게 됩니다.
이 포스팅의 내용은 제가 개인적으로 공부하고, 경험한 내용을 바탕으로 작성되었습니다. 오류가 있다면 언제든지 댓글로 알려주세요.
메모리는 왜 여러 종류인가 — 속도/용량/비용의 트릴레마
결론부터 말하면, 빠른 메모리는 비싸고 작고, 싼 메모리는 느리고 크기 때문 입니다.
이건 단순히 기술이 덜 발전해서가 아닙니다. 메모리 셀의 물리적 구조 자체가 이 트레이드오프를 결정합니다. 트랜지스터를 많이 써서 셀을 만들면 빠르지만 면적을 많이 차지하고, 셀을 단순하게 만들면 느리지만 같은 면적에 훨씬 많은 데이터를 저장할 수 있습니다.
컴퓨터는 이 물리적 한계를 우회하기 위해 여러 종류의 메모리를 계층(Hierarchy) 으로 쌓아 사용합니다. 프로세서에 가까울수록 빠르고 작은 메모리를, 멀어질수록 느리지만 큰 메모리를 배치하는 것이죠.
이제 각 계층의 메모리가 왜 그런 특성을 갖는지, 셀 구조부터 살펴보겠습니다.

SRAM — 가장 빠르고, 가장 비싼
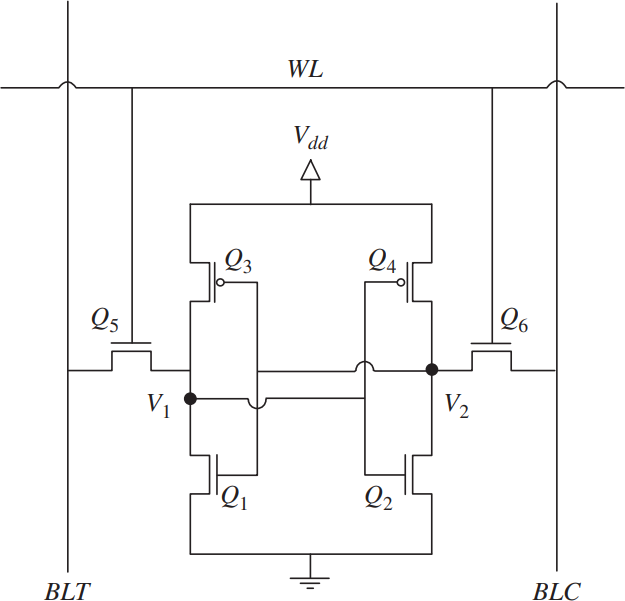
셀 구조: 트랜지스터 6개로 1비트
Static Random Access Memory(SRAM) 은 하나의 비트를 저장하기 위해 6개의 트랜지스터를 사용합니다. 이를 6T SRAM 셀 이라고 부릅니다.
6개의 트랜지스터 중 4개는 두 개의 인버터를 구성하여 서로의 출력을 교차 연결(cross-coupled)합니다. 이 구조는 전원이 공급되는 한 자체적으로 상태를 유지하는 래치(latch)를 형성합니다. 나머지 2개의 트랜지스터는 읽기와 쓰기 시 셀에 접근하기 위한 패스 게이트(pass gate) 역할을 합니다.
왜 빠른가
SRAM이 빠른 이유는 명확합니다.
래치가 상태를 자체적으로 유지하기 때문에 리프레시(refresh)가 필요 없습니다. “Static"이라는 이름이 여기서 옵니다. 읽기 동작은 래치에 저장된 전압 상태를 비트라인으로 전달하는 것이 전부이므로, 접근 지연이 1ns 이하 수준입니다.
왜 비싼가
문제는 크기입니다. 1비트에 트랜지스터 6개가 필요하니, 셀 하나의 면적이 큽니다. 같은 크기의 실리콘 웨이퍼에서 만들 수 있는 비트 수가 적다는 뜻이고, 이는 곧 비트당 단가가 매우 높다 는 것을 의미합니다.
그래서 SRAM은 대용량으로 사용하는 것이 물리적으로나 경제적으로나 비현실적입니다. CPU나 GPU 내부의 캐시(L1/L2/L3) 나, AI 가속기의 온칩 메모리 로 수 MB에서 수십 MB 정도만 탑재됩니다.
빠르지만 비싸고, 용량이 작다. 그래서 프로세서 바로 옆에, 가장 자주 쓰는 데이터만 담아둡니다.
DRAM — 싸고 크지만, 끊임없이 새로고침
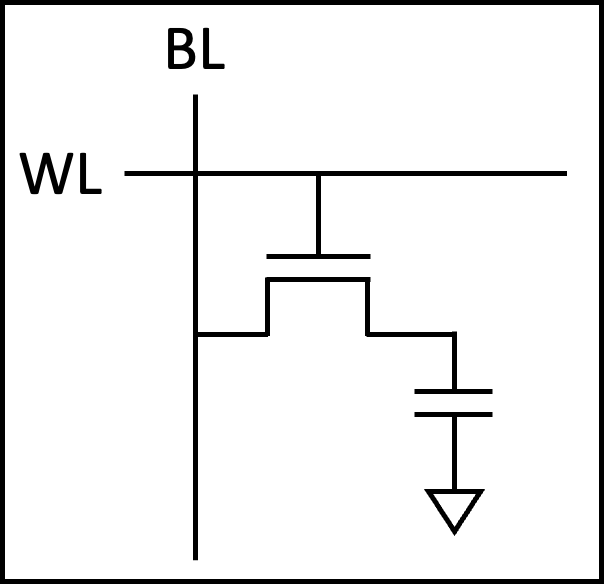
셀 구조: 트랜지스터 1개 + 커패시터 1개
Dynamic Random Access Memory(DRAM) 의 셀 구조는 SRAM과 극적으로 다릅니다. 트랜지스터 1개와 커패시터(축전기) 1개, 단 2개의 소자로 1비트를 저장합니다. 이를 1T1C 구조 라고 합니다.
커패시터에 전하가 충전되어 있으면 1, 방전되어 있으면 0입니다. 트랜지스터는 이 커패시터에 접근하기 위한 스위치 역할을 합니다.
왜 싼가
셀에 필요한 소자가 2개뿐이므로, 셀 면적이 SRAM의 1/4에서 1/6 수준 입니다. 같은 웨이퍼에서 훨씬 더 많은 비트를 생산할 수 있으니, 비트당 단가가 크게 낮아집니다. 이 밀도 이점 덕분에 DRAM은 수 GB에서 수십 GB 단위의 메인 메모리로 사용됩니다.
왜 느린가 (상대적으로)
커패시터는 시간이 지나면 저장된 전하가 조금씩 누설됩니다. 그래서 데이터가 사라지기 전에 주기적으로 전하를 다시 채워주는 리프레시(refresh) 동작이 필요합니다. “Dynamic"이라는 이름은 바로 이 특성에서 유래합니다.
읽기 동작도 SRAM보다 복잡합니다. 커패시터의 전하를 비트라인으로 공유(charge sharing)한 뒤 감지 증폭기(sense amplifier)로 증폭해야 하고, 읽기 과정에서 전하가 소모되므로 읽은 직후 다시 써줘야(restore) 합니다.
이런 과정들이 추가되기 때문에 접근 지연은 10-100ns 수준 으로, SRAM보다 10배 이상 느립니다.
DDR: DRAM의 속도를 끌어올리는 인터페이스
DRAM 셀 자체는 느리지만, 외부와 데이터를 주고받는 인터페이스 규격 을 개선하면 실질 전송 속도를 높일 수 있습니다. 그 규격이 바로 Double Data Rate(DDR) 입니다.
DDR 이전의 SDRAM은 클럭의 상승 엣지(rising edge)에서만 데이터를 전송했습니다. DDR은 이름 그대로 상승 엣지와 하강 엣지 양쪽 모두 에서 데이터를 전송하여, 같은 클럭에서 전송량을 2배로 늘렸습니다.
이후 세대가 거듭되면서 프리페치(prefetch) 깊이를 늘리는 방식으로 전송 속도를 끌어올렸습니다. 프리페치란 한 번의 내부 메모리 접근으로 여러 비트(beat)를 미리 꺼내두는 기법으로, 내부 클럭보다 외부 전송 속도를 더 빠르게 만들어 줍니다. DDR4는 한 번에 8비트를, DDR5는 16비트를 프리페치합니다. 덕분에 DDR5는 단일 모듈 기준 최대 약 50 GB/s 수준의 대역폭을 제공합니다.
하지만 이 개선에는 근본적인 천장이 있습니다.
HBM — DRAM을 쌓아올리다
핀 수의 한계를 패키징으로 돌파하기
DDR의 데이터 버스 폭은 DDR5 기준 64비트 입니다. 프로세서와 메모리를 연결하는 물리적 핀 수에 제한이 있기 때문에, 클럭을 아무리 올려도 한 번에 전송할 수 있는 데이터의 양에는 천장이 존재합니다.
AI 연산처럼 대규모 데이터를 동시에 읽어야 하는 워크로드에서는 이 병목이 치명적입니다. High Bandwidth Memory(HBM) 는 이 문제를 셀 구조가 아닌 패키징 으로 해결합니다.
핵심 아이디어는 간단합니다. DRAM 다이를 수직으로 쌓고, 기판 위에서 프로세서 바로 옆에 배치하는 것입니다.
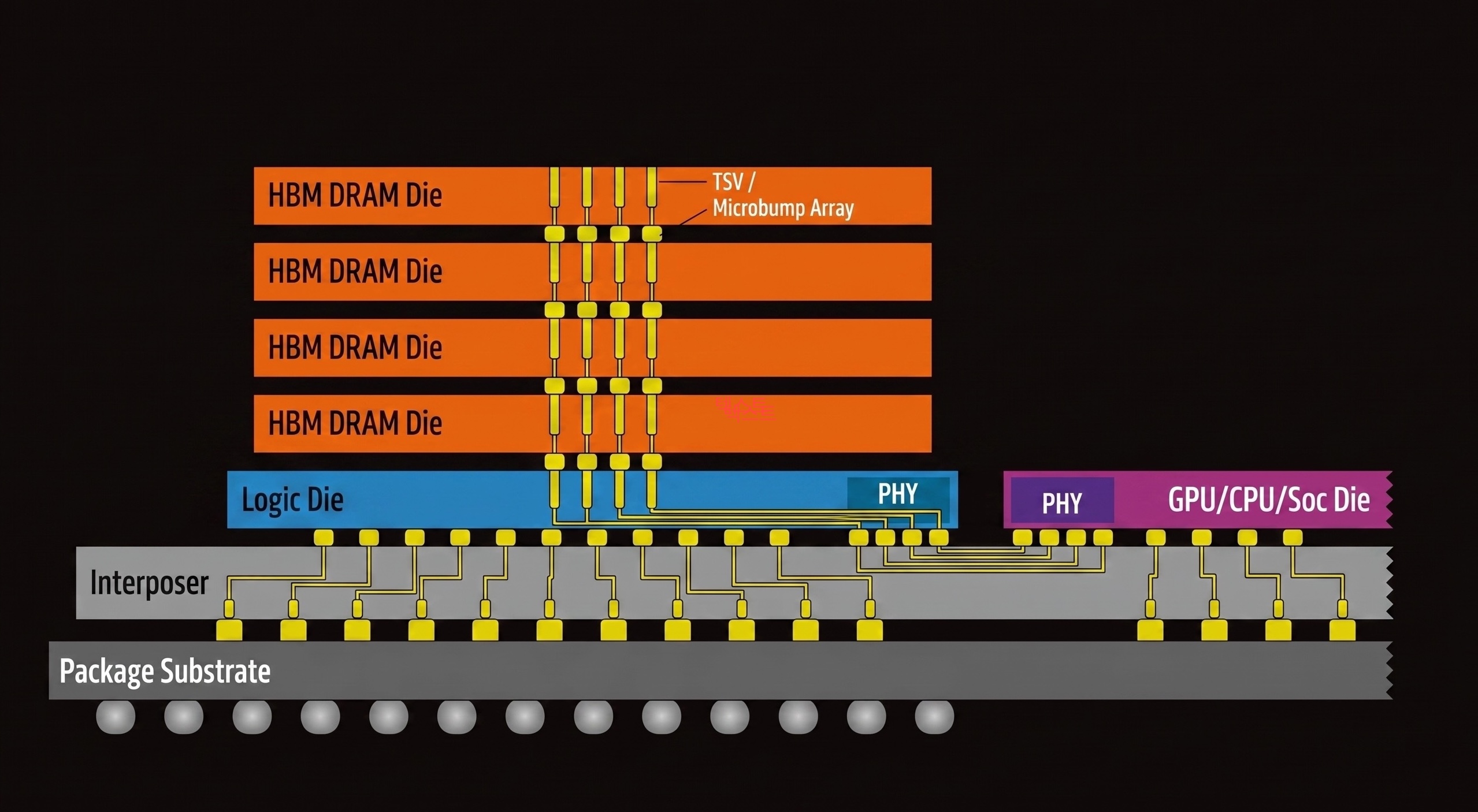
TSV: 실리콘을 관통하는 수직 배선
일반적인 DRAM 모듈은 PCB 위의 배선으로 프로세서와 연결됩니다. HBM은 다릅니다. 실리콘 다이 자체에 미세한 구멍을 뚫고 구리 배선을 채워 넣어, 위아래 다이를 수직으로 연결합니다. 이것이 Through-Silicon Via(TSV), 실리콘 관통 전극입니다.
TSV 덕분에 여러 장의 DRAM 다이를 한 스택으로 쌓을 수 있고, 각 다이가 독립적인 데이터 경로를 가지므로 버스 폭을 극적으로 넓힐 수 있습니다. HBM4 기준 데이터 버스 폭은 2048비트 로, DDR5의 32배 입니다.
인터포저: 프로세서 바로 옆에 붙이다
HBM 스택은 실리콘 인터포저(interposer) 라는 중간 기판 위에 GPU 또는 AI 가속기와 나란히 배치됩니다. 인터포저 내부의 미세 배선이 HBM과 프로세서를 불과 수 mm 거리에서 연결하므로, 기존 DDR 모듈이 PCB를 통해 수십 cm를 이동하던 것과 비교하면 배선 거리가 극적으로 줄어듭니다.
짧은 배선 = 낮은 지연 + 낮은 소비 전력 + 높은 신호 무결성. 이 조합이 HBM의 대역폭을 가능하게 합니다.
수치로 보는 HBM
| 항목 | DDR5 | HBM3E | HBM4 |
|---|---|---|---|
| 버스 폭 | 64-bit | 1024-bit | 2048-bit |
| 스택당 대역폭 | ~50 GB/s | ~1.2 TB/s | ~2 TB/s 이상 |
| 스택당 용량 | - | 24-36 GB | 36-48 GB |
| 프로세서와의 거리 | 수십 cm (PCB) | 수 mm (인터포저) | 수 mm (인터포저) |
2025년 4월 반도체 표준화 기구인 Joint Electron Device Engineering Council(JEDEC) 이 HBM4 표준을 공식 발표했습니다. 이후 2026년 초부터 양산이 시작되었습니다.
SK하이닉스는 세계 최초로 16층 48GB HBM4 스택을 공개했습니다. NVIDIA의 차세대 GPU인 Vera Rubin은 HBM4 스택 8개를 탑재하여 총 384GB, 약 22 TB/s 의 메모리 대역폭을 목표로 하고 있습니다.
HBM의 한계: 빠르지만, 여전히 부족한 용량
HBM4까지 오면서 대역폭과 용량 모두 크게 성장했지만, 근본적인 제약은 여전합니다.
셀 자체는 여전히 DRAM(1T1C)이므로, 비트 밀도의 한계는 그대로입니다. TSV 공정, 인터포저 제조, 다이 적층 시 수율 관리, 열 방출 문제까지 겹치면서 용량 대비 가격이 매우 높습니다.
HBM4 8스택을 전부 탑재해도 최대 384GB입니다. 그런데 최신 Large Language Model(LLM) 의 파라미터 크기는 수백 GB에서 수 TB에 달합니다. 모델이 커지는 속도를 HBM의 용량 확장이 따라가지 못하고 있는 것이죠.
NAND Flash — 싸고 크지만, 너무 느린
셀 구조: 전하를 가둬서 비트를 저장하다
NAND Flash 는 SRAM이나 DRAM과는 근본적으로 다른 원리로 데이터를 저장합니다.
NAND 셀의 핵심은 플로팅 게이트(floating gate) 라는 절연층으로 둘러싸인 전도체입니다. 높은 전압을 가하면 전자가 터널링(tunneling) 현상을 통해 플로팅 게이트에 주입되고, 절연층이 전자의 탈출을 막아 전원이 꺼져도 데이터가 유지 됩니다. 이것이 NAND가 비휘발성(non-volatile) 메모리인 이유입니다.
왜 싸고 큰가: 극한의 밀도
NAND의 밀도 이점은 두 가지에서 옵니다.
첫째, 멀티 레벨 셀 입니다. 하나의 셀에 저장하는 전하량을 세밀하게 구분하면 여러 비트를 담을 수 있습니다. Triple-Level Cell(TLC) 는 셀당 3비트, Quad-Level Cell(QLC) 는 셀당 4비트를 저장합니다.
면적당 집적밀도로 비교하면 그 차이가 더 극적입니다. SRAM은 약 0.04 Gb/mm² 수준인 반면, DRAM은 약 0.2-0.3 Gb/mm², 최신 3D NAND는 약 5-15 Gb/mm² 에 달합니다. 같은 실리콘 면적에서 SRAM 대비 100배 이상, DRAM 대비 20배 이상의 데이터를 저장할 수 있는 셈입니다.
둘째, 3D 적층 입니다. 현대 NAND는 셀을 평면이 아닌 수직으로 수백 층을 쌓습니다. 삼성의 V-NAND, SanDisk의 BiCS NAND가 대표적이며, 최신 제품은 200층을 넘어섰습니다.
이 두 가지 덕분에 NAND는 TB 단위의 대용량을 매우 낮은 비트당 단가로 제공합니다.
왜 느린가: 읽기만 해도 마이크로초
NAND의 읽기 동작은 플로팅 게이트의 전하량에 따라 달라지는 트랜지스터의 문턱 전압(threshold voltage)을 측정하는 과정입니다. 멀티 레벨 셀에서는 여러 단계의 전압을 정밀하게 구분해야 하므로 시간이 더 걸립니다.
결과적으로 NAND의 랜덤 읽기 지연은 약 50-100us 수준입니다. DRAM의 수십 ns, SRAM의 1ns 이하와 비교하면 1,000배 이상 느린 셈입니다.
쓰기는 더 느리고, 데이터를 덮어쓰려면 블록 단위로 먼저 지워야(erase) 합니다. 게다가 erase/write 반복 횟수에 물리적 수명 제한(write endurance)이 있습니다.
AI 서버에서의 현재 역할
현재 AI 서버에서 NAND(SSD)는 모델 저장소 와 체크포인트 저장 역할을 합니다. 학습된 모델 가중치를 보관하고, 필요할 때 HBM으로 로드하는 “창고” 역할이죠.
하지만 연산 중에 직접 데이터를 공급하기에는 너무 느립니다. GPU가 데이터를 기다리는 시간이 연산 시간보다 길어지기 때문입니다.
용량은 넉넉하고 가격도 저렴하지만, 속도가 치명적으로 부족하다. NAND는 이 한계 안에 갇혀 있었습니다.
빈 자리 — HBM과 SSD 사이의 간극
지금까지 살펴본 메모리 계층을 한눈에 정리해 보겠습니다.
| SRAM | DRAM (DDR5) | HBM4 | ??? | NAND (SSD) | |
|---|---|---|---|---|---|
| 셀 구조 | 6T | 1T1C | 1T1C (TSV 적층) | 플로팅 게이트 | |
| 접근 지연 | ~1 ns | ~10-100 ns | ~10-100 ns | ~50-100 us | |
| 대역폭 (스택/모듈) | 수 TB/s (온칩) | ~50 GB/s | ~2 TB/s | ~7 GB/s | |
| 용량 | 수 MB-수십 MB | 수 GB-수십 GB | 36-48 GB | 수 TB | |
| 비트당 비용 | 매우 높음 | 중간 | 높음 | 매우 낮음 | |
| 휘발성 | 휘발성 | 휘발성 | 휘발성 | 비휘발성 |
표를 보면 한 가지가 눈에 들어옵니다.
HBM4는 스택당 최대 48GB, 8스택을 탑재해도 384GB입니다. SSD는 수 TB의 용량을 저렴하게 제공하지만, 대역폭이 7 GB/s 수준에 불과합니다.
HBM의 대역폭은 좋지만 용량이 부족하고, SSD는 용량은 넉넉하지만 너무 느리다.
물론 현 시점에 HBM의 용량은 상대적으로 큰 것은 맞지만, 사람들의 기대에 비해 부족하다는 의미입니다.
이 둘 사이에는 “TB 단위의 용량을 TB/s 단위의 대역폭으로 제공하는” 메모리가 존재하지 않습니다.
LLM의 파라미터가 수백 GB에서 수 TB로 커지고 있는 지금, 이 빈 자리를 채울 수 있다면 어떨까요?
HBF — NAND에 HBM의 옷을 입히다
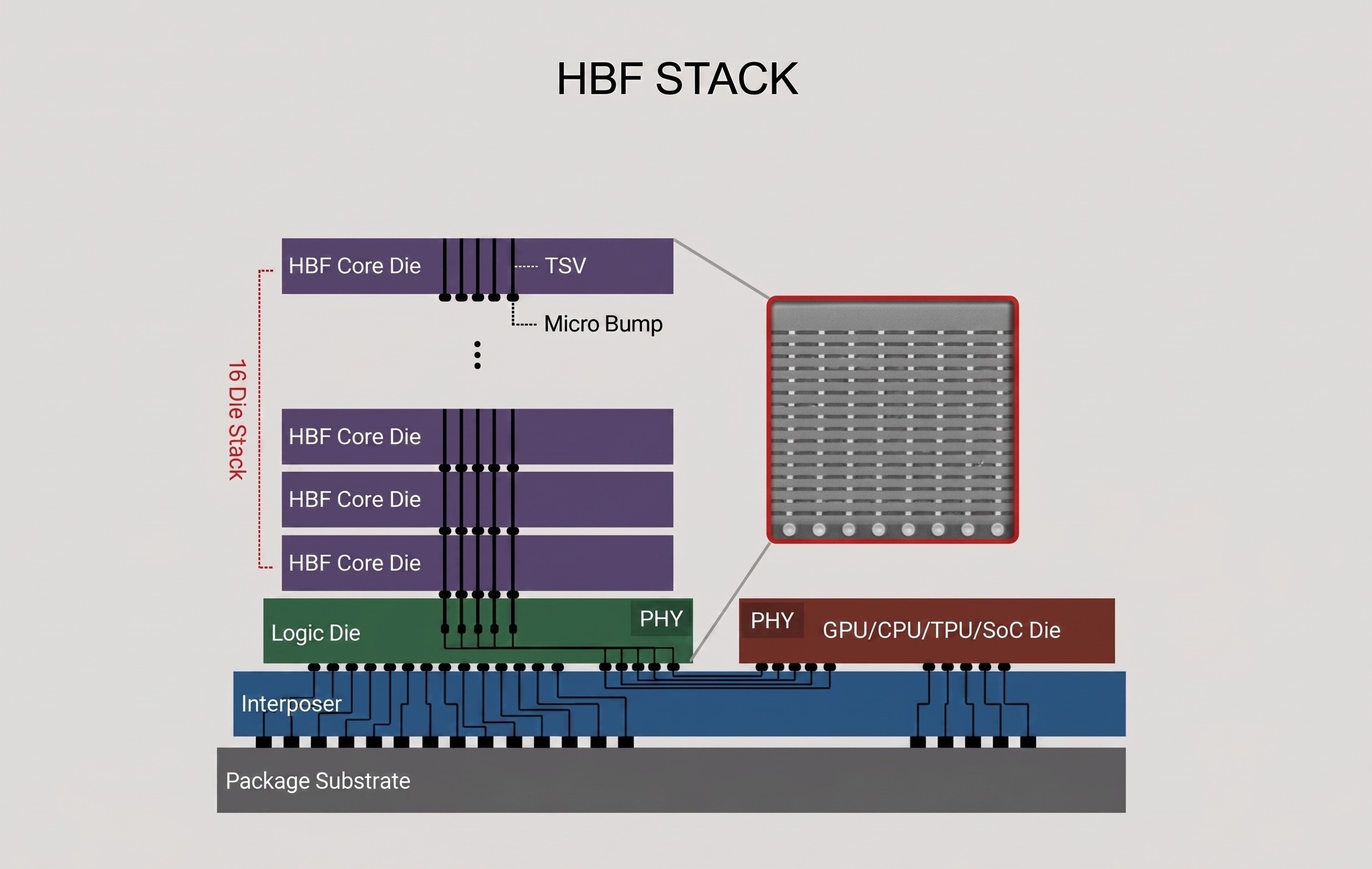
핵심 아이디어: 익숙한 셀, 새로운 패키징
High Bandwidth Flash(HBF) 는 NAND 셀은 그대로 두고, HBM에서 검증된 패키징 기술을 적용한 새로운 메모리 계층입니다.
앞서 HBM이 DRAM 셀을 바꾸지 않고 TSV 적층과 인터포저 배치만으로 대역폭을 혁신한 것을 보았습니다. HBF는 정확히 같은 전략을 NAND에 적용합니다.
NAND 다이를 TSV로 수직 적층하고, 인터포저 위에 GPU나 AI 가속기 바로 옆에 배치합니다. HBM이 DDR의 핀 수 한계를 패키징으로 돌파했듯, HBF는 SSD의 대역폭 한계를 패키징으로 돌파하는 것입니다.
CBA 아키텍처: NAND를 고대역폭에 최적화하다
HBF의 기술적 핵심은 SanDisk가 개발한 CMOS Bonding Array(CBA) 아키텍처입니다.
기존 NAND는 하나의 큰 메모리 배열에 순차적으로 접근하는 구조입니다. CBA는 이를 수천 개의 독립적인 스토리지 서브어레이 로 분할합니다. 각 서브어레이가 자체적인 읽기/쓰기 채널을 가지고 동시에 병렬로 작동 하므로, 단일 NAND 다이에서 나올 수 없던 수준의 대역폭을 끌어냅니다.
여기에 SanDisk의 BiCS NAND (3D 수직 적층 NAND) 기술이 결합됩니다. 수백 층으로 적층된 BiCS NAND 다이들을 TSV로 연결하고, CBA가 이 다이들의 서브어레이를 동시에 구동하는 구조입니다.
스펙으로 보는 HBF
| HBM4 | HBF Gen 1 | HBF Gen 2 | HBF Gen 3 | |
|---|---|---|---|---|
| 읽기 대역폭 | ~2 TB/s | 1.6 TB/s | >2 TB/s | >3.2 TB/s |
| 스택 용량 | 36-48 GB | 512 GB | 1 TB | 1.5 TB |
| 접근 지연 | ~10-100 ns | ~10 us | - | - |
| 셀 구조 | 1T1C DRAM | 플로팅 게이트 NAND | 플로팅 게이트 NAND | 플로팅 게이트 NAND |
주목할 숫자가 있습니다.
HBF Gen 1의 읽기 대역폭은 1.6 TB/s로, HBM4에 근접합니다. 그런데 용량은 512GB로, HBM4 스택(48GB)의 10배 가 넘습니다. HBM 대비 8-16배의 용량을 유사한 대역폭과 유사한 비용 으로 제공하는 것이 HBF의 핵심 가치입니다.
HBM 컨트롤러와의 호환성
HBF의 또 다른 강점은 물리적 footprint와 전기적 인터페이스(PHY 레벨)가 HBM과 호환 된다는 점입니다.
핀 배치, 패키지 크기, 전력 프로파일, 스택 높이까지 HBM4와 거의 동일하므로, 기존 HBM용 인터포저와 패키징 인프라를 그대로 재활용할 수 있습니다.
다만, HBF가 HBM의 drop-in 대체품은 아니라는 점 은 분명히 해둘 필요가 있습니다. NAND는 DRAM과 접근 단위(페이지 vs. 워드), 소거 사이클, wear-leveling 등의 특성이 다르기 때문에, 호스트 측 컨트롤러에는 최소한의 프로토콜 변경이 필요 합니다. SanDisk와 SK하이닉스가 추진 중인 오픈 표준도 “동일한 전기 인터페이스 + 최소한의 프로토콜 변경"을 지향점으로 두고 있습니다.
즉, 새로운 메모리 컨트롤러를 처음부터 설계할 필요는 없지만, 기존 HBM 컨트롤러를 그대로 쓸 수는 없습니다. 그래도 가속기 설계자 입장에서 채택 장벽이 크게 낮아진다는 점은 여전히 유효합니다.
HBF의 한계: 만능은 아니다
HBF는 빈 자리를 채우는 강력한 후보이지만, 한계도 명확합니다.
지연시간: 약 10us로, HBM의 수십-수백 ns 대비 약 100배 느립니다. NAND 셀의 읽기 메커니즘 자체가 DRAM보다 본질적으로 느리기 때문에, 패키징만으로는 이 격차를 완전히 해소할 수 없습니다.
쓰기 속도와 수명: NAND 특유의 느린 쓰기와 제한된 erase/write 사이클은 그대로 남아 있습니다. 이 때문에 HBF는 빈번한 쓰기가 필요한 AI 학습(training) 에는 적합하지 않습니다.
반대로, 한 번 로드한 모델 가중치를 반복적으로 읽기만 하는 AI 추론(inference) 워크로드에는 이러한 한계가 큰 문제가 되지 않습니다. HBF가 “AI 추론 시대의 메모리"로 주목받는 이유가 바로 여기에 있습니다.
마무리 & 다음 편 예고
이번 글에서는 메모리가 왜 여러 종류로 나뉘는지, 각 메모리의 셀 구조가 어떻게 속도/용량/비용의 트릴레마를 결정하는지를 살펴보았습니다.
정리하면 이렇습니다.
- SRAM: 6T 셀, 가장 빠르지만 가장 비싸고 작다
- DRAM: 1T1C 셀, 밀도 이점으로 메인 메모리를 담당하지만 대역폭에 한계가 있다
- HBM: DRAM 셀에 TSV + 인터포저 패키징을 적용하여 대역폭을 혁신했지만, 용량 확장이 어렵다
- NAND: 극한의 밀도와 낮은 가격이지만, 너무 느려서 연산에 직접 참여하지 못한다
- HBF: NAND 셀에 HBM의 패키징을 적용하여, HBM과 SSD 사이의 빈 자리를 채우는 새로운 계층
그런데 빈 자리를 채울 수 있다는 것만으로는 이야기가 완성되지 않습니다.
HBF는 HBM 대비 약 100배 긴 지연시간(약 10us)이라는 약점을 가지고 있습니다. 그렇다면 이 약점을 어떻게 극복하고, HBF를 실제 LLM 워크로드에 활용할 수 있을까요?
다음 편에서는 HBF가 LLM에서 어떻게 활용될 수 있을지, 그리고 SK하이닉스가 제안한 long latency 극복 방안을 중심으로 알아보겠습니다.
다음 편은 HyperAccel의 Jaewon Lim 님이 작성해 주실 예정입니다. 많은 관심 부탁드립니다!
추신
저는 HyperAccel에서 LLM 가속 ASIC 칩 출시를 위해 RTL을 설계하고 있습니다. 메모리 대역폭이라는 한정된 자원을 최대한 활용해서 최고의 성능을 내기 위해서 많은 사람들이 함께 머리를 맞대고 더 효율적인 활용법을 고민하고 있습니다. 이 시리즈를 통해 메모리 기술의 흐름을 함께 이해하고, 앞으로의 변화를 함께 지켜볼 수 있으면 좋겠습니다.
HyperAccel은 HW, SW, AI를 모두 다루는 회사로, 전 방면에 걸쳐 뛰어난 인재들이 모여 있습니다. 폭넓은 지식을 깊게 배우며 함께 성장하고 싶으신 분들은 언제든지 지원해 주세요!
채용 사이트: https://hyperaccel.career.greetinghr.com/ko/guide
Reference
- SanDisk HBF Fact Sheet
- Scaling the Memory Wall: Behind Sandisk’s High Bandwidth Flash for AI Inferencing
- SK hynix and Sandisk Begin Global Standardization of Next-Generation Memory ‘HBF’
- SK Hynix Unveils AI Chip Architecture with HBF
- HBM VS HBF VS HBS: Building the Memory Hierarchy for AI
- High Bandwidth Flash: NAND’s Bid for AI Memory
- HBF: A High-Bandwidth Flash New Star Breaking the “Memory Wall” for AI
- High Bandwidth Flash is years away despite its promise
- SK hynix and SanDisk announce new High Bandwidth Flash — Tom’s Hardware
- HBM roadmaps for Micron, Samsung, and SK hynix: To HBM4 and beyond
- The State of HBM4 Chronicled at CES 2026