
AITER 분석: AMD가 ROCm inference 성능을 2배로 올린 방법
안녕하세요? HyperAccel ML팀 소속 박민호입니다.
Semi Analysis 는 반도체 업계에서 유명한 리서치 기관입니다. 이 기관은 주요 GPU 의 inference 성능을 실측 비교하는 InferenceX 벤치마크를 운영하고 있습니다.
2026년 2월에 공개된 InferenceX v2 보고서에 따르면, AMD MI300X 의 SGLang throughput 성능이 2025년 12월에서 2026년 1월 사이 거의 2배 가까이 향상되었다고 합니다. 이 성능 향상의 중심에 AI Tensor Engine for ROCm(AITER) 이라는 커널 라이브러리가 있었습니다.

저는 이 소식을 접하고 궁금해졌습니다. 도대체 AITER 가 뭐길래, 소프트웨어 최적화만으로 하드웨어의 성능을 2배나 끌어올릴 수 있었을까? 이번 포스트에서는 AITER 의 아키텍처, 커널 백엔드 전략, 그리고 성능 향상의 원리를 정리해 봤습니다. 아래 목록에 해당되는 분들께 도움이 될 것 같습니다:
- AMD GPU 의 inference 성능 현황이 궁금하신 분
- GPU 커널 최적화 기법에 관심이 있으신 분
- NVIDIA 외의 AI 가속기 생태계가 궁금하신 분
AITER란 무엇인가?
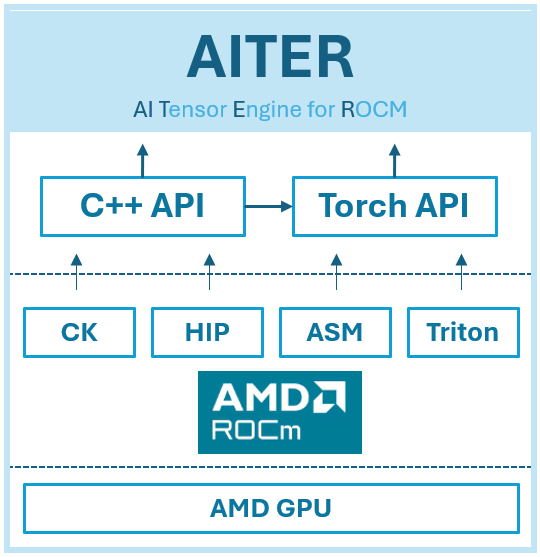
AI Tensor Engine for ROCm(AITER) 는 AMD 가 공개한 고성능 AI operator 통합 저장소입니다. 한 마디로 요약하면 AMD GPU 에서 AI 워크로드를 가속하기 위한 커널 모음집 입니다. NVIDIA 생태계에서 cuDNN 이 하는 역할을 ROCm 생태계에서 AITER 가 수행한다고 보면 됩니다.
| 항목 | 내용 |
|---|---|
| 저장소 | ROCm/aiter |
| 라이선스 | MIT |
| 언어 구성 | Python (63.6%), CUDA/HIP (25.8%), C++ (9.7%) |
| 지원 GPU | AMD Instinct MI300X, MI325X, MI350 |
| Inference Framework | vLLM, SGLang |
AITER 의 핵심 가치는 드롭인 교체 에 있습니다. vLLM 이나 SGLang 같은 inference framework에서 환경 변수 하나만 켜면 기존 operator가 AITER 의 최적화된 커널로 자동 교체됩니다. 코드 수정 없이 성능 향상을 얻을 수 있다는 뜻입니다.
어떤 operation을 지원하는가?
AITER 는 Large Language Model(LLM) inference 의 핵심 operation을 폭넓게 지원합니다.
| 카테고리 | operation | 백엔드 |
|---|---|---|
| Attention | Flash Attention, Multi-head Latent Attention(MLA), Paged Attention | CK, ASM, Triton |
| Fused MoE | Top-K routing, MoE sorting, BlockScale FP8 FFN | HIP, CK, ASM |
| GEMM | FP8 per-token/channel, block-scale FP8, INT8, pre-shuffle | CK, ASM |
| Normalization | RMSNorm, LayerNorm (fused quantization 포함) | Triton, CK |
| Embedding | Rotary Position Embedding(RoPE) forward/backward | Triton |
| Quantization | BF16/FP16 → FP8/INT4 변환 | CK, Triton |
| Communication | AllReduce, reduce-scatter, all-gather | Triton, HIP |
여기서 눈에 띄는 것은 백엔드 열입니다. 하나의 operation에도 CK, ASM, Triton 등 여러 백엔드가 병기되어 있습니다. 이것이 AITER 의 핵심 설계 철학인 멀티 백엔드 전략 입니다. 이에 대해서는 뒤에서 자세히 다루겠습니다.
성능 벤치마크: 숫자로 보는 AITER
백문이 불여일견이라고 하죠. AITER 가 MI300X 에서 달성한 성능 향상 수치를 먼저 보겠습니다.
| 커널/워크로드 | Throughput 향상 |
|---|---|
| Block-scale General Matrix Multiplication(GEMM) | 2배 |
| Block-scale Fused Mixture of Experts(MoE) | 3배 |
| MLA Decode | 17배 |
| Multi-Head Attention(MHA) Prefill | 14배 |
| DeepSeek V3/R1 throughput (SGLang 기준) | 2배 (6,485 → 13,704 tok/s) |
| DeepSeek R1 prefill latency | ↓52% (3.13s → 1.51s) |
| DeepSeek R1 decode latency | ↓47% (0.053s → 0.028s) |
| NVIDIA H200 대비 (DeepSeek R1) | 동일 latency에서 2-5배 높은 throughput |
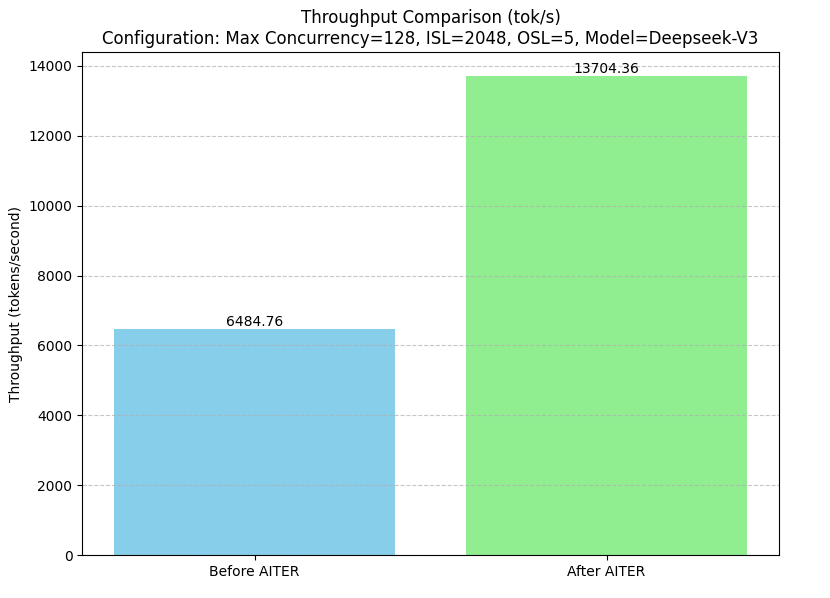
MLA Decode 17배, MHA Prefill 14배는 단순한 튜닝으로 나올 수 있는 수치가 아닙니다. AITER 가 어셈블리 수준까지 내려가서 커널을 직접 작성했기 때문에 가능한 결과입니다.
아키텍처 구조
상위 레벨 아키텍처
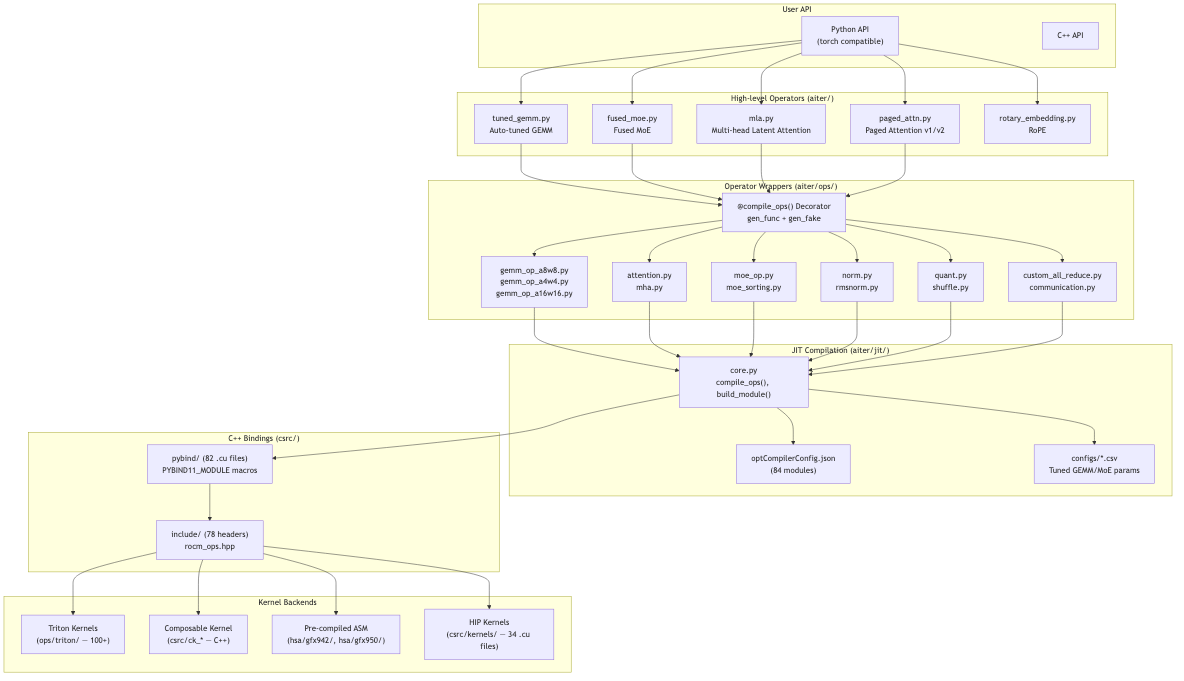
AITER 의 아키텍처는 크게 5개 계층으로 구성됩니다.
- 사용자 API: Python(torch 호환) 및 C++ API
- 상위 레벨 operator:
tuned_gemm.py,fused_moe.py,mla.py등 operator 오케스트레이터 - operator 래퍼:
@compile_ops데코레이터 기반의 operator 래핑 계층 - JIT 컴파일: 첫 호출 시 커널을 컴파일하고
.so파일로 캐시 - 커널 백엔드: Triton, Composable Kernel(CK), HIP, ASM 4가지 백엔드
사용자 입장에서는 import aiter 로 PyTorch 호환 함수를 호출하면 됩니다. 나머지는 AITER 가 알아서 최적의 커널을 선택하고, 컴파일하고, 캐싱합니다.
JIT 컴파일 파이프라인
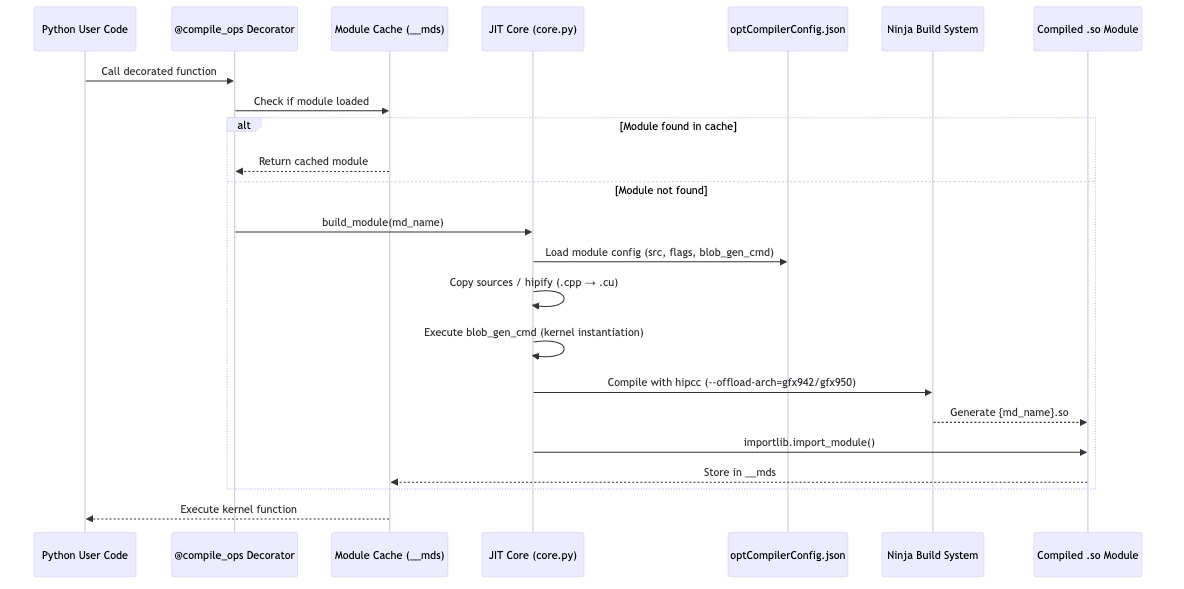
AITER 의 모든 operator는 @compile_ops 데코레이터 패턴을 따릅니다.
@compile_ops("module_gemm_a8w8", fc_name="gemm_a8w8",
gen_func=cmdGenFunc, gen_fake=fake_shape_fn)
def gemm_a8w8(XQ, WQ, x_scale, w_scale, Out):
... # 본문은 실행되지 않음 — 런타임에 컴파일된 C++로 대체
이 패턴의 동작 원리는 다음과 같습니다.
- Python 코드에서 데코레이터 함수를 호출합니다
- 모듈 캐시에서 이미 컴파일된
.so파일이 있는지 확인합니다 - 없으면
optCompilerConfig.json에서 모듈 설정을 로드합니다 hipcc로 컴파일하고 Ninja 빌드 시스템으로.so를 생성합니다importlib.import_module()로 로드하여 캐시에 저장합니다- 이후 호출에서는 캐시된 커널을 바로 사용합니다
첫 실행 시에만 컴파일 비용이 발생하고, 이후에는 네이티브 수준의 성능을 얻습니다. 84개의 컴파일 모듈이 이 방식으로 관리됩니다.
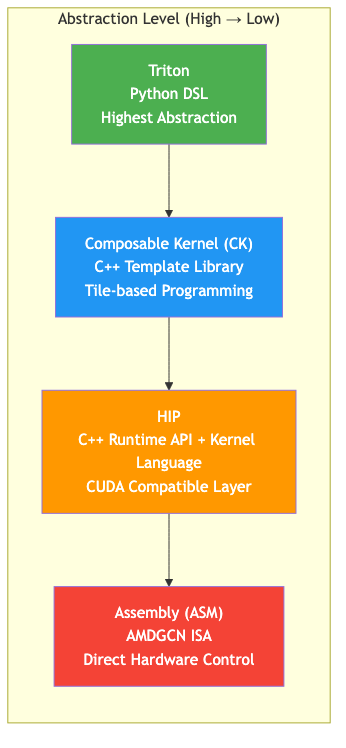
4가지 커널 백엔드
AITER 의 특징은 하나의 커널 언어를 고집하지 않는다 는 점입니다. operator 특성에 따라 4가지 백엔드를 골라 씁니다.
Triton
Triton 은 OpenAI 가 개발하고 AMD 가 ROCm 용으로 포팅한 Python 기반 GPU 프로그래밍 Domain-Specific Language(DSL) 입니다. 블록 단위 프로그래밍 모델로, 개발자가 타일 수준에서 알고리즘을 작성하면 컴파일러가 자동으로 최적화합니다.
AITER 에서 가장 많은 커널(100개 이상) 이 Triton 으로 작성되었습니다. RMSNorm, RoPE, quantization, MoE sorting 등 유틸리티성 operation에 주로 사용됩니다.
# Triton RMSNorm 커널 예시
@triton.jit
def _rms_norm_fwd_kernel(
X_ptr, W_ptr, Out_ptr,
stride_x_row, N, eps,
BLOCK_N: tl.constexpr,
):
row_idx = tl.program_id(0) # 각 프로그램이 하나의 행 처리
cols = tl.arange(0, BLOCK_N)
mask = cols < N
x = tl.load(X_ptr + row_idx * stride_x_row + cols, mask=mask, other=0.0)
x_sq = x * x
mean_sq = tl.sum(x_sq, axis=0) / N
rrms = tl.rsqrt(mean_sq + eps) # reciprocal square root
w = tl.load(W_ptr + cols, mask=mask)
out = x * rrms * w
tl.store(Out_ptr + row_idx * stride_x_row + cols, out, mask=mask)
Triton 의 강점은 개발 속도입니다. Python 문법으로 GPU 커널을 작성할 수 있고, 메모리 coalescing 이나 shared memory 관리를 컴파일러가 자동 처리합니다. 반면 컴파일러의 한계로 이론 대역폭의 95% 이상에 도달하기는 어렵습니다.
Composable Kernel(CK)
CK 는 AMD 가 개발한 C++ 템플릿 기반 고성능 커널 라이브러리입니다. NVIDIA 의 CUTLASS 와 유사한 위치에 있습니다. “조합 가능한 커널” 이라는 이름처럼, 재사용 가능한 타일 operation 빌딩 블록을 조합하여 복잡한 operator를 만듭니다.
CK 의 핵심은 operation fusion 입니다. 예를 들어 GEMM 결과에 스케일링을 별도 커널 없이 인라인으로 fusion할 수 있습니다.
// GEMM 결과에 dequantization를 인라인으로 fusion
template <typename AccDataType, typename DDataType, typename EDataType>
struct RowwiseScale {
__host__ __device__ constexpr void operator()(
EDataType &e, const AccDataType &c,
const DDataType &d0, // weight 스케일
const DDataType &d1 // activation scale
) const {
const F32 x = ck::type_convert<F32>(c)
* ck::type_convert<F32>(d0)
* ck::type_convert<F32>(d1);
e = ck::type_convert<EDataType>(x);
}
};
// → GEMM 계산 + dequantization가 하나의 커널에서 수행됩니다
AITER 에서는 GEMM(A8W8, A4W4, block-scale), MoE 2-stage, 일부 Attention 등 matrix operation 중심 커널에 CK 를 사용합니다. M, N, K 형상에 따라 100개 이상의 pre-tuned된 인스턴스 중 최적의 것을 선택하는 휴리스틱 디스패치도 구현되어 있습니다.
HIP
Heterogeneous-computing Interface for Portability(HIP) 는 AMD 의 C++ 런타임 API 이자 커널 언어입니다. CUDA 의 AMD 대응물로, 대부분의 CUDA 커널 코드가 이름만 바꾸면 HIP 에서 동작합니다.
CUDA 개념 → HIP 대응물
─────────────────────────────────────────
cudaMalloc() → hipMalloc()
cudaMemcpy() → hipMemcpy()
__global__ void kernel → __global__ void kernel (동일!)
__shared__ → __shared__ (동일!)
cudaStream_t → hipStream_t
nvcc → hipcc
AITER 에서는 Paged Attention, KV 캐시, TopK, AllReduce 등 general-purpose operation에 HIP 를 사용합니다. csrc/kernels/ 디렉토리에 34개의 .cu 파일이 이 방식으로 작성되어 있습니다.
Assembly(ASM)
ASM 백엔드는 AMD GPU 의 machine code인 AMDGCN Instruction Set Architecture(ISA) 로 직접 작성된 커널입니다. 컴파일러의 모든 추상화를 우회하고 GPU 레지스터, instruction scheduling, 메모리 접근 패턴을 개발자가 100% 제어합니다.
왜 여기까지 내려가야 할까요? 고수준 컴파일러는 안전한 코드를 생성하는 대신 최적화 기회를 놓칩니다. ASM 은 GPU 의 Matrix Fused Multiply-Add(MFMA) instruction, 특수 레지스터, instruction pipelining을 100% 활용할 수 있습니다. 그 결과가 MLA Decode 17배, MHA Prefill 14배 향상입니다.
레지스터 타입:
SGPR (Scalar GPR) — control flow, constant (모든 스레드 공유)
VGPR (Vector GPR) — 데이터 operation (각 스레드별 독립 값)
AccVGPR — MFMA accumulator (matrix multiplication 결과 저장)
핵심 instruction:
v_mfma_f32_32x32x8_f16 — 32×32 matrix multiplication (FP16→FP32)
v_mfma_f32_16x16x32_fp8 — 16×16 matrix multiplication (FP8→FP32)
buffer_load_dwordx4 — Global 메모리에서 128비트 로드
ds_read_b128 — LDS에서 128비트 로드
AITER 의 hsa/ 디렉토리에는 354개 이상의 사전 컴파일된 ASM 커널(.co 파일) 이 있습니다. 이렇게 많은 인스턴스가 필요한 이유는 ASM 커널은 컴파일 타임에 모든 파라미터가 고정되기 때문입니다. 런타임 분기 없이 모든 가능한 조합을 사전 컴파일합니다.
head_dim: {64, 128, 256} → 3가지
dtype: {fp16, bf16, fp8} → 3가지
causal: {true, false} → 2가지
→ 조합 폭발 → 162개+ FMHA 인스턴스
백엔드 선택 기준
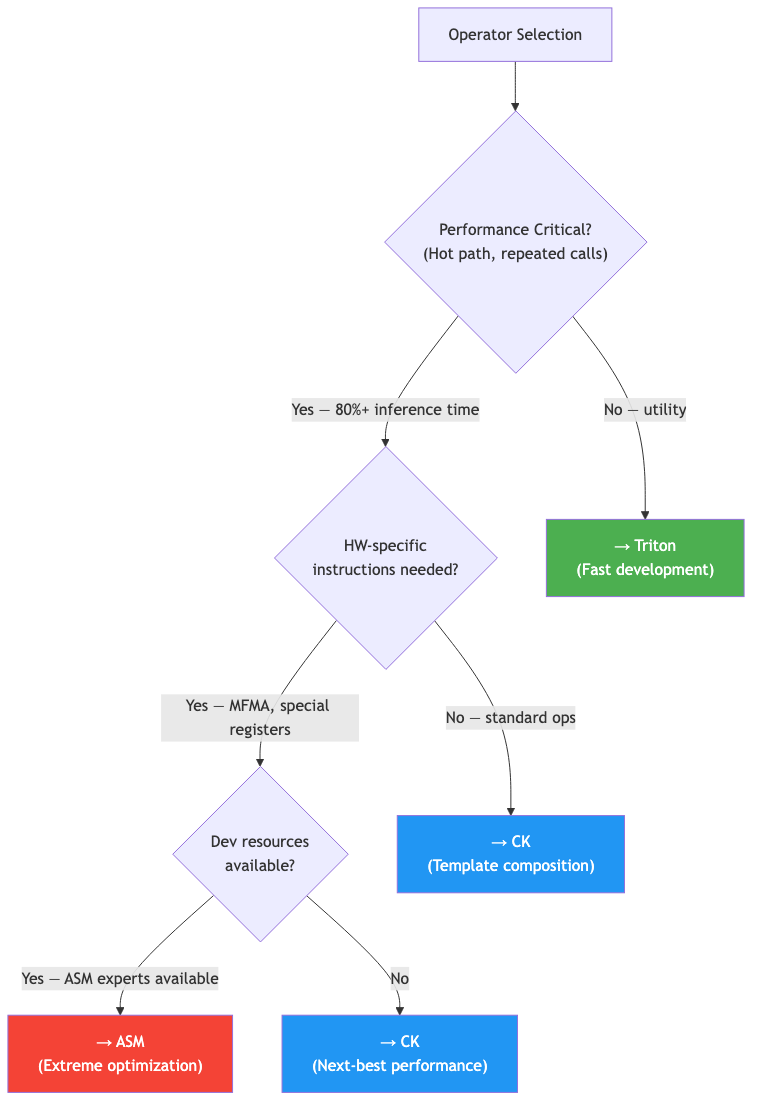
AITER 가 각 operation에 특정 백엔드를 선택하는 기준을 정리하면 다음과 같습니다.
| 기준 | Triton | CK | HIP | ASM |
|---|---|---|---|---|
| 개발 속도 | ★★★★★ | ★★☆☆☆ | ★★★☆☆ | ★☆☆☆☆ |
| 최대 성능 | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | ★★★★★ |
| 이식성 | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★☆☆☆☆ |
| 유지보수 | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★☆☆☆☆ |
| 커널 수 | 100+ | ~20 | 34 | 354+ (.co) |
“그러면 다 ASM 으로 짜면 되지 않나?” 라고 생각할 수 있는데, ASM 은 개발 난이도가 매우 높고 GPU 아키텍처가 바뀌면 처음부터 다시 작성해야 합니다. AITER 는 성능이 가장 중요한 핫 패스에만 ASM 을 쓰고, 나머지는 Triton 이나 CK 로 개발 효율을 확보합니다.
Framework Integration: 환경 변수 하나로 활성화
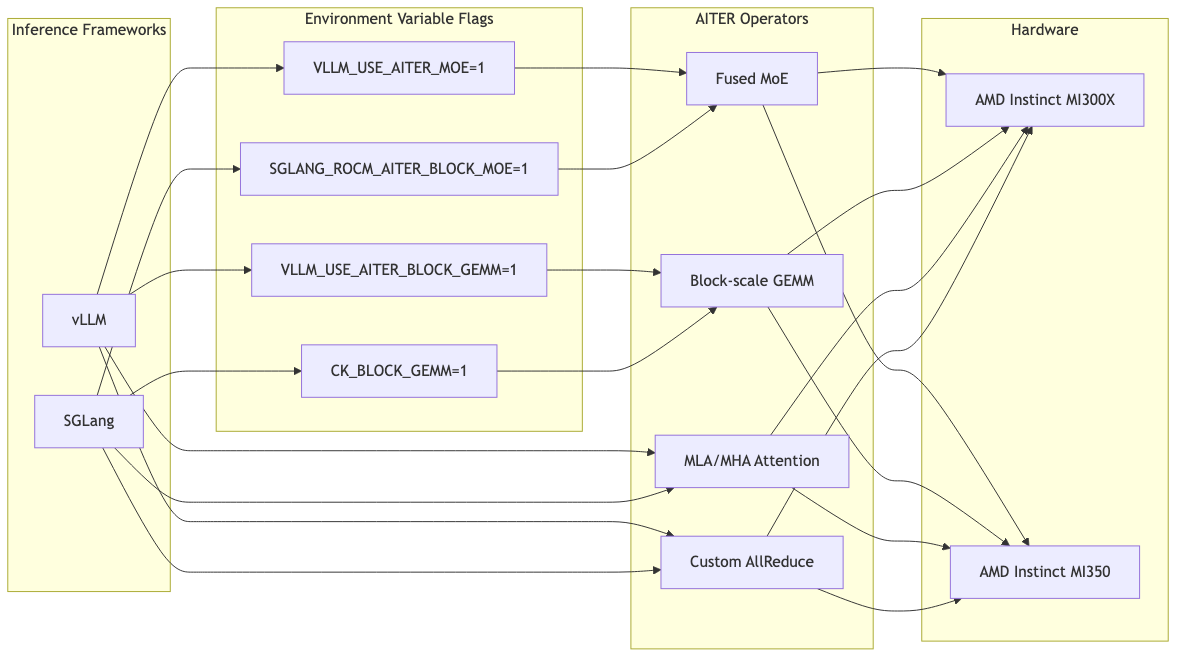
AITER 는 기존 코드를 건드리지 않고 통합할 수 있습니다. 환경 변수만 설정하면 됩니다.
# Enable AITER in vLLM
VLLM_USE_AITER_MOE=1 VLLM_USE_AITER_BLOCK_GEMM=1 \
vllm serve deepseek-ai/DeepSeek-V3 --tensor-parallel-size 8
# Enable AITER in SGLang
CK_BLOCK_GEMM=1 SGLANG_ROCM_AITER_BLOCK_MOE=1 \
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8
프레임워크가 환경 변수를 확인하고 조건부로 AITER operator로 디스패치합니다. 덕분에 A/B 테스트도 간단합니다. 환경 변수를 켜고 끄는 것만으로 AITER 적용 전후 성능을 비교할 수 있습니다.
첫 실행 시에는 JIT 컴파일이 트리거되어 ~/.cache/aiter/ 에 .so 파일이 생성됩니다. 이후 실행에서는 캐시된 커널을 재사용하므로 추가 비용이 없습니다.
핵심 설계 패턴 정리
AITER 를 살펴보면서 눈에 띄었던 설계 패턴들을 정리합니다.
멀티 백엔드 커널 디스패치
하나의 커널 언어를 고집하지 않습니다. decode attention 에는 ASM, GEMM 에는 CK, MoE sorting 에는 Triton 을 사용합니다. unified compiler 전략과는 다른 접근입니다.
FP8 Block-scale Quantization
토큰별 (1x128) activation scale + weight별 (128x128) 스케일로 효율적인 mixed precision operation을 가능하게 합니다. 특히 DeepSeek 과 같은 MoE 아키텍처에서 큰 효과를 발휘합니다.
CSV 기반 auto-tuning
커널 파라미터가 (M, N, K, cu_num) 형상별로 CSV 파일에 저장됩니다. 재컴파일 없이 모델별 튜닝이 가능합니다. DeepSeek V3, Qwen3, LLaMA 405B 등 21개 모델 설정이 pre-tuned되어 있습니다.
하드웨어 특화 최적화

MI300X 인터 GPU 토폴로지에 특화된 커스텀 AllReduce, 최적 메모리 접근 패턴을 위한 weight pre-shuffling(16x16 레이아웃) 등 하드웨어 수준의 최적화가 포함되어 있습니다.
결론
AITER 는 AMD 가 NVIDIA 와의 AI inference 성능 격차를 줄이기 위해 만든 커널 라이브러리입니다. 단일 커널 언어에 의존하지 않고 Triton, CK, HIP, ASM 4가지 백엔드를 operator별로 골라 쓰는 구조가 특징입니다.
Semi Analysis 의 InferenceX v2 보고서에서도 언급되었듯이, AITER 의 최적화는 MI300X 의 SGLang 성능을 거의 2배로 끌어올렸습니다. 다만 Semi Analysis 가 지적한 것처럼, 개별 커널 성능은 뛰어나지만 FP4, disaggregated serving, expert parallelism 등 여러 최적화를 동시에 조합 했을 때의 성능(composability)은 아직 NVIDIA 대비 부족한 부분이 있습니다.
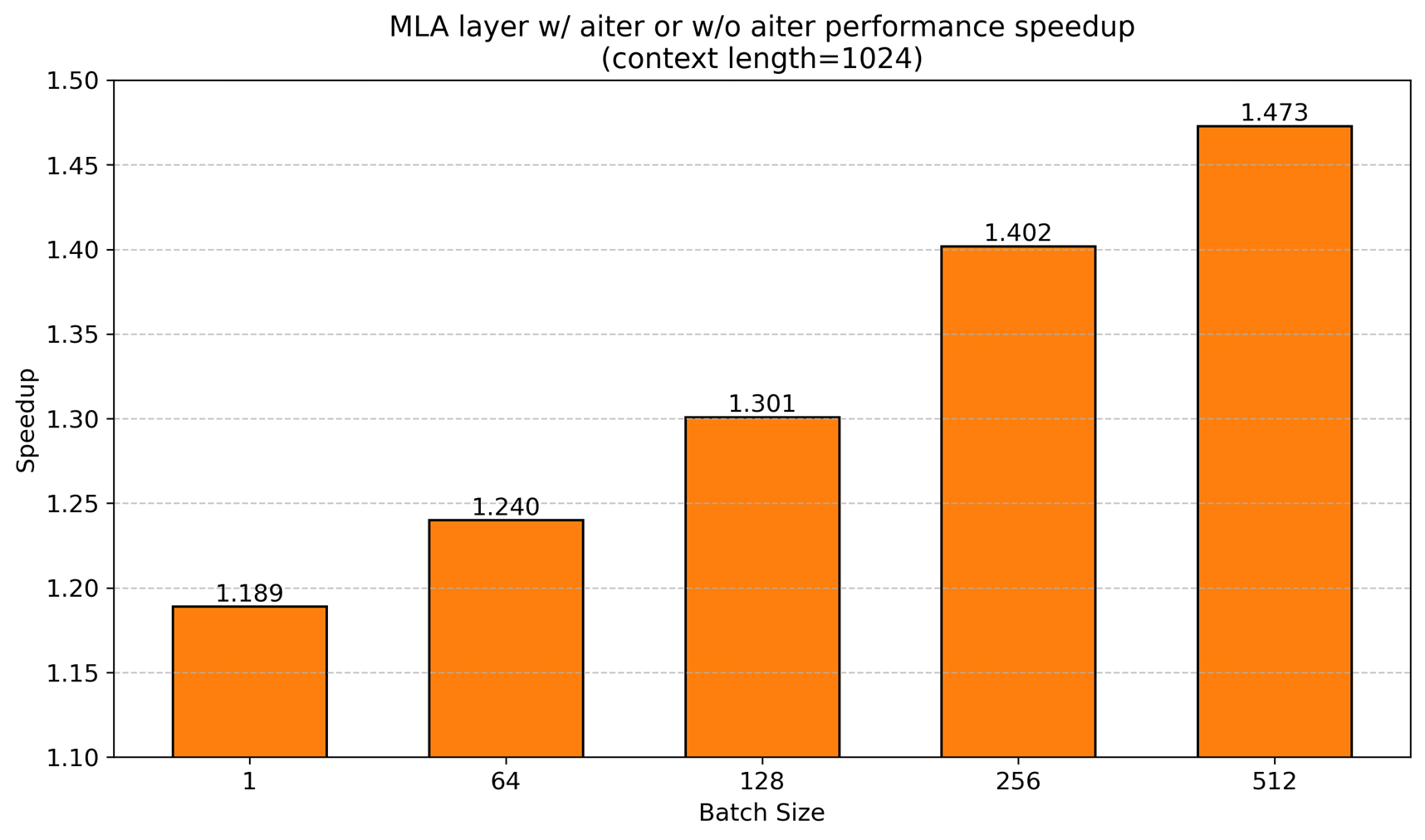
그래도 AITER 가 보여준 것은 분명합니다. 소프트웨어 최적화만으로 같은 하드웨어에서 2배 성능을 뽑아낼 수 있다는 사실입니다. NPU 를 개발하고 있는 저희 입장에서도, 하드웨어의 이론적 성능을 실제 성능으로 전환하는 것이 얼마나 중요한지 다시 한번 느끼게 되었습니다.
참고 자료
- GitHub: ROCm/aiter
- Semi Analysis: InferenceX v2 — NVIDIA Blackwell Vs AMD vs Hopper
- Semi Analysis: AMD 2.0 — New Sense of Urgency
- AMD 블로그: AITER — AI Tensor Engine For ROCm
- AMD 블로그: Accelerate DeepSeek-R1 with AITER + SGLang
추신
HyperAccel 채용 안내
AITER 를 분석하면서 커널 레벨 최적화가 얼마나 큰 차이를 만드는지 체감했습니다. NPU 회사인 저희도 하드웨어 성능을 제대로 끌어내는 소프트웨어 스택을 만들어가고 있습니다. LPU 의 ASIC 출시를 앞두고, 커널 최적화부터 inference framework integration까지 함께할 팀원을 기다리고 있습니다.
채용 사이트: https://hyperaccel.career.greetinghr.com/ko/guide
혹시 관심이 있으시다면 언제든지 연락 주세요!