
SGLang의 철학
LLM이 도입된 이후, LLM은 문제 해결, 코드 작성, 질문 답변 등 다양한 분야에서 복잡한 작업을 해결하는 데 사용되어 왔습니다. 오늘날 LLM은 에이전트 능력을 확장하여 인간의 개입 없이 사용자가 요청한 작업을 완료하고 있습니다.
이를 위해서는 skeleton of thought나 tree of thought와 같은 다양한 프롬프팅 기법이 필요합니다. 즉, 우리는 LLM이 특정 패턴을 따르도록 구조화하여 우리의 요구에 맞추고, 요구사항을 충족하도록 제어하고 안내하기 위한 프로그래밍 가능성을 필요로 합니다.
저자들은 현재 솔루션에서 이 과정이 비효율적이었다고 주장하며, 그 이유는 다음과 같습니다:
- LLM이 non-deterministic 하기 때문에 LM(Language Model) 프로그램을 프로그래밍하기 어렵습니다.
- 명령을 실행하기 전에 LLM이 무엇을 출력할지 예측할 수 없습니다.
- 이는 LLM 출력의 가독성을 떨어뜨립니다.
- 중복된 계산과 메모리 사용으로 인해 LM 프로그램 실행이 비효율적입니다.
- 현재 솔루션 (논문 작성 당시 TGI, vLLM등을 의미)은 KV-cache를 재사용하는 효과적인 메커니즘이 부족합니다.
- 출력 형식이 고정되어 있거나 특정 문법 규칙을 따를 때, 현재 솔루션은 항상 토큰을 하나씩 출력하기 때문에 이를 효과적으로 활용할 수 없습니다.
SGLang의 핵심 아이디어는 컴파일 가능한 새로운 python DSL(Python-embedded DSL)을 개발하여 AI 프로그램을 구조로 단순화하는 것입니다.
SGLang DSL
논문에서 가져온 SGLang DSL 예제입니다.
이미지에 대한 에세이를 평가하는 AI 프로그램을 만들고 싶다고 가정해봅시다.
우리 시스템이 수행해야 할 작업은 다음과 같습니다:
- 에세이와 이미지를 읽고, 에세이가 이미지에 관한 것인지 판단합니다. 그렇지 않으면 종료합니다.
- 에세이가 이미지와 일치하는 경우, 여러 차원(명확성, 문법, 가독성, 구조 등)에서 평가합니다.
- 이러한 평가를 기반으로 A+부터 D-까지의 점수를 부여합니다.
- 등급과 점수을 JSON 형식으로 출력합니다.
이 과정은 SGLang DSL로 다음과 같이 설명할 수 있습니다.
@function
def multi_dimensional_judge(s, path, essay):
s += system("Evaluate an essay about an image.")
s += user(image(path) + "Essay:" + essay)
s += assistant("Sure!")
# Return directly if it is not related
s += user("Is the essay related to the image?")
s += assistant(select("related", choices=["yes", "no"]))
if s["related"] == "no":
return
# Judge multiple dimensions in parallel
forks = s.fork(len(dimensions))
for f, dim in zip(forks, dimensions):
f += user("Evaluate based on the following dimension:" + dim + ". End your judgment with the word 'END'")
f += assistant("Judgment:" + gen("judgment", stop="END"))
# Fetch the judgement results & merge the judgments
judgment = "\n".join(f["judgment"] for f in forks)
# Generate a summary and a grade. Return in the JSON format.
s += user("Provide the judgment, summary, and a letter grade")
s += assistant(judgment + "In summary," + gen("summary", stop=".") + "The grade of it is" + gen("grade"))
schema = r'\{"summary": "[\w\d\s]+\.", "grade": "[ABCD][+-]?"\}'
s += user("Return in the JSON format.")
# Runtime optimize for fast constrained decoding with regex
s += assistant(gen("output", regex=schema))
state = multi_dimensional_judge.run(...)
print(state["output"]) # Runs an SGLang program
SGLang를 사용하면 LM 프로그램을 간단히 작성할 수 있으며, 이전 솔루션보다 훨씬 짧습니다.
프로그램에서 fork, join, regex 등의 SGLang 의 primitive를 관찰할 수 있습니다.
fork는 여러 차원에서 에세이를 판단하기 위한 여러 요청을 생성하며(에세이를 다른 기준을 가지고 판단), join은 모든 판단을 하나로 모읍니다. regex는 정규 표현식을 받아들이며, LLM의 출력을 특정 형식으로 제한할 수 있습니다. += 연산자는 문자열을 추가하는 데 사용됩니다.
일부 표현들은 select, gen, extend SGLang이 asynchronous stream에서 명령을 실행되도록 지시합니다. 저자들은 이를 CUDA stream과 함께 CUDA kernel을 비동기적으로 실행하는 것으로 볼 수 있다고 언급합니다.
RadixAttention
SGLang는 RadixAttention이라는 KV cache 관리 기법을 도입합니다. 이 알고리즘은 radix tree를 사용하여 SGLang DSL 컨텍스트에서 KV cache를 효율적으로 관리합니다. (참고: radix tree는 parent 노드의 유일한 child 노드가 있을 경우 parent 노드와 병합되어 공간을 절약하는 트리입니다.) 알고리즘은 간단합니다. 프롬프트를 트리로 유지하며, 다른 프롬프트나 답변이 주어질 때 분기합니다. 실행 중인 요청이 사용하지 않을 때 LRU(Least Recently Used) 정책을 사용하여 leaf 노드를 제거합니다.
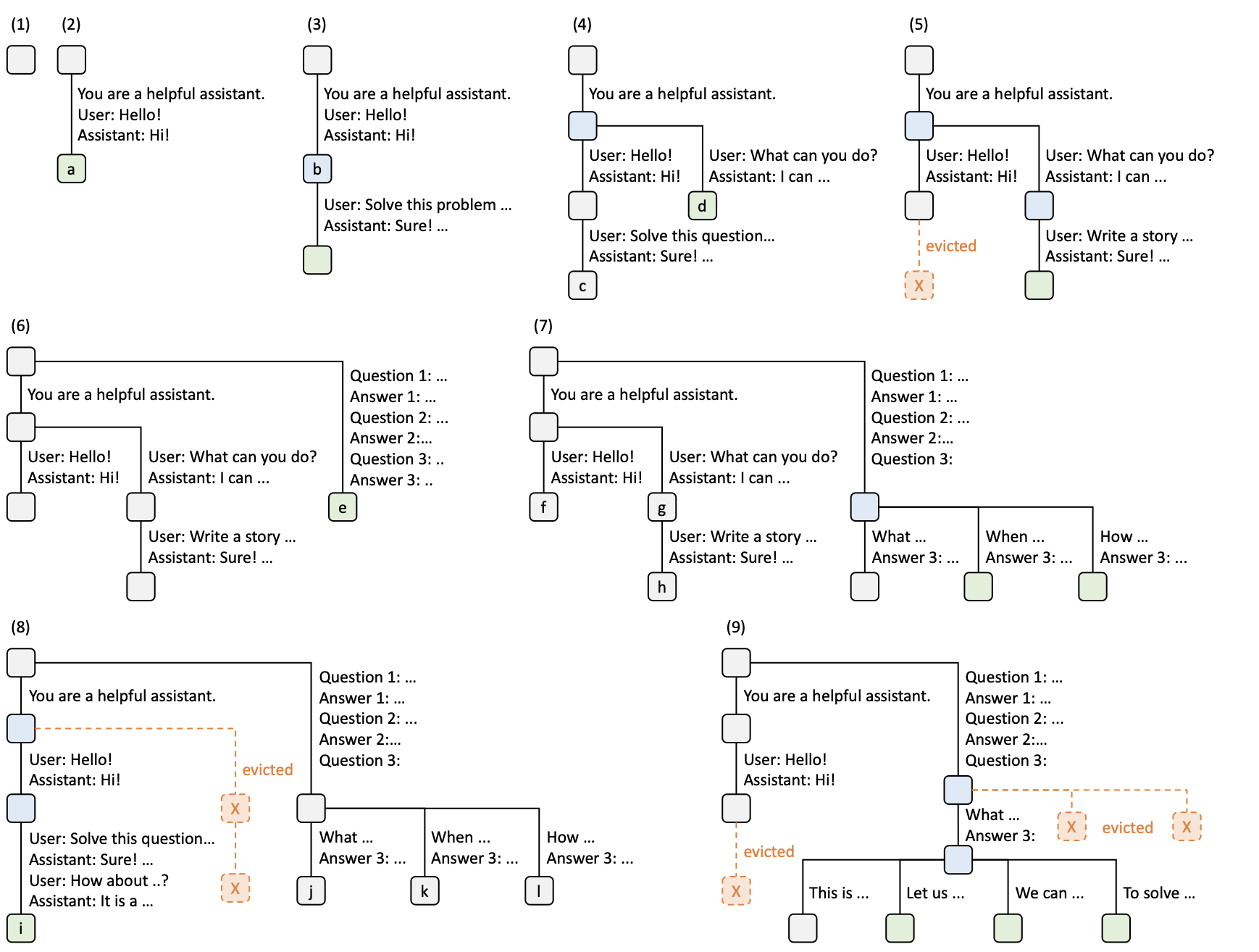
여러 가능한 컨텍스트를 표현할 수 있는 radix tree의 예입니다. 이것은 자연스럽게 프롬프트의 여러 상태를 나타내며, 새로운 요청이 트리에 저장된 노드와 일치할 때 이전의 모든 KV cache를 재사용합니다.
실행 과정
- 트리가 비어 있습니다
- “Hello” 요청이 수락되고, LLM이 “Hi"라고 답변합니다. 이 시퀀스는 새로운 노드
a로 저장됩니다. - 새로운 요청(“Solve this problem”)이 도착하고, 대화가 일치합니다. KV cache를 안전하게 재사용할 수 있습니다.
- 또 다른 요청이 도착합니다. 요청은 “You are a helpful assistant”(시스템 프롬프트)까지 일치하지만, 사용자가 “hello"를 말하지 않았기 때문에 트리를 분기해야 합니다.
- 메모리 제한으로 인해 가장 최근에 사용되지 않은 노드 하나를 제거합니다.
- 새로운 요청이 도착하지만, 이전 시스템 프롬프트를 사용하지 않았습니다. 따라서 루트에서 분기합니다.
- 더 많은 쿼리가 들어오지만, 시스템 프롬프트가 없는 이전 요청과 동일한 프롬프트를 공유하므로 마지막 노드에서 분기합니다.
- “Hello"와 “Hi!” 이후에 새로운 메시지를 받으므로 새 노드를 추가합니다. 그러나 KV cache 공간이 부족하여 다른 가장 최근에 사용되지 않은 노드를 제거합니다.
- 이제 “Answer 3"까지 동일한 프롬프트를 공유하는 더 많은 요청이 있지만, 충분한 공간을 확보할 때까지 다른 노드를 제거해야 합니다. LRU 정책을 사용하여 제거합니다.
여기까지 읽으셨다면, 요청 순서가 최적이 아니어서 캐시 성능이 저하되면 어떻게 될까 궁금하실 수 있습니다. 저자들도 이를 고려했습니다. 성능을 최대화하기 위한 cache의 성능을 염두한 스케줄링 알고리즘 을 설계했습니다. 이 알고리즘은 radix-tree KV cache와 가장 잘 일치하는 접두사 길이로 요청을 정렬합니다(본질적으로 들어오는 요청을 처리하기 전에 캐시 적중률을 미리 예상합니다).
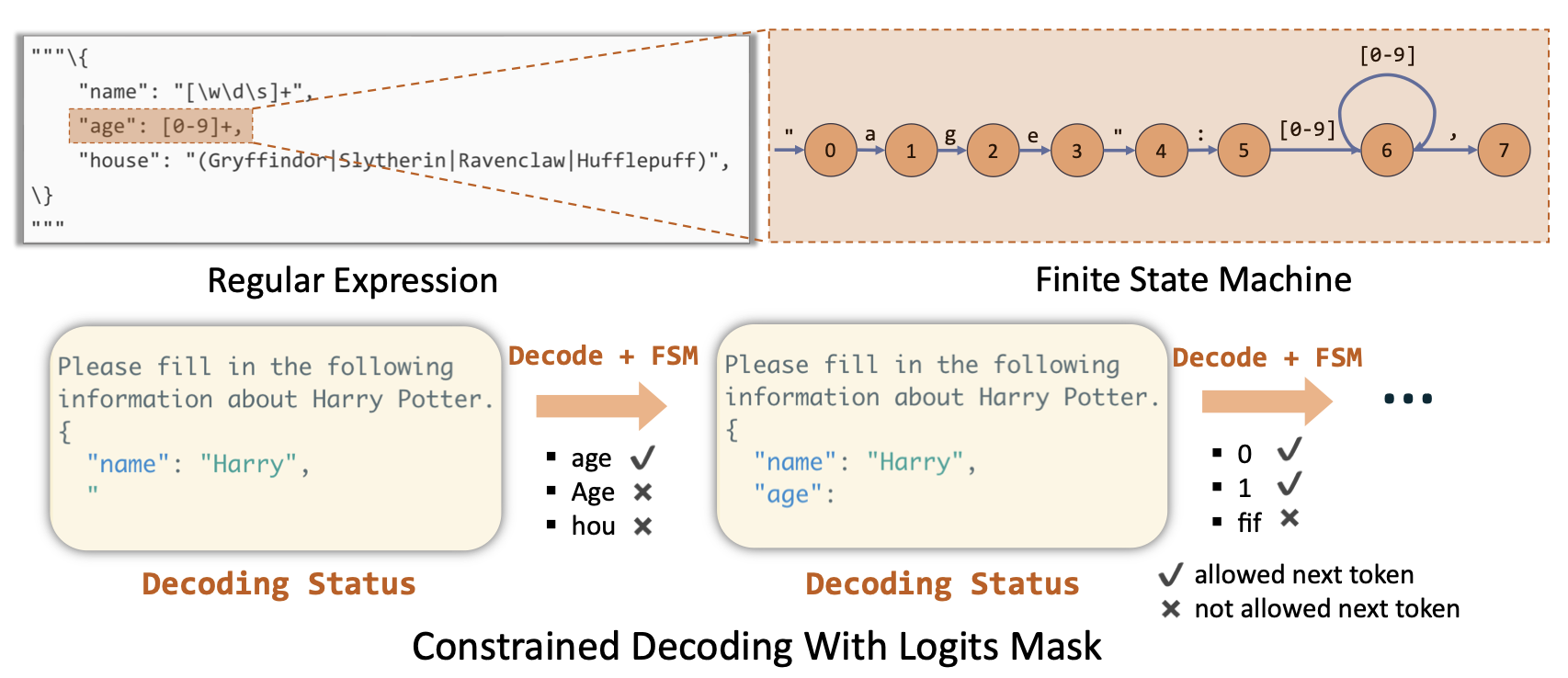
Compressed FSM(Finite state machine) 을 사용한 constrained decoding
일부 LM 프로그램은 특정 형식(예제의 JSON과 같은)의 출력이 필요합니다. 프레젠테이션 슬라이드를 생성하는 LM 프로그램을 구축하는 경우, LLM 출력이 특정 형식을 따르기를 원합니다. SGLang는 FSM을 사용하여 이를 효율적으로 지원합니다.
디코딩 중에 올바른 LLM 출력이 때때로 항상 고정되어 있습니다. 예를 들어, LLM이 JSON을 출력하도록 프롬프트되면, 콜론, 쉼표 또는 중괄호를 언제 출력해야 하는지 항상 알고 있습니다—이는 SGLang DSL에서 regex로 표현할 수 있습니다.
예: 위 그림에서 “Harry"를 출력하기 전에 {\n "name": }를 출력해야 한다는 것을 항상 알고 있습니다.
regex의 문제는 문자 및 문자열 수준에서 정의되어 LLM 토큰과 일치하지 않는다는 것입니다. 따라서 LLM이 작은 토큰을 하나씩 출력하도록 만들어야 합니다.
예: LLM이 {, \n, "를 하나씩 디코딩하는데, 이는 매우 비효율적입니다.
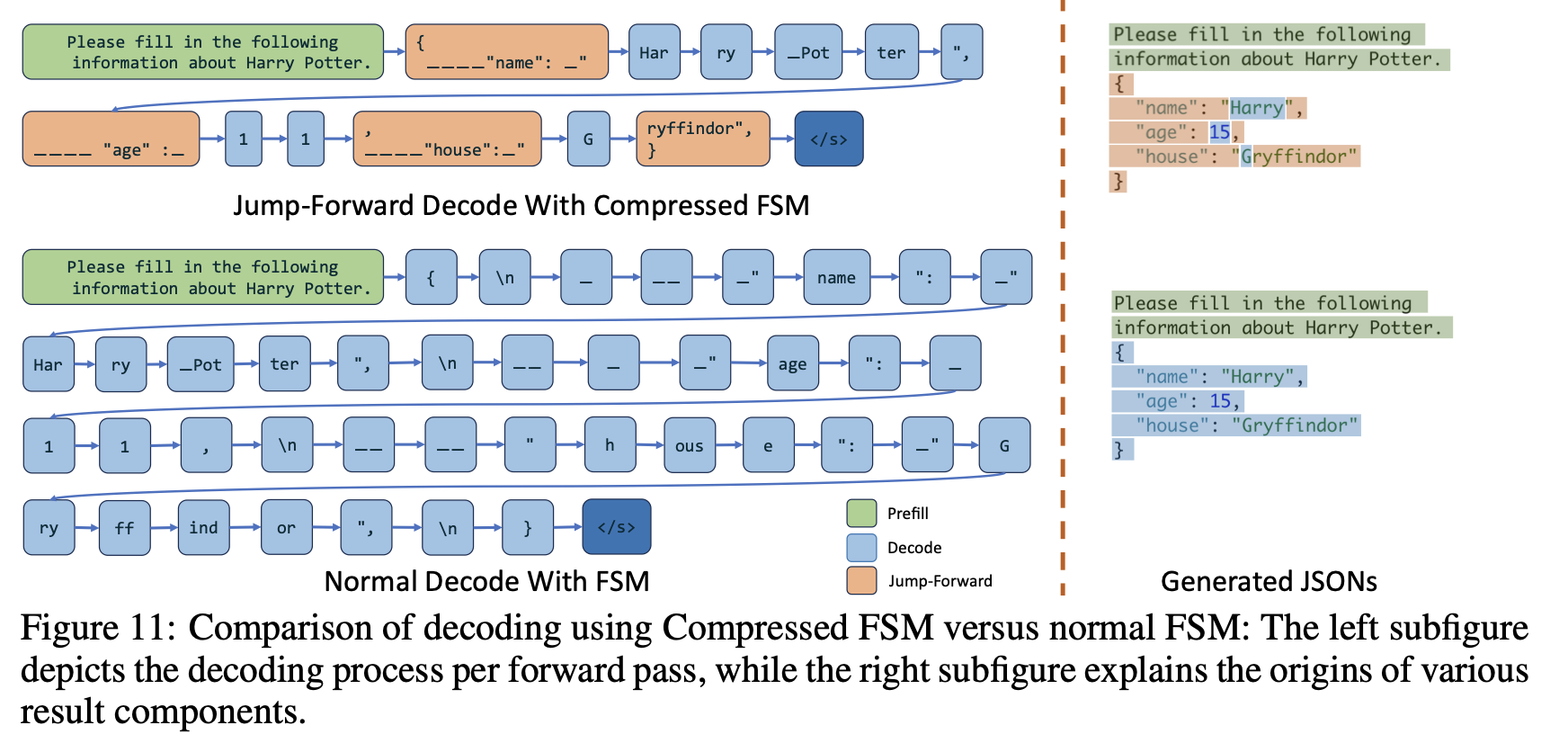
그러나 SGLang는 이러한 시퀀스를 re-tokenize 하여 변하지 않는 expression들의 리스트를 단일 expression 으로 “압축"할 수 있습니다. FSM은 어떤 압축된 토큰을 출력할지 추적하여, SGLang이 여러 expression을 한 번에 점프하고 LLM이 불피요한 토큰들을 추론하는 것을 방지하여 디코딩 과정을 가속화할 수 있게 합니다.
위 예제에서 { \n ____ "name"는 한 변에 표현할 수 있습니다. 해당 부분을 완전히 디코딩하는 것을 건너뛰고 단순히 붙여넣을 수 있어, LLM이 다음 출력으로 직접 진행할 수 있습니다.
평가
SGLang는 추론 컨텍스트 인식 KV-cache 메커니즘으로 인해 에이전트 기반 AI 워크로드에서 매우 효과적이며, 이는 미래의 대부분의 추론 워크로드가 될 것으로 예상합니다.
성능 향상은 Radix attention과 FSM(Finite state machine) 기반 디코딩에서 비롯됩니다. 논문 저자들에 따르면 최고 성능을 보인 DsPy RAG 파이프라인에서 캐시 적중률이 50-90% 사이였다고 합니다.
개인적인 생각
우리는 agentic AI의 세계에 살고 있으며, agentic AI 의 사용 분야는 갈수록 확장되고 있습니다. AI 워크로드는 코딩, 슬라이드 생성, 음악 생성, 작업 도구 등 다양한 서비스에 통합되고 있습니다. 이러한 워크로드는 모델을 제어하기 위해 많은 시스템 프롬프트와 출력 제약이 필요합니다. 저는 개인적으로 SGLang가 radix attention과 정말 잘 맞기 때문에 이러한 경우에 매우 효율적일 것이라고 생각합니다. 또한 토큰을 생성할 필요가 없을 때 regex와 함께 FSM을 사용하여 시간과 에너지를 절약하는 아이디어를 좋아했습니다. SGLang이 항상 vLLM보다 나은 것은 아니지만, 에이전트 AI 워크로드에 훨씬 더 적합하지 않을까 생각합니다.
Reference
SGLang: Efficient Execution of Structured Language Model Programs