
지피지기면 백전불태 4편 : 메모리 용량 병목과 NVIDIA ICMS
“상대를 알고 나를 알면 백 번 싸워도 위태롭지 않다.”
이 시리즈는 AI 가속기 설계를 위해 경쟁사들의 하드웨어를 깊이 이해하는 것을 목표로 합니다.
네 번째 글에서는 올해 초 NVIDIA 젠슨황 CEO가 CES 키노트 세션에서 발표한 ICMS(Inference Context Memory Storage)와 이를 관리하는 프로세서인 DPU(Data Processing Unit)에 대해 다룹니다.
안녕하세요? HyperAccel DV팀 소속 하드웨어 검증 엔지니어 임재원입니다.
오늘 글은 지난달 CES 2026에서 있었던 NVIDIA CEO 젠슨황의 키노트 세션으로 시작을 해보겠습니다. 오늘 소개드릴 내용의 대부분이 이 키노트 영상 후반부에 담겨 있습니다. reference에 링크를 남겨두었으니 키노트 내용에 대해 더 자세히 알고 싶게 된 분들은 아래 링크의 풀 영상을 참조하시기 바랍니다.
Rubin 플랫폼
매해 젠슨황 키노트는 AI의 발전 방향과 반도체가 해야 할 일에 대해 알 수 있는 중요한 지표입니다. 특히 당해에 출시될 NVIDIA의 최신 라인업 GPU와 GPU pod을 구성하는 다양한 구성 요소들의 발전이 함께 소개됩니다.
올해 젠슨황 CEO가 키노트에서 강조한 것은 올해 하반기에 정식 출시될 Rubin GPU로 구성될 데이터센터향 제품인 Rubin 플랫폼입니다.

위 이미지에서 사각형으로 표시한 부분이 Vera CPU 36개, Rubin GPU 72개가 탑재된 NVL72 랙입니다. 이 랙에는 18개의 연산용 트레이가 층층히 들어있고, 각 연산 트레이마다 CPU 2개, GPU 4개가 장착됩니다. 추가로 이 트레이에는 CPU와 GPU뿐만 아니라 다른 트레이, 혹은 스토리지와 같은 다른 장치들과 통신하기 위한 또 다른 칩들이 들어있습니다.
결과적으로 Vera Rubin 플랫폼을 구성하는 칩들을 모아보면 아래 이미지와 같습니다. CPU와 GPU의 성능 향상도 물론 괄목할 만한 부분이지만 오늘 우리가 주목할 것은 CPU와 GPU가 아닌 아래 그림의 5번째 위치한 칩인 Bluefield-4 DPU입니다. DPU에 주목해야 할 이유를 알기 위해서는 Rubin 플랫폼 소개 이후 젠슨황이 새롭게 던진 화두인 AI의 새로운 병목 지점에 대해 알아 보아야 할 필요가 있습니다.

Context is the new bottleneck : 메모리 용량 자체가 병목이 되다
메모리 대역폭만이 병목이 아닙니다. 메모리 용량 그 자체가 새로운 병목이 되었습니다. 지난 글에서 LLM 연산 특성을 통해 LLM 연산이 memory-bound인 이유와 HBM 수요가 증가하게 된 배경에 대해 설명드린 바 있습니다. 매 토큰을 생성할 때마다 메모리에서 KV cache를 가져오기 때문에 메모리 대역폭이 병목이 되었습니다.
하지만 최근 발생한 새로운 문제는 KV cache를 GPU 메모리에 올릴 수 없을 정도로 KV cache 자체에 필요한 용량이 많아졌다는 것입니다. 이는 최근 LLM 모델 발전이 context 길이를 늘리는 방향으로 이뤄지고 있기 때문입니다.
OpenAI가 2024년 말 공개한 reasoning model과 claude cowork와 같은 agentic AI가 그 대표적인 예시입니다.
Reasoning model
OpenAI의 o1, o3를 필두로 뛰어난 성능 향상으로 각광을 받은 Reasoning 모델들은 복잡한 문제를 해결하기 위해 ‘생각하는 시간’을 길게 갖습니다. 이 과정에서 모델은 최종 답변을 내놓기 전 내부적으로 수많은 ‘생각 토큰’들을 생성합니다.
- 내부 추론 토큰: 겉으로 드러나지 않더라도 모델이 논리적 단계를 밟기 위해 생성하는 ‘생각’ 토큰들이 전체 문맥의 상당 부분을 차지하게 됩니다.
- 자가 교정(Self-correction): 추론 과정 중에 오류를 발견하고 이를 수정하는 과정이 반복되면서, 수백개 정도의 토큰으로 이뤄진 질문에도 수천 토큰 이상의 문맥이 순식간에 쌓이게 됩니다.
Agentic AI
에이전트형 AI는 단순히 질문에 답하는 것을 넘어, 스스로 계획을 세우고 도구를 사용하며 환경과 상호작용합니다. 이 과정은 ‘관찰-판단-행동’의 루프를 반복하며 이뤄집니다.
- 상호작용 이력 유지: 에이전트가 어떤 도구를 썼고, 그 결과가 어떠했으며, 다음 계획은 무엇인지에 대한 모든 기록을 컨텍스트에 유지해야 일관된 동작이 가능합니다.
- 대량의 환경 데이터: 웹 페이지 스크린샷, 전체 코드베이스, 방대한 문서 등 에이전트가 처리해야 할 데이터 자체가 크기 때문에 컨텍스트 윈도우의 요구치가 급격히 상승합니다.
- 반복적 정교화: 한 번에 성공하지 못할 경우 실패 원인을 분석하고 다시 시도하는 과정이 누적되면서 일반적인 챗봇 대비 수십 배 이상의 토큰을 소모하게 됩니다.
용량에 대한 감이 안오시는 분들을 위해 숫자를 통한 예시를 보여드리겠습니다.
Transformer 구조에서 토큰당 필요한 KV cache 용량 계산식은 아래와 같습니다.
$$\text{Total KV Cache Memory} = 2 \times B \times S \times L \times H_{kv} \times D_h \times P$$
$$B : batch\ size$$ $$S : sequence\ length$$ $$L : num\ layer$$ $$H_{kv} : num\ head$$ $$D_{h} : head\ dimension$$ $$P : precision(BF16: 2B,\ FP8: 1B)$$
model config가 공개된 Llama 3.1 405B 모델에 이 계산식을 적용해보면 토큰 1개당 약 516KB의 KV cache size가 사용됩니다. 여기서 사용자당 10만정도의 context length를 사용한다고 가정한다면 사용자당 필요한 KV cache 크기는 48GB, 128명의 사용자가 동시에 사용한다면 순간적으로 필요한 KV cache 크기는 6TB까지 커집니다.
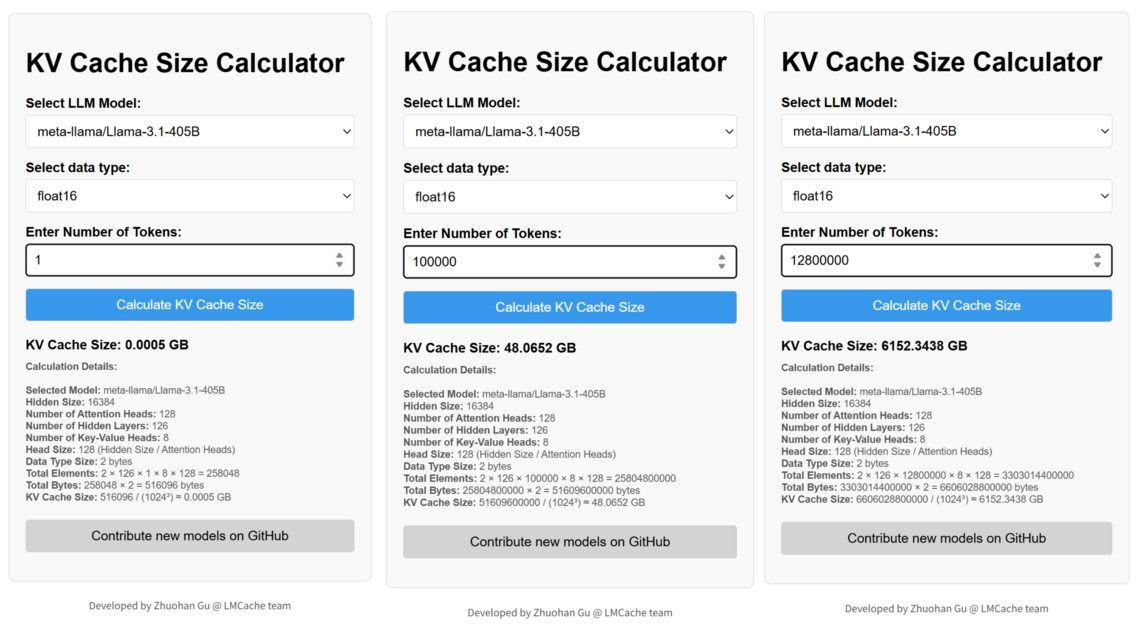
모델 parameter를 제외한 KV cache 에만 6TB의 메모리가 필요하게 됩니다. 아직 출시되지 않은 Rubin GPU 기준으로도 약 20개의 GPU에 해당하는 HBM이 필요한 수준입니다. 실제로 이러한 문제로 인해 GPU와 함께 탑재된 CPU의 DRAM에 KV cache를 저장하거나 다른 GPU의 HBM을 사용하는 식으로 저장고를 확장시키는 memory-offloading이 사용되고 있습니다.
그렇다면 NVLink로 연결된 위 아래의 compute tray GPU로 KV cache를 넘기면 되지 않을까요? 랙하나에 72개 GPU가 들어가니 이론상으로 20TB 이상의 HBM memory를 공유할 수 있을 것입니다. 이는 언뜻 가장 빠른 방법처럼 보이지만, 데이터센터 스케일의 서빙에서는 몇 가지 문제가 있습니다.
- HBM의 기회비용: HBM은 단순 저장소로 쓰기에는 너무 비싸고 희귀한 자원입니다. 다른 GPU의 HBM에 내 KV cache를 넘기는 순간, 그 GPU는 자신이 처리해야 할 새로운 요청을 받을 공간을 잃게 됩니다. 자신이 저장할 수 있는 KV cache 용량을 뺏긴 셈이기 때문이죠. 데이터센터 운영자 입장에서 GPU의 연산 가동률을 높여야 수익이 나는데, HBM을 단순 스토리지로 쓰는 것은 비효율적인 선택입니다.
- NVLink 트래픽 혼잡: NVLink는 이미 모델 연산을 위한 병렬처리(Model Parallelism)를 위한 통신이 대부분의 트래픽을 차지하고 있습니다. 여기에 GPU 간 KV cache 공유가 빈번해지면 실질 모델 연산에 필요한 통신 대역폭까지 잠식하는 트래픽 혼잡이 발생합니다.
- 장애 전파 위험: 내 KV cache를 들고 있는 옆 GPU 노드에 문제가 생기면 내 추론 작업까지 함께 멈춰버리는 의존성 문제가 발생합니다.
한편, NVLink 기반 공유 이외에도 또 다른 문제가 있습니다. 지금까지는 사용자가 하나의 request를 보냈을 때의 상황만을 고려했습니다. 하지만 사용자들은 하나의 request만 보내지 않습니다. 여러 번의 request를 보낸다면 상황은 어떻게 될까요? 그중에서 과거에 보냈던 요청과 동일한 KV cache를 필요로 한다면? 메모리 용량 문제로 이전에 생성한 KV cache를 이미 지워버렸다면, GPU는 수십~수백 GB에 달하는 KV cache를 처음부터 다시 연산해야 합니다. 지난 시간에 말씀드렸듯 이 정도의 데이터를 다시 연산하는 것은 엄청난 연산량 낭비이자 시간 낭비입니다.
KV cache를 위한 스토리지의 필요
결국 데이터센터 환경에서는 각 GPU가 연산에만 집중할 수 있도록 하면서, 동시에 대량의 KV cache를 지우지 않고 보관할 수 있는 별도의 공유 저장소가 필요합니다.
이를 위해 우리는 memory hierarchy의 더 하위 계층의 메모리를 활용해야 할 수 밖에 없게 된 것입니다. 가장 먼저 떠오르는 것은 각 서버 트레이 내부에 장착된 로컬 SSD에 KV cache를 저장하는 방법입니다. 하지만 로컬 SSD에는 두 가지 근본적인 한계점이 있습니다.
- 용량 한계: 한 서버 트레이 안에 넣을 수 있는 SSD 개수는 공간과 전력 문제로 매우 제한적입니다.
- 공유 문제: 한 서버의 로컬 SSD에 저장된 KV cache는 다른 서버가 직접 읽을 수 없습니다. 네트워크를 타고 CPU가 관여하여 넘겨줘야 하는데 이는 너무 느립니다.
그렇다고 데이터센터 저 멀리의 범용 네트워크 스토리지(NAS 등)를 쓰자니, 용량은 충분하지만 네트워크 지연이 너무 커서 LLM 서빙의 대역폭 요구를 감당할 수 없습니다. 로컬 SSD는 빠르지만 너무 작고 공유가 안 되며, 네트워크 스토리지는 크지만 너무 느립니다.
NVIDIA가 DPU를 통해 해결하려고 하는 문제가 바로 여기에 있습니다.
NVIDIA의 해결책: ICMS (Inference Context Memory Storage)
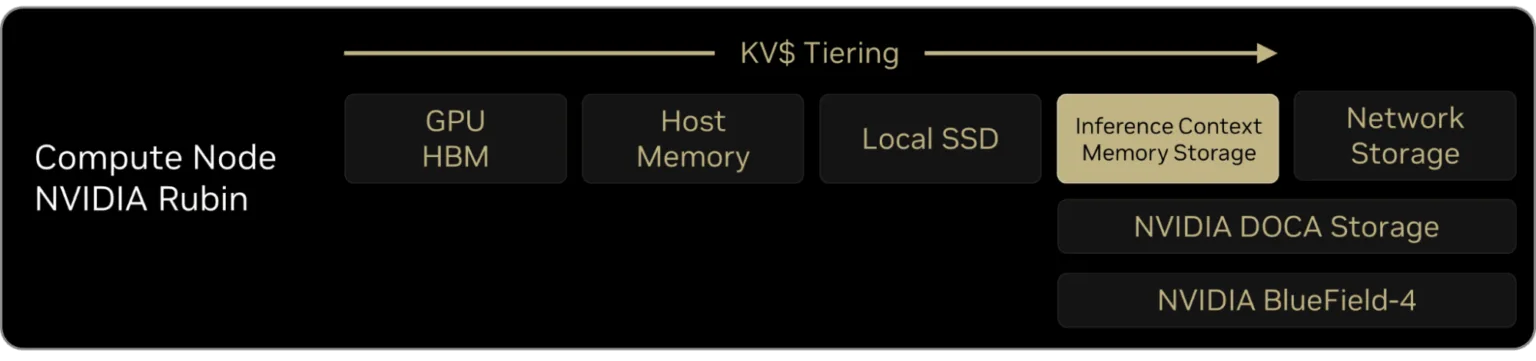
NVIDIA는 이 문제를 해결하기 위해 로컬 SSD(G3 계층)와 네트워크 스토리지(G4 계층) 사이에 G3.5 계층이라고 불리는 ICMS를 도입했습니다. 로컬 SSD의 빠른 대역폭과 네트워크 스토리지의 거대한 공유 능력을 결합한 것입니다.

ICMS는 별도의 전용 랙에 존재하지만, BlueField-4 DPU와 PCIe Gen 6로 직결되어 로컬 SSD를 읽는 것과 거의 차이 없는 속도를 내면서도, 모든 GPU가 DPU를 통해 자신의 로컬 메모리처럼 접근할 수 있는 거대한 공유 메모리 풀 역할을 합니다. NVIDIA의 목적은 ICMS를 통해 GPU가 추론 연산에서 활용할 수 있는 메모리를 HBM과 DRAM에서 SSD(NAND Flash)까지 확장하는 것입니다. 아까 보여드렸던 Rubin 플랫폼 랙 중 표시한 부분이 이 ICMS용 랙입니다. 이를 통해 Rubin 플랫폼의 각 GPU는 기존 HBM 1TB + 추가 16TB 스토리지를 자신의 HBM 메모리처럼 활용할 수 있습니다. compute tray에 GPU와 같이 꽂혀있는 Bluefield-4 DPU가 GPU ↔ ICMS 간 데이터 통신을 관리해주는 역할을 하게 됩니다.
대역폭의 한계를 극복하기 위한 소프트웨어 최적화
그러나 DPU의 스펙 문서를 보게 되면 한가지 의문점이 듭니다. HBM 대역폭은 2.2TBps인 반면에, DPU 대역폭은 100GBps로 대략 1/20 수준이기 때문입니다. 개별 GPU에서 활용할 수 있는 메모리 용량이 늘어났더라도 그 메모리에서 데이터가 오는 속도가 HBM과 차이가 난다면 메모리 대역폭에서 병목이 발생하지 않을까요?
충분히 합리적인 의문입니다. 하지만 ICMS가 타겟팅하는 메모리인 KV cache의 사용 특성을 이용하면 이 한계를 극복할 수 있습니다. KV cache는 decode 단계에서 이전에 생성된 KV cache를 반복해서 재사용하는 특성을 갖고 있습니다. 그렇다면 다음 토큰 연산을 위해 필요한 KV cache는 미리 GPU로 가져오더라도 큰 문제가 없습니다. 이는 소프트웨어적으로 예측 가능한 영역입니다.
추론 최적화를 위한 프레임워크 : vLLM과 SGLang, 그리고 LMCache
앞서 설명드린 KV cache의 특성을 활용하여 추론 연산을 최적화하기 위한 다양한 프레임워크들이 개발되어왔습니다. 지난번에 김재우님(Author, LinkedIn)이 소개해주신 SGLang도 그 중 하나입니다.
vLLM & SGLang
![]() vLLM과 SGLang은 추론 연산 가속을 위한 엔진으로 GPU 메모리 안에서 KV cache를 효율적으로 관리하기 위한 기능을 제공합니다. 그중 하나가 prefix caching인데요. 특정 request에서 입력된 sequence의 앞부분(prefix)과 다음 request에서 입력된 sequence의 앞부분이 겹치는 경우 해당 부분에 대해서 이전 request에서 생성된 KV cache를 그대로 재사용할 수 있는 기능입니다. 같은 request 내에서 decoding 작업 시 매 토큰 생성마다 해당 request 내에서 생성된 KV cache를 재사용하는 것은 기본적으로 가능하였습니다. 이 기능은 거기서 한발 더 나아가 서로 다른 request에서도 입력토큰만 같다면 생성되는 KV cache는 같을 것이기 때문에 추가적인 연산 필요 없이 KV cache를 재사용할 수 있는 것입니다.
vLLM과 SGLang은 추론 연산 가속을 위한 엔진으로 GPU 메모리 안에서 KV cache를 효율적으로 관리하기 위한 기능을 제공합니다. 그중 하나가 prefix caching인데요. 특정 request에서 입력된 sequence의 앞부분(prefix)과 다음 request에서 입력된 sequence의 앞부분이 겹치는 경우 해당 부분에 대해서 이전 request에서 생성된 KV cache를 그대로 재사용할 수 있는 기능입니다. 같은 request 내에서 decoding 작업 시 매 토큰 생성마다 해당 request 내에서 생성된 KV cache를 재사용하는 것은 기본적으로 가능하였습니다. 이 기능은 거기서 한발 더 나아가 서로 다른 request에서도 입력토큰만 같다면 생성되는 KV cache는 같을 것이기 때문에 추가적인 연산 필요 없이 KV cache를 재사용할 수 있는 것입니다.
다만 vLLM과 SGLang의 한계는 KV cache 관리 영역이 GPU memory (+CPU host memory)로 한정되어 있고, 입력 토큰이 처음부터 같을 때에만 prefix caching을 사용할 수 있다는 점입니다. 같은 sub sequence가 중간에 있더라도 앞선 prefix들이 다르면 KV cache를 재사용할 수 없습니다. 이는 causal attention 구조의 특성 상 현재 토큰으로 생성되는 KV cache가 자신보다 앞에 있는 모든 토큰에 영향을 받기 때문입니다. 이 기능이 “prefix” caching이라 불리는 이유도 여기에 있습니다.
LMCache
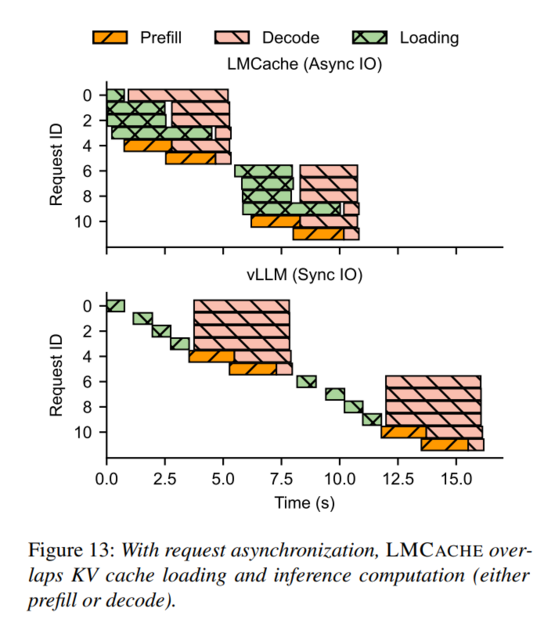
![]() LMCache는 이러한 한계를 극복하기 위해 탄생한 KV cache 전용 분산 캐시 관리 프레임워크입니다. 앞서 언급한 기능인 현재 연산 중에 다음에 필요한 KV cache를 디바이스의 메모리에서 동시에 prefetch를 진행할 수 있는 기능을 제공합니다.
LMCache는 이러한 한계를 극복하기 위해 탄생한 KV cache 전용 분산 캐시 관리 프레임워크입니다. 앞서 언급한 기능인 현재 연산 중에 다음에 필요한 KV cache를 디바이스의 메모리에서 동시에 prefetch를 진행할 수 있는 기능을 제공합니다.
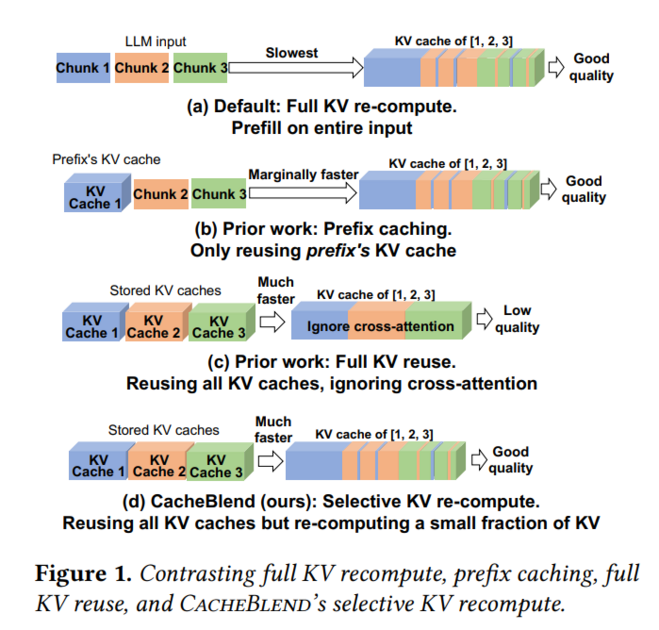
아울러 prefix-caching의 한계를 극복한 CacheBlend 기법을 사용하여 토큰 위치가 다른 곳에서 생성된 KV cache에 토큰 위치와 이전 맥락에 대한 추가적인 연산을 통해 KV cache를 그대로 다시 계산하는 것보다 훨씬 적은 연산량으로 KV cache를 계산할 수 있는 non-prefix cache reuse를 지원합니다.
NVIDIA의 추론 프레임워크 Dynamo에도 LMCache가 통합되어 있으며, ICMS에서 이 LMCache 기능이 탑재된 Dynamo가 활용됩니다. 아울러 HyperAccel에서도 LPU에서 LMCache를 지원할 수 있도록 소프트웨어를 개발중에 있습니다.
Bluefield-4 DPU의 역할
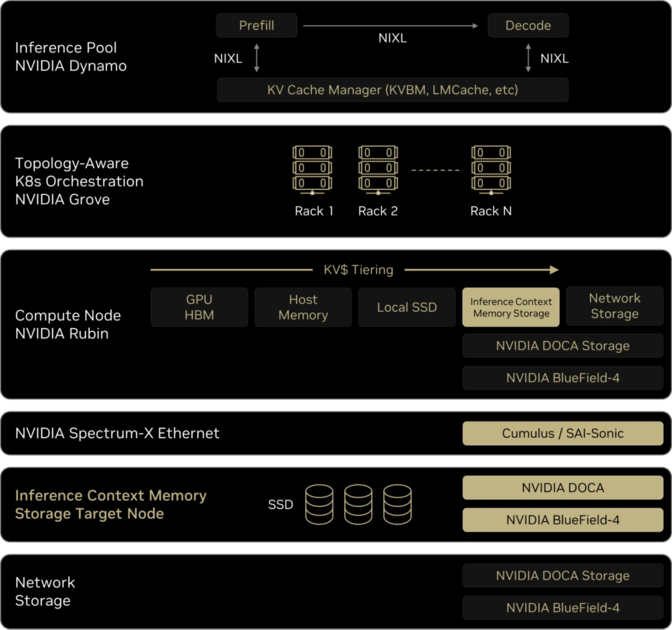 DPU는 이러한 소프트웨어를 사용하여 GPU와 다른 디바이스 간 데이터 전송과 memory offload를 위한 연산을 수행하고 데이터 이동을 효율적으로 관리하기 위한 보조 프로세서입니다. DPU 내부에도 Vera CPU 이전 버전인 Grace CPU가 탑재되어 있어 앞서 설명한 스토리지 관리를 위한 소프트웨어를 구동할 수 있습니다. 기존에는 이러한 역할을 CPU에서 대부분 진행하였지만, DPU가 데이터 이동에 관한 연산을 수행하게 되면 기존 CPU는 연산에 대한 부담을 줄이고 LLM 연산을 위한 스케줄링이나 다른 연산에 자원을 집중할 수 있습니다. 이외에도 AI 네오 클라우드에서 필수적인 데이터 암호화 기능도 DPU에서 가속하여 confidential computing 환경을 구축하는데 도움을 줍니다.
DPU는 이러한 소프트웨어를 사용하여 GPU와 다른 디바이스 간 데이터 전송과 memory offload를 위한 연산을 수행하고 데이터 이동을 효율적으로 관리하기 위한 보조 프로세서입니다. DPU 내부에도 Vera CPU 이전 버전인 Grace CPU가 탑재되어 있어 앞서 설명한 스토리지 관리를 위한 소프트웨어를 구동할 수 있습니다. 기존에는 이러한 역할을 CPU에서 대부분 진행하였지만, DPU가 데이터 이동에 관한 연산을 수행하게 되면 기존 CPU는 연산에 대한 부담을 줄이고 LLM 연산을 위한 스케줄링이나 다른 연산에 자원을 집중할 수 있습니다. 이외에도 AI 네오 클라우드에서 필수적인 데이터 암호화 기능도 DPU에서 가속하여 confidential computing 환경을 구축하는데 도움을 줍니다.
정리
오늘은 LLM의 새로운 병목인 저장소 문제와 함께 이를 해결하기 위한 NVIDIA의 새로운 플랫폼 ICMS, 이를 관리하는 새로운 프로세서인 DPU와 DPU에서 구동하는 소프트웨어 프레임워크들에 대해 알아보았습니다. 이를 통해 NVIDIA가 GPU에서 활용하는 메모리를 플래시 메모리까지 확장하기 위해 사용한 하드웨어/소프트웨어적 기술들을 엿볼 수 있었습니다.
그런데, 이 플래시 메모리를 칩 바로 옆에 두면 더 빠르게 쓸 수 있지 않을까요? 최근 부상하고 있는 HBF(High Bandwidth Flash)가 이를 가능하게 하는 기술입니다. HBF는 신기술 트렌드를 다루는 다른 시리즈에서 다뤄보겠습니다.
다음 글에서는 주제를 가속기로 다시 가져가 보겠습니다. OpenAI의 코드 생성 모델 Codex-Spark를 서비스하며 주목받은 기업이죠. 웨이퍼 한 장 크기의 거대한 칩을 만드는 AI 가속기 스타트업 Cerebras와 Wafer Scale Engine에 대해 알아보겠습니다.
추신 : HyperAccel은 채용 중입니다.
HyperAccel은 데이터센터향 LPU 첫 제품 출시를 목전에 두고 있으며, 하드웨어/소프트웨어 최적화를 통해 LLM 추론의 핵심 병목들을 해소할 수 있는 솔루션을 개발해 나가고 있습니다.
저희의 기술적 여정에 흥미가 있으시다면, HyperAccel Career를 통해 지금 바로 지원해 주세요!
HyperAccel은 여러분의 지원을 기다립니다.
Reference
- CES 2026 Jensen Huang Keynote
- LMCache KV Cache Calculator
- Inside the NVIDIA Rubin Platform
- Introducing Bluefield-4 powered ICMS
- LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference
- CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
- NVIDIA Dynamo LMCache integration