지피지기면 백전불태 3편 : 엔비디아가 200억 달러에 인수한 그록의 LPU
“상대를 알고 나를 알면 백 번 싸워도 위태롭지 않다.”
이 시리즈는 AI 가속기 설계를 위해 경쟁사들의 하드웨어를 깊이 이해하는 것을 목표로 합니다.
세 번째 글에서는 작년 말 엔비디아에 약 200억달러로 인수된 미국의 스타트업 그록(groq)의 LPU(Language Processing Unit)에 대해 다룹니다.
구글을 박차고 나온 엔지니어의 과감한 도전

그록의 탄생 배경에 대해 알기 위해서는 창업자인 조나단 로스(Jonathan Ross)에 대해 알아봐야 할 필요가 있습니다. 그는 구글에서 TPU(Tensor Processing Unit) 프로젝트를 처음 시작했던 핵심 멤버였습니다. TPU 개발팀에서 근무하던 그는 향후 AI 추론 시장의 성장 가능성을 직감하고 구글을 박차고 나와 그록을 창업합니다. 그리고 독자적인 추론 전용 칩인 LPU(Language Processing Unit)을 세상에 내놓았습니다.
이들이 목표로 한 시장은 저희 HyperAccel이 지향하는 지점과 매우 유사합니다.
- GPU / TPU: 학습(Training)과 추론(Inference)을 모두 지원하지만, 태생적으로 대규모 연산 집중적인 학습에 최적화
- LPU: 학습은 과감히 버리고, 오직 거대언어모델(LLM)의 추론 최적화에만 올인
학습과 추론의 개념에 대해 생소한 분들은 여기서 이러한 의문이 들 수 있을 것입니다.
??? : 학습? 추론? 다 같은 AI 연산아닌가? GPU는 다 잘하는거 아닌가? 추론 특화 칩이 필요한 이유가 뭐지?
그런 분들을 위해 AI 연산에서 학습과 추론의 차이에 대해 잠시 짚고 가도록 하겠습니다.
학습과 추론 : 범용칩의 한계와 전용칩의 기회
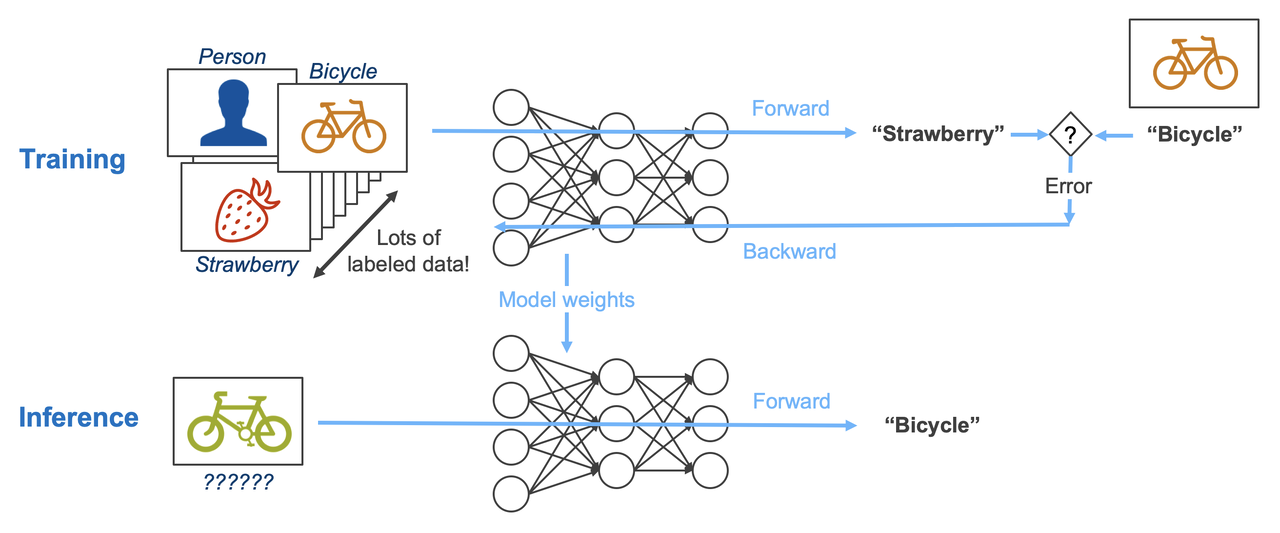
AI workload는 크게 가중치를 업데이트하는 학습과, 고정된 가중치를 사용하는 추론으로 나누어 볼 수 있습니다.
주어진 이미지를 보고 어떤 이미지인지 구분하는 AI 모델을 개발한다고 가정해봅시다. 이를 위해서는 먼저 다량의 이미지 데이터를 통해 모델을 훈련시키는 과정이 필요합니다. 훈련 과정에서 모델은 이미지를 보고 현재 가중치를 바탕으로 정답을 내놓은 뒤(Forward path), 정의된 학습 메커니즘에 따라 실제 정답과의 오차를 비교하고 이를 바탕으로 현재 가중치를 업데이트합니다(Backward path). 이를 반복하면 모델의 가중치는 계속해서 업데이트되고, 충분한 시간이 지나면 이 모델은 오차가 줄어들고 이미지를 잘 구분할 수 있게 됩니다. 학습이 어느정도 진행되었다면 이 모델을 실제로 사용해야 하겠죠? 이 추론 과정에서는 학습과 달리 가중치를 업데이트할 필요가 없습니다. 이미 학습을 마친 모델의 가중치를 업데이트 하는 과정은 실제 사용 단계에선 불필요한 연산이기 때문이죠. 따라서 추론 과정에서는 Forward path만 존재합니다.
이를 통해 알 수 있는 사실은 추론은 학습만큼의 엄청난 연산량을 필요로 하지 않는다는 점입니다.
하지만 이것만으로 전용칩의 타당성을 입증하기엔 부족합니다. 단순히 추론의 연산량이 적다면, 오버 스펙이더라도 GPU나 TPU와 같은 엄청난 연산량을 지원하는 하드웨어로 많은 추론연산을 진행하면 그만이기 때문이죠. 실제로 AI 기업에서는 학습에는 최고사양의 GPU 라인업(B200 등)을, 추론에는 상대적으로 낮은 라인업의 GPU(H200 등)을 사용하고 있습니다. 현재 LLM이 이끌고 있는 생성형 AI 시장에서 추론 칩의 필요성을 알기 위해서는 현재 사용되는 LLM의 구조적 한계에 대해 살펴보아야 합니다.
LLM의 구조적 한계 : 병목은 컴퓨팅이 아닌 메모리에 있다
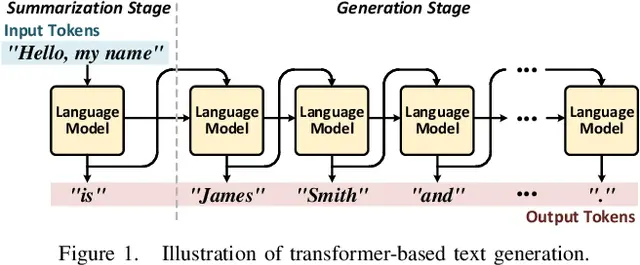
현재 GPT, Gemini, Grok 등 LLM 모델의 근간이 되는 Transformer 아키텍쳐의 근본적인 특징은 결과값을 한번에 문장으로 생성하는 것이 아닌, 단어(이하 토큰) 하나씩 순차적으로 생성한다는 것입니다. 이를 자기회귀적(auto-regressive) 특성을 가진다고 표현합니다. 이는 Transformer 모델이 입력값을 통해서만 결과값을 생성하지 않는 것이 아니라, 출력 토큰이 생성될 때마다 입력 토큰들과 지금까지 생성된 출력 토큰들과의 관계를 다시 계산해서 다음 출력 토큰을 생성하기 때문입니다. 이렇게 되면 연산이 엄청나게 많이 필요하겠지요. 하지만 문제는 연산량 뿐만이 아닙니다. 매번 토큰을 생성할 때마다 모든 값들을 다시 계산하게 되면 연산 비효율이 높아지기 때문에 재사용이 가능한 중간 값(KV cache)들은 메모리에 넣어두고 다음 토큰을 연산할 때 메모리에서 이를 읽어와서 다시 계산하게 됩니다. 문제는 이로 인해 토큰을 매번 생성할 때마다 과거의 데이터들을 메모리에서 다시 불러와야 하기 때문에 토큰을 많이 생성할수록 메모리 이동량이 증가하게 되는 것입니다.
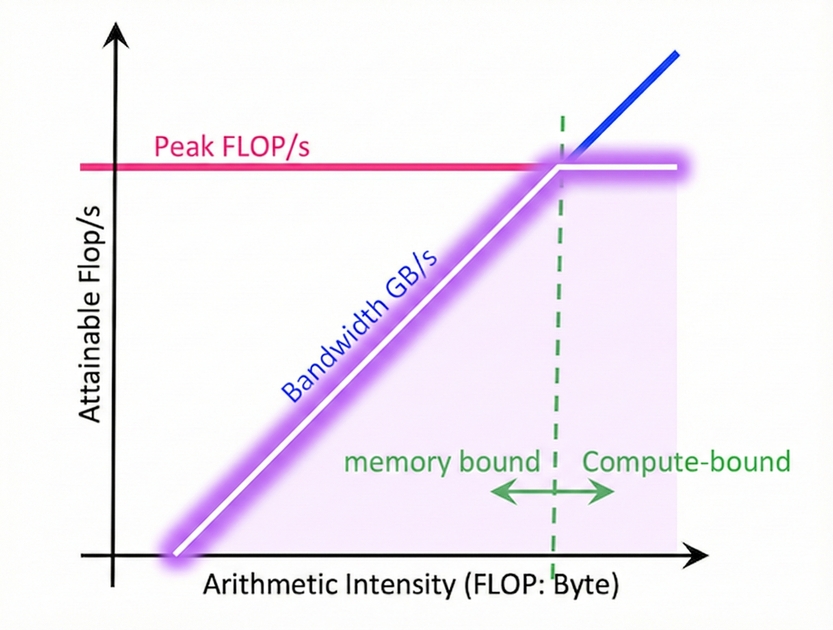
컴퓨터 구조에서는 하드웨어 성능의 한계를 진단하기 위해 Roofline Model이라는 측정 기법을 사용합니다. 하드웨어에서 사용되는 소프트웨어의 연산 특성과 하드웨어 스펙을 통해 해당 연산의 가능한 최대의 성능을 확인하는 것입니다.
Roofline Model 그래프는 두 개의 축으로 구성됩니다. x축은 연산강도(Operational Intensity)입니다. 한번 가져온 데이터로 얼마 만큼의 연산을 수행하느냐를 나타내는 지표이며, 데이터 재사용성이 높아질수록 증가합니다. y축은 성능(Performance)으로, 일반적으로 초당 부동소수점 연산 횟수(FLOPS/s, FLOPS : Floating Point Operations)로 표현됩니다.
그래프 위의 각 선들은 하드웨어의 성능 한계를 나타냅니다. 기울기가 있는 선은 메모리 대역폭에 의한 성능 한계를 나타내며, 연산강도가 낮을 때(초록 점선 기준 왼쪽 영역) 이 선을 따라 최대 성능이 결정됩니다. 이 영역에서는 하드웨어의 연산 능력이 아무리 뛰어나도 메모리에서 데이터를 가져오는 속도에 제한받아 메모리 대역폭에 비례한 성능만 얻을 수 있습니다.(Memory bound). 이 직선의 기울기는 성능(FLOPS/s) / 연산 강도(FLOPS/BYTE)이므로 하드웨어의 메모리 대역폭 (BYTE/s)와 같습니다.
반면 수평선은 하드웨어의 최대 연산 성능 한계를 나타냅니다. 연산강도가 충분히 높아서(초록 점선 기준 오른쪽 영역) 이 수평선에 도달하게 되면, 해당 연산의 성능은 하드웨어가 낼 수 있는 최대 연산 성능과 같아집니다.(Compute bound) 두 선이 만나는 지점을 Ridge Point라고 하며, 이 지점에서 메모리와 연산 성능이 균형을 이룹니다. 이 지점 이후로는 연산 강도가 높아져도 하드웨어적 한계에 막혀서 최대 성능이 더이상 증가하지 못합니다.
- Compute Bound : 하드웨어 스펙에 비해 필요로 하는 연산량이 너무 많아 칩의 계산 속도의 물리적 한계로 병목 발생
- Memory Bound : 연산기는 충분한데, 메모리에서 데이터를 가져오는 속도가 그에 비해 느려서 병목 발생
학습 과정은 연산량도 많이 필요하며, 병렬화가 가능하기 때문에 compute bound에 가깝습니다. 하지만 LLM 추론 과정, 특히 첫 입력 토큰들에 대한 첫 출력 토큰을 계산(Prefill Stage)한 이후에 출력 토큰을 하나씩 뽑아내는 과정(Decoding Stage)에서는 개별 토큰을 출력하기 위해 매번 메모리에서 과거 데이터를 읽어와야 합니다. 아울러 이 데이터의 크기는 출력 토큰 길이가 길어질수록 증가합니다. 이는 연산 강도를 낮추기 때문에 추론 연산은 memory bound에 가깝습니다.
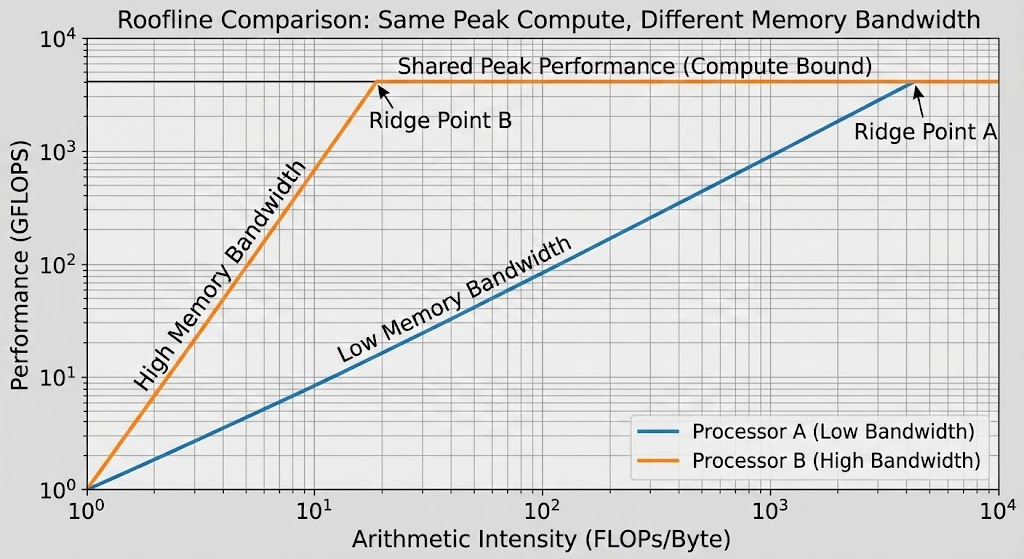
GPU와 다른 데이터센터향 칩들이 비싼 HBM(고대역폭 메모리)을 사용해야만 하는 이유가 바로 여기에 있습니다. 아무리 칩의 연산 속도가 빨라도, 메모리 벽(Memory Wall)을 넘지 못하면 무용지물이기 때문입니다. 앞서 언급했듯, memory-bound 영역에서 그래프의 기울기는 메모리 대역폭과 같기 때문에 HBM을 사용하여 대역폭을 늘리게 되면 아래 그래프와 같이 같은 연산 강도에서도 높은 성능을 뽑아낼 수 있습니다.
추론 칩은 LLM의 이러한 병목지점을 타겟팅합니다. 아무리 연산 성능이 높아도 memory bound로 인해 성능 한계에 도달할 수밖에 없다면, LLM 구조에 맞는 아키텍쳐나 memory bandwidth를 극대화할 수 있는 칩으로 승부를 보는 것입니다. GPU와 같은 범용칩도 이러한 움직임을 보이고는 있지만, 과감한 하드웨어적 혁신과 구조 개선을 하기엔 무리가 있습니다. 현재는 LLM 연산에 GPU가 많이 사용되고 있지만 GPU는 LLM 뿐만 아니라 다양한 구조의 AI 모델 학습과 연산에 사용되고 있으며, AI 연산 뿐만 아니라 이미지 렌더링과 같은 다양한 작업에 활용되는 범용칩이 되었기 때문입니다. 필요 없는 부분을 덜어내고 특수한 workload를 타겟팅한 전용칩이 강점을 보일 수 있는 이유가 바로 여기에 있습니다.
다음으로는 그록이 하드웨어 시장에 이 전용칩을 통해 보여준 과감한 시도들에 대해 알아보겠습니다.
그록의 과감한 도박 : Memory Hierarchy의 고정관념을 붕괴시켜라
그록 LPU의 가장 큰 특징은 메모리 구조입니다. 조금 전 memory bandwidth가 매우 중요하다고 말씀드렸는데요. A100 GPU의 메모리 구조를 살펴보면 아래 그림과 같습니다.
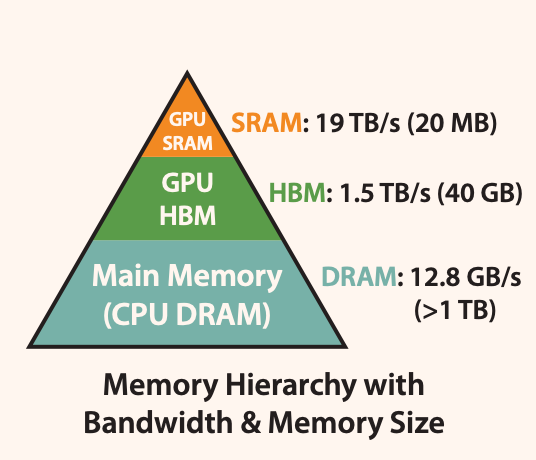
개별 GPU의 메모리 hierarchy는 GPU 칩 내부의 on-chip SRAM, GPU 칩과 붙어 있는 off-chip 메모리(HBM) 그리고 GPU 서버에서 구동 시 개별 노드에 할당된 시스템 메모리(DRAM)로 구성되어 있습니다. memory hierarchy에서 아래로 내려갈 수록 용량은 커지고 대역폭은 작아지며, 용량당 가격은 저렴해집니다. LLM 연산 진행시 가중치나 중간 연산값들은 대부분 HBM에 저장된 후 다시 읽어가며, HBM에서 읽은 데이터는 연산기와 가까이 있는 GPU SRAM에 cache 형태로 보관하여 재사용시 메모리 효율을 늘리는 형식으로 연산이 이루어집니다. 이는 CPU나 다른 전통적인 컴퓨터 구조에서도 채택해왔던 형식입니다.
엔비디아를 비롯한 대기업들과 많은 추론 칩 스타트업들이 HBM과 메모리를 더 효율적으로 쓸 수 있는 방법을 고민하였지만, 그록은 이러한 memory hierarchy에 의문을 품고 판을 뒤집는 질문을 던집니다.
??? : 모든 데이터를 칩 내부(On-chip)에 넣어버리면 안되나?
단순히 SRAM 용량을 늘리겠다는 것이 아닙니다. Off-chip 메모리를 사용하지 않겠다는 것입니다. 그록은 본인들의 칩에서 과감하게 위 계층구조의 가운데에 해당하는 HBM을 제거했습니다. 대신 칩 내부의 캐시 메모리로 쓰이는 SRAM을 메인 메모리로 사용합니다.
- HBM 대역폭 : B200 기준 8 TB/s
- LPU SRAM 대역폭 : 80 TB/s 이상 (최소 10배~20배 차이)
이 압도적인 대역폭을 활용하여 그록은 2020년 ISCA(컴퓨터 아키텍처 국제 학회)에서 ResNet 등의 이미지 분류 모델에서 GPU보다 뛰어난 성능을 증명했습니다.
문제 : 가격과 용량
하지만 on chip memory만 사용한다고 모든 문제가 해결되는 것은 아닙니다. SRAM만 사용해서 모든 문제가 해결된다면 이미 많은 하드웨어 기업들이 그 방법을 채택했을 겁니다. 문제는 비용입니다. SRAM과 DRAM 모두 같은 메모리처럼 보이지만, 그 구조를 보면 매우 다릅니다.
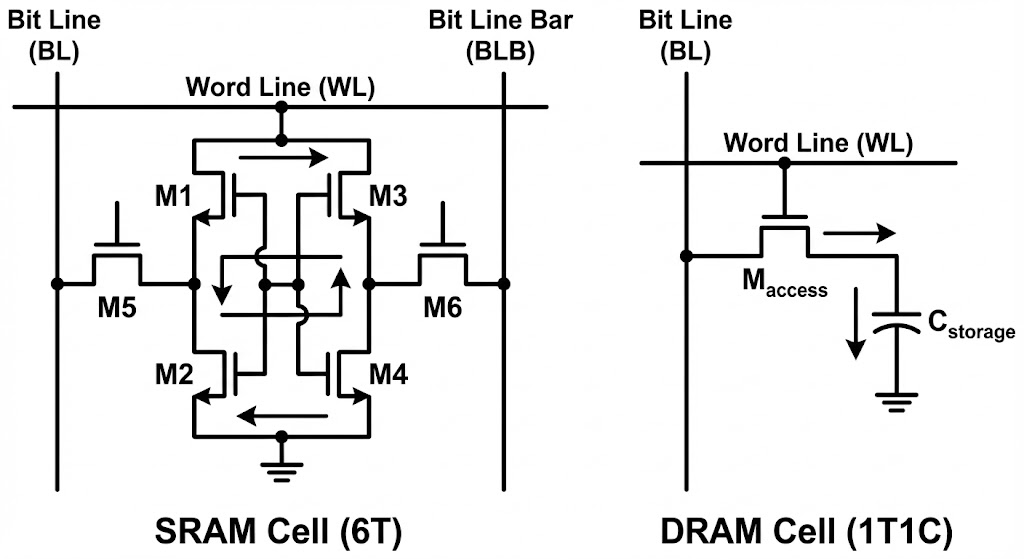
전자공학을 전공하신 분들이라면 한번쯤 보셨을 만한 이미지입니다. 간단하게 숫자로 설명하면 DRAM은 비트 하나를 저장하는 개별 cell당 1개의 트랜지스터와 1개의 캐패시터가 필요한 반면, SRAM은 cell당 6개의 트랜지스터가 필요합니다. 단순 부품 개수만 3배 차이이며, 배선 복잡도를 생각하면 차지하는 면적은 수십배까지 차이가 납니다. 때문에 SRAM 용량을 늘리게 되면 칩 사이즈가 커지게 되며, 이전 글에서 말씀드린 레티클 한계(Reticle limit)로 인해 용량을 늘리는데는 한계가 있습니다. 더군다나 SRAM 용량을 늘린다는 것은 칩 안에 SRAM이 차지하는 비율이 증가한다는 것입니다. 그만큼 연산에 필요한 로직들이 들어갈 자리가 줄어드는 것이죠. 메모리가 중요하다 한들 메모리만 있으면 연산을 할 수 없습니다. 이러한 한계로 개별 칩에는 SRAM을 많아야 HBM 용량의 1/10정도(수백MB)로 밖에 담지 못하는 것이 현실입니다.
최신 LLM 모델들은 기본적으로 수십억 규모의 parameter를 가집니다. 압축이 되어 있지 않다고 가정하고 간단히 계산해도 가중치를 저장하는데에만 수십GB 정도의 메모리가 필요하니 SRAM만 사용한다면 칩 하나에 모델 하나를 올리는 것 조차 불가능합니다.
해결책 : 쪼개서 저장하고, 컨베이어 벨트처럼 돌린다
그록은 이 문제를 Scale-out으로 해결했습니다. 칩 하나에 모델을 못 담으니, 수백 개의 칩에 모델의 가중치를 쪼개서(Sharding) 저장하는 것입니다. 여기서 AI 병렬화 기법이 등장합니다.
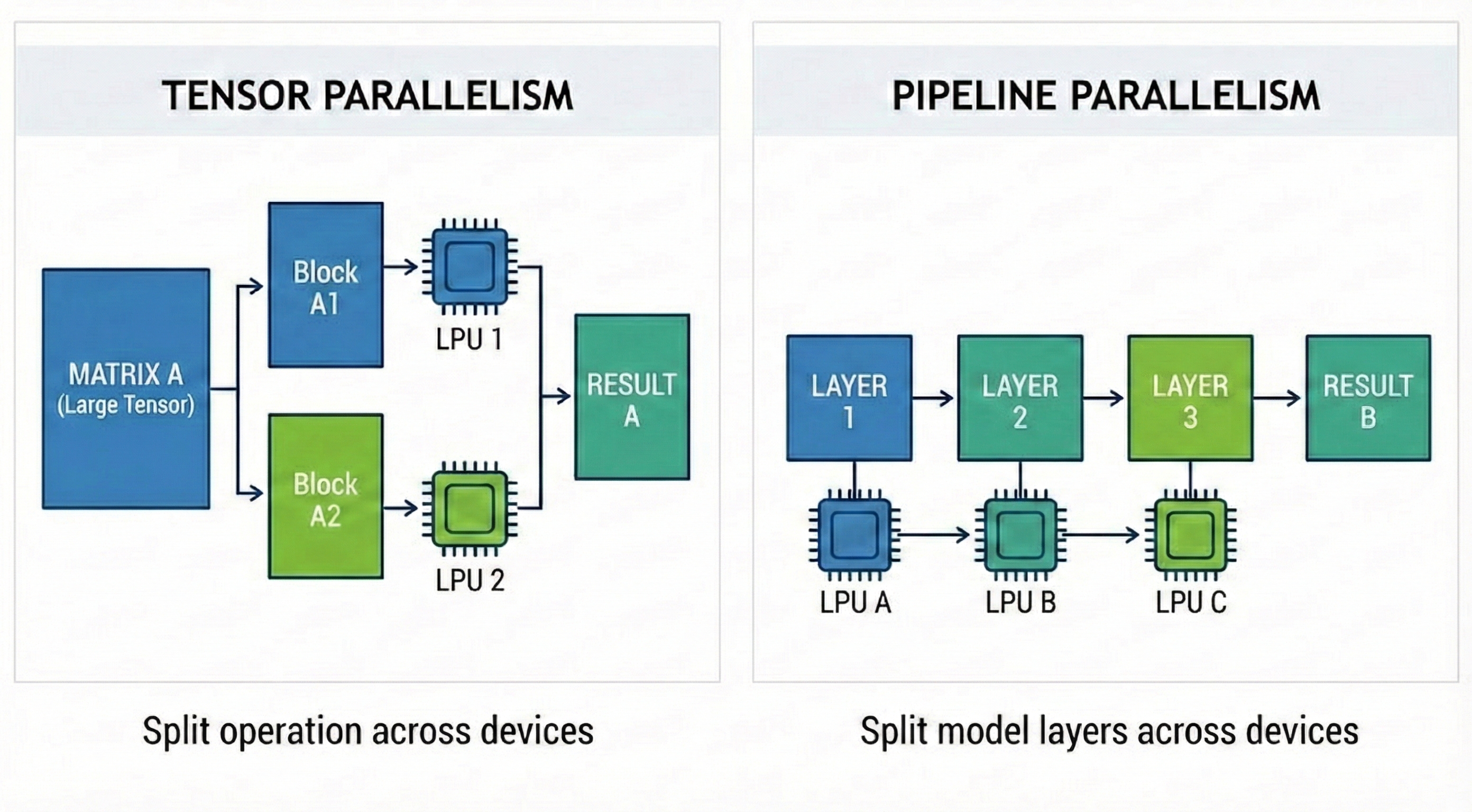
- Tensor Parallelism (TP) : 하나의 큰 행렬 연산을 여러개의 작은 행렬 연산으로 분해. 부분적 행렬 연산에 필요한 가중치를 여러 칩의 메인 메모리에 나눠서 저장하고 각 칩이 부분적 행렬 연산 수행.
- Pipeline Parallelism (PP) : 모델의 레이어(Layer)를 그룹 별로 나누어 처리. 연산 순서 별로 각 칩은 이전 칩에서 연산된 결과를 받아서 다음 레이어에 대한 연산 수행
그록은 이 병렬화 기법을 적용한 그들의 시스템을 거대한 컨베이어 벨트에 비유합니다. 입력 데이터가 첫 번째 칩(벨트의 시작)에 들어가면, 각 칩은 본인이 맡은 연산만 수행하고 옆 칩으로 데이터를 넘깁니다. 마지막 칩에서 최종 토큰이 튀어나오는 구조입니다. 이를 애니메이션으로 나타내면 아래와 같습니다.
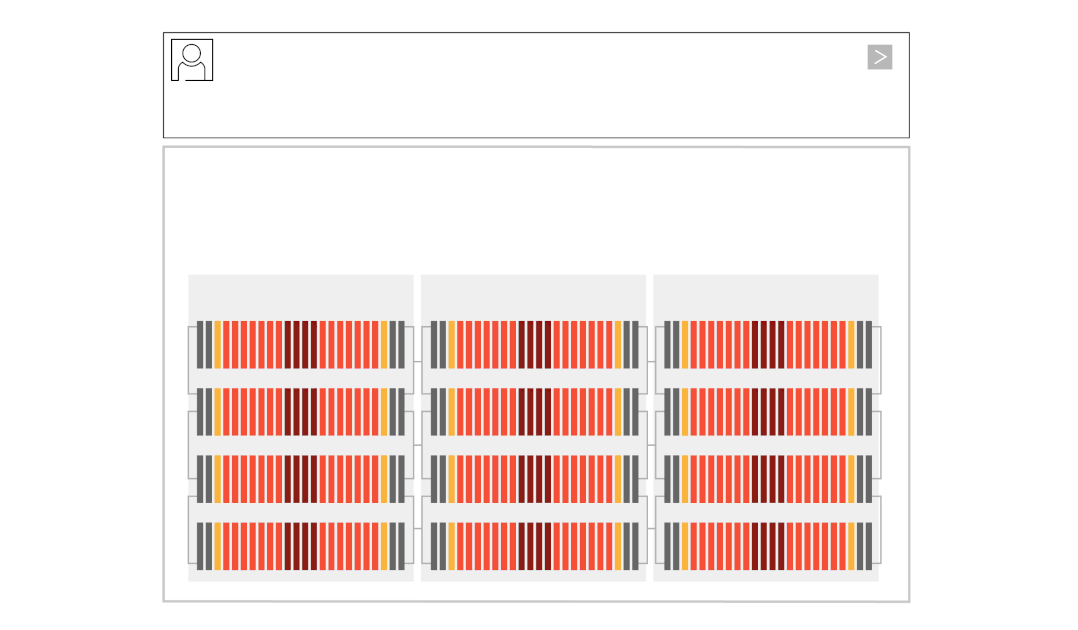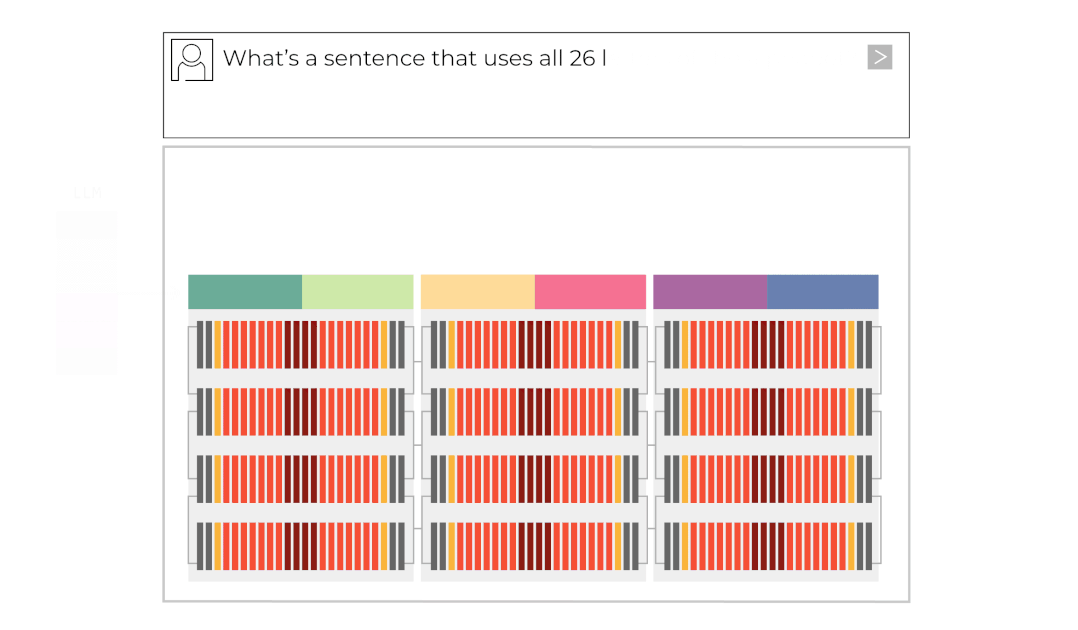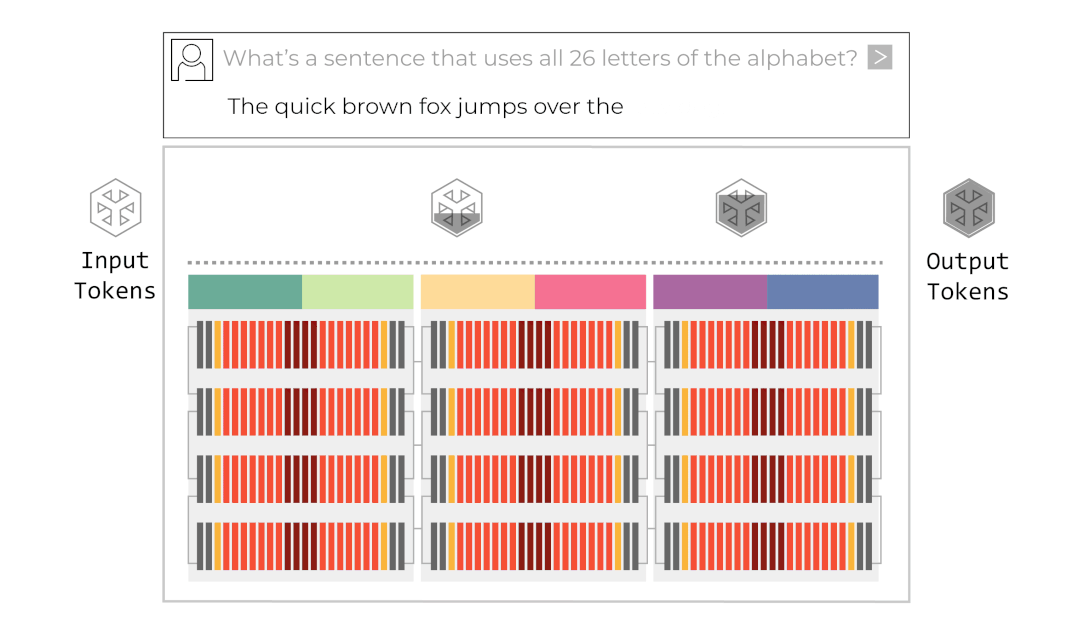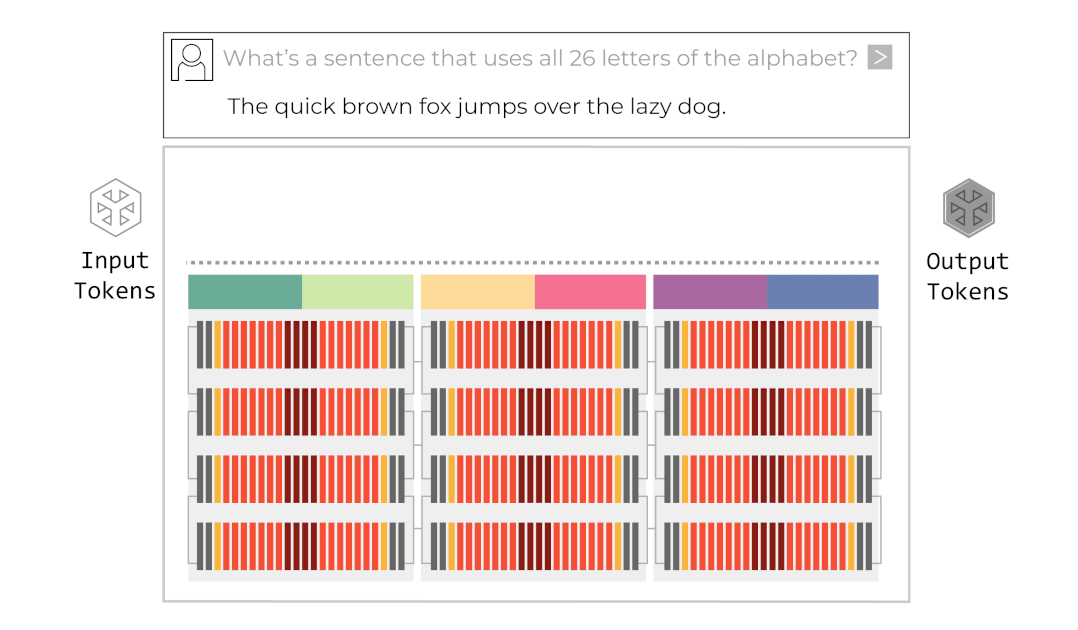
반면 GPU의 단일 칩에서 같은 작업을 수행하려 한다면
HBM에서 memory load -> 연산 -> 다시 HBM에서 memory load -> 연산
이 과정을 반복해야 합니다. HBM에 연산에 필요한 데이터들은 저장하고 있지만, 연산기 근처(SRAM)에 load할 수 있는 데이터의 용량에는 마찬가지로 한계가 있기 때문입니다. 이로 인해 반복적으로 memory load가 이뤄지는 과정에서 병목이 발생하는 것이 그록의 주장입니다. 이를 애니메이션으로 나타내보면 아래와 같습니다.
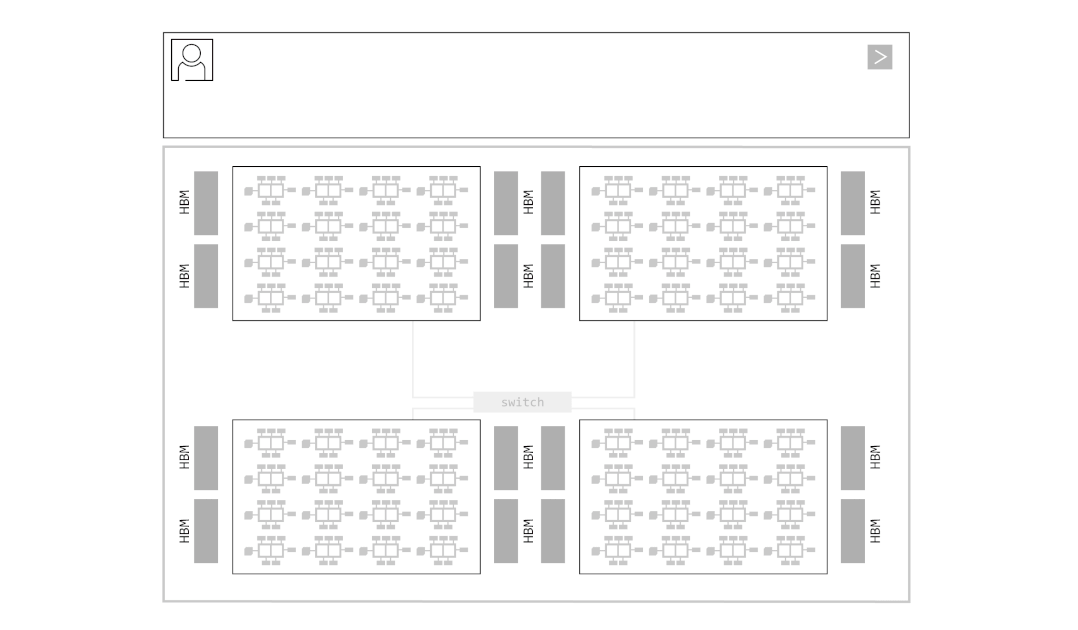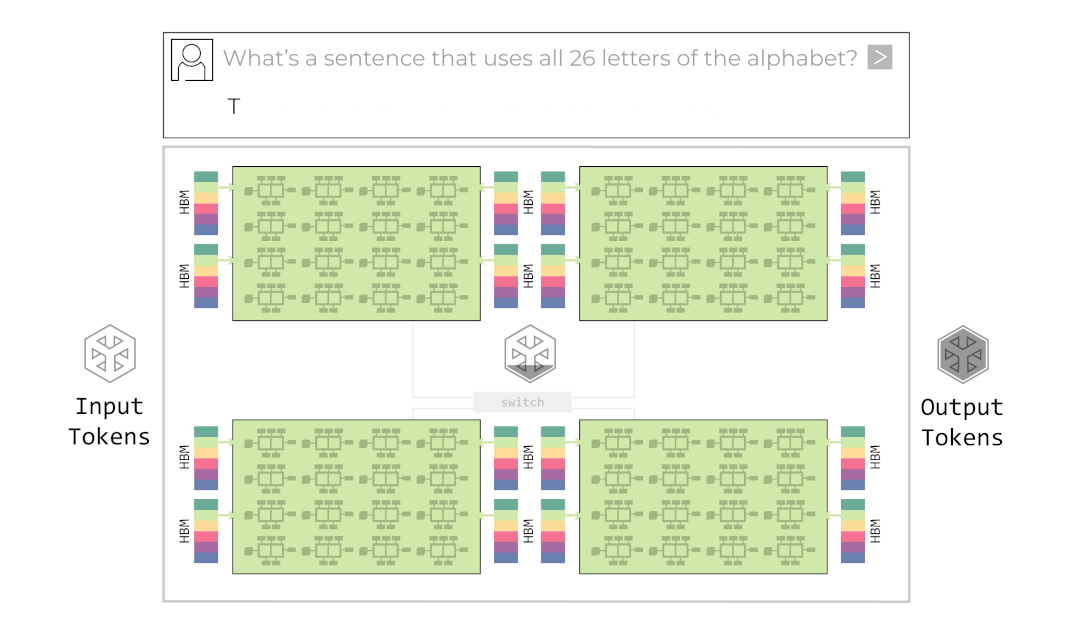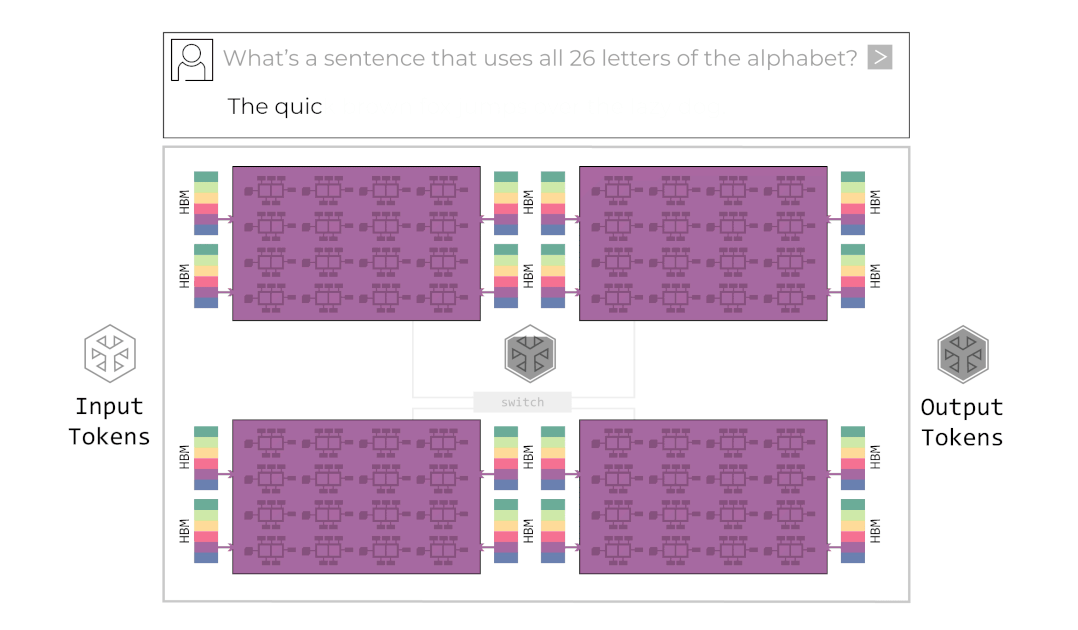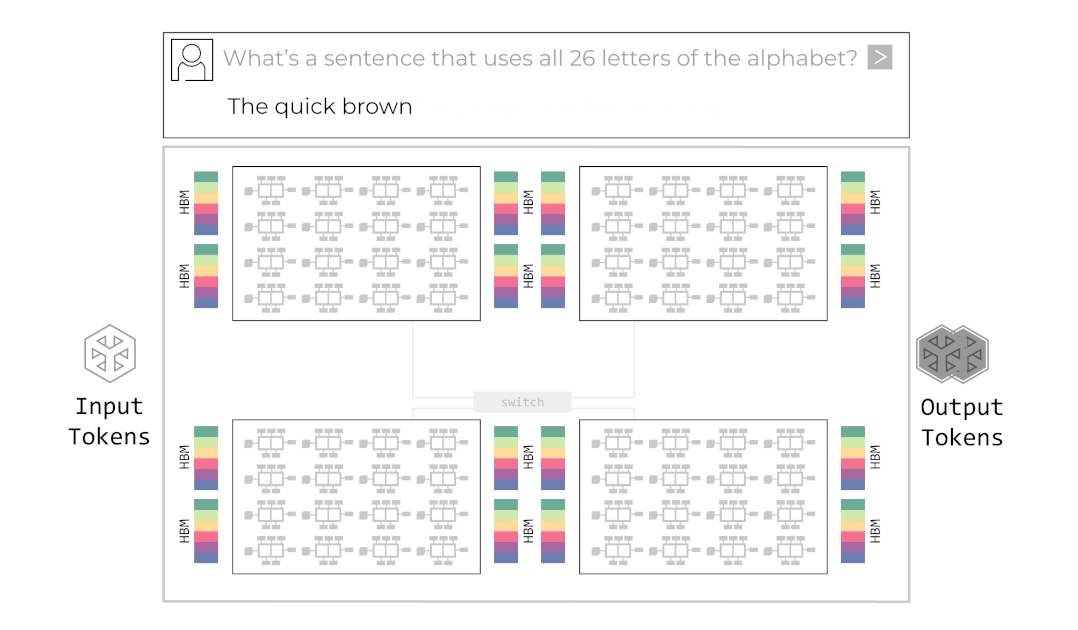
그록의 시스템이 성공적으로 동작하기 위해서는 칩 간 통신(Chip-to-Chip, C2C) 속도가 생명입니다. 컨베이어 벨트 중간이 끊기면 공장 전체가 멈추니까요. 그록은 독자적인 C2C 인터커넥트 기술(RealScale)과 Dragonfly Topology를 통해 8개 이상의 칩을 하나의 거대한 노드처럼 묶었습니다. 여러 개의 칩이 서로의 SRAM을 공유하는 거대한 단일 칩처럼 보이게 하여 통신 오버헤드(Communication Overhead)를 거의 0에 수렴하게 만든 것입니다.
GPU도 이러한 방식을 사용하지 못하는 것은 아닙니다. 앞서 설명드린 TP와 PP는 GPU를 이용한 분산 학습에서 널리 사용되는 병렬화 방식입니다. 다만 GPU에서는 이러한 기법(특히 TP)를 사용할 때 device간 data sync를 맞추기 위한 작업이 필요합니다. GPU는 런타임 라이브러리인 NCCL(Nvidia collective communication library)를 통해 GPU간 통신을 지원합니다. 앞서 말씀드린 TP를 사용하는 과정에서는 각 GPU에서 연산된 행렬 곱셈 결과를 다른 GPU들과 공유하여서 summation을 구하는 과정, all-reduce가 필요합니다.
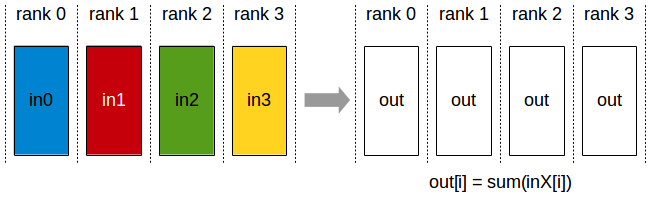
하지만 그록의 LPU에서는 엔비디아에서 사용하는 NCCL과 같은 런타임 라이브러리가 불필요합니다. LPU에서는 device간 통신이 NCCL과 같은 런타임 라이브러리에서 이뤄지는 것이 아닌 컴파일 타임에서 예측 가능하기 때문인데요. 어떻게 가능한 것인지 그록의 또다른 아키텍쳐 철학을 통해 알아보도록 하겠습니다.
Software-defined Hardware : 컴파일러가 모든 것을 결정한다
그록 LPU의 또 다른 특징은 하드웨어 설계보다 소프트웨어(특히 컴파일러)가 우선한다는 점입니다. 실제로 LPU의 설계 철학을 담은 공식 문서를 보면 컴파일러 아키텍쳐가 디자인 되기 전에 칩 디자인은 건들지조차 하지 않았다고 합니다. 이는 컴파일러가 모든 하드웨어를 컨트롤 가능하고 개별 하드웨어 동작들이 컴파일러 레벨에서 예측가능하도록 하기 위함입니다.

Deterministic Execution (결정론적 실행)
CPU나 GPU는 언제 어떤 데이터가 들어올지 모르기 때문에, 하드웨어 레벨에서 복잡한 스케줄러(Branch Prediction, Cache Managing, Warp Scheduling 등)를 사용합니다. 이는 유연하지만, 예측 불가능한 지연(Tail Latency)을 만듭니다.
잠시 1편에서 등장한 GPU의 warp scheduling 예시를 다시 보겠습니다.
(본 예시는 단순한 설명을 위한 것이며, 실제 하드웨어 동작과는 다를 수 있습니다.)

이전에 소개드린 warp scheduling에서 메모리에 데이터를 읽고 쓰는 load/store 명령은 비동기적으로 일어납니다. 이는 근본적으로 메모리 load/store 명령이 언제 완료될지 모르기 때문입니다. 그 동안 프로세서는 어쩔 수 없이 비동기적 명령이 완료될 때까지 기다려야 하는 것이죠. 하지만, 이 명령이 완료되는 시점을 알 수 있다면, stall해야 하는 시간을 정확히 예측할 수 있다면? 프로세서는 그 시간 동안 할 수 있는 일을 계산하여 다른 일을 하면서 idle한 프로세스를 최소화하고 시스템을 최적화할 수 있을 것입니다.
LPU의 정적 스케줄링(static scheduling)은 바로 딥러닝과 LLM, 그중에서도 추론 연산에 이를 적용하는 것을 목적으로 합니다. 앞서 언급드렸듯이 추론 연산은 고정된 가중치를 통해서 최종 결과값(LLM에서는 output token)을 계산하는 과정입니다. 이 과정에서 모델이 고정되어 있다면 연산 순서는 대체로 고정되어 있습니다. 고정된 연산 순서는 정적 스케줄링을 적용하기 위한 최적의 조건 중 하나입니다. 연산 중간에 발생할 수 있는 스케줄링을 걷어낼 수 있기 때문입니다. 이렇게 되면 한정된 하드웨어 자원을 스케줄링이 아닌, 연산 유닛이나 메모리 등 다른 유닛으로 활용할 수 있기 때문에 하드웨어 효용성도 증가합니다.
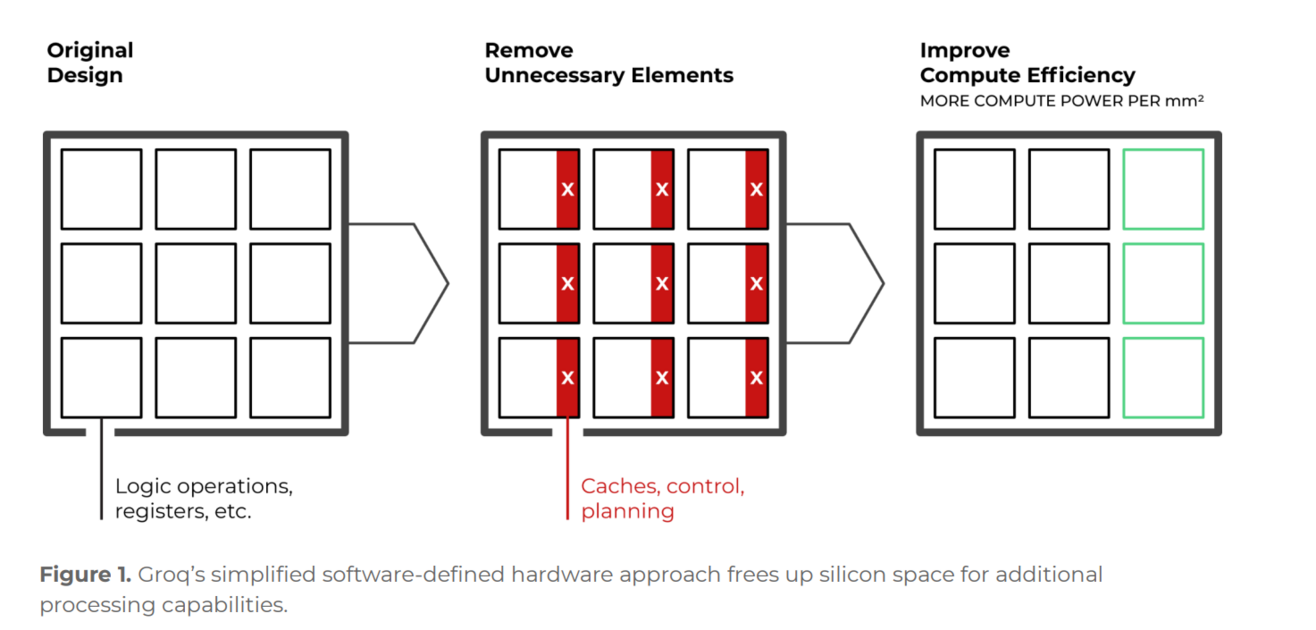
이러한 정적 스케줄링의 효과는 칩 여러개를 동시에 사용하는 상황에서 더 빛을 발휘합니다.
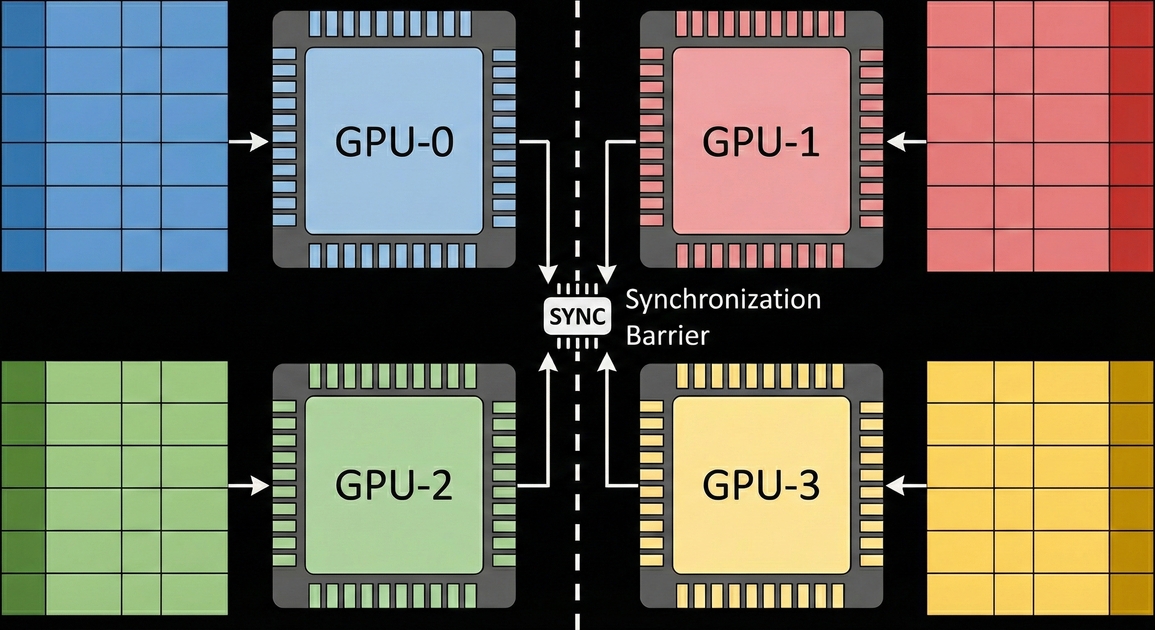
직전에 이야기한 엔비디아의 NCCL 라이브러리를 통해 all-reduce/all-gather를 사용하는 과정에서는 장치간 동기화(synchronization)이 필요합니다. 이는 모든 장치에서 작업이 끝나야 다음 작업을 수행할 수 있지만, 각 장치에서 언제 작업이 끝날 지 모르기 때문입니다.
하지만 컴파일러가 각 장치에서 작업이 완료되는 시점까지 알 수 있다면 어떨까요? NCCL에서 작업 중 필요한 동기화 작업은 물론 NCCL에서 필요한 작업까지 컴파일러 단에서 수행할 수 있을 것입니다.
이러한 이유로 그록은 하드웨어의 ‘뇌’에 해당하는 스케줄링 기능을 최소한으로 남기고, 이 기능을 컴파일러에게 위임했습니다. 지금까지 설명한 그록 LPU의 정적 스케줄링을 요약해보면 아래와 같습니다.
- 컴파일러는 컴파일 시점에 칩 내부, 나아가 사용할 모든 칩간의 데이터 흐름을 하드웨어 시간 단위(clock cycle)로 미리 계산합니다.
- 데이터가 언제, 어느 칩의, 어느 메모리 주소에 도착할지 100% 예측 가능합니다(Deterministic).
- 하드웨어는 복잡한 고민 없이 컴파일러가 시키는 대로만 실행합니다.
- LPU는 실행 시간의 예측 가능성을 확보하고, 스케줄링에 해당하는 하드웨어 자원을 연산에 집중시킬 수 있게 되었습니다.
엔비디아는 왜 그록을 인수했을까?
그록의 LPU는 기술적으로는 혁신적이고 뚜렷한 강점을 갖고 있었지만, 비즈니스적으로는 난관이 있었습니다. 고객사 입장에서 LPU로 LLM 모델 하나만 돌린다 하더라도 수백 개의 칩(Rack 단위)이 필요하므로 초기 도입 비용이 수십~수백억 원에 달했기 때문입니다. 이러한 문제 때문인지 그록은 사업 초기에는 칩(GroqChip) 판매를 진행했지만, 이후 사업 다각화를 통해 GroqCloud를 통해 클라우드 API 임대 사업을 해왔습니다. 본인들이 그록칩을 통해 직접 구축한 서버나 랙을 사용할 수 있는 API를 제공하는 것입니다.
그렇다면 엔비디아가 이 그록을 인수한 배경은 무엇일까요? 일반적인 경제 기사에서는 추론 시장 지배력 확대를 위한 기술 라이선싱이라는 의견이 지배적입니다. 하지만 저는 엔지니어로서 기술적 상상력을 조금 가미하여 그록 인수 이후 펼쳐질만한 몇 가지 기술적 시나리오에 대해 이야기해보며 오늘 글을 마무리하도록 하겠습니다.
가설1 : 새로운 이종 컴퓨팅(Heterogeneous Computing) 플랫폼 구축
최근 AI 추론 연산 트렌드 중 하나는 Prefill과 Decoding의 연산 분리(prefill-decode disaggregation)입니다. 이는 추론 연산 안에서도 특성이 다른 작업이 혼재되어 있기 때문입니다.
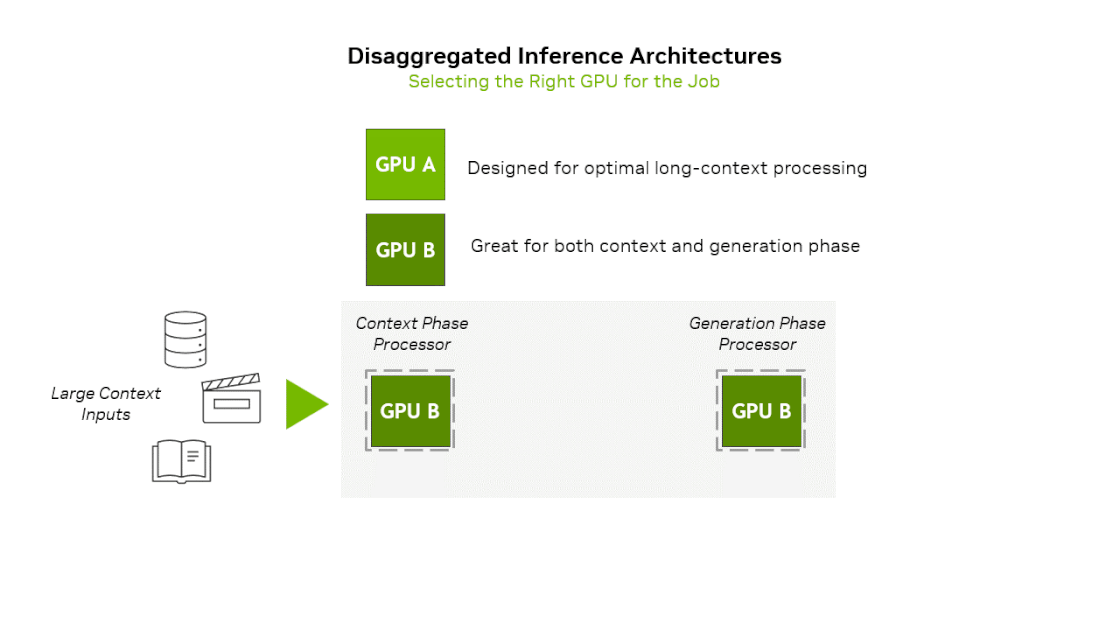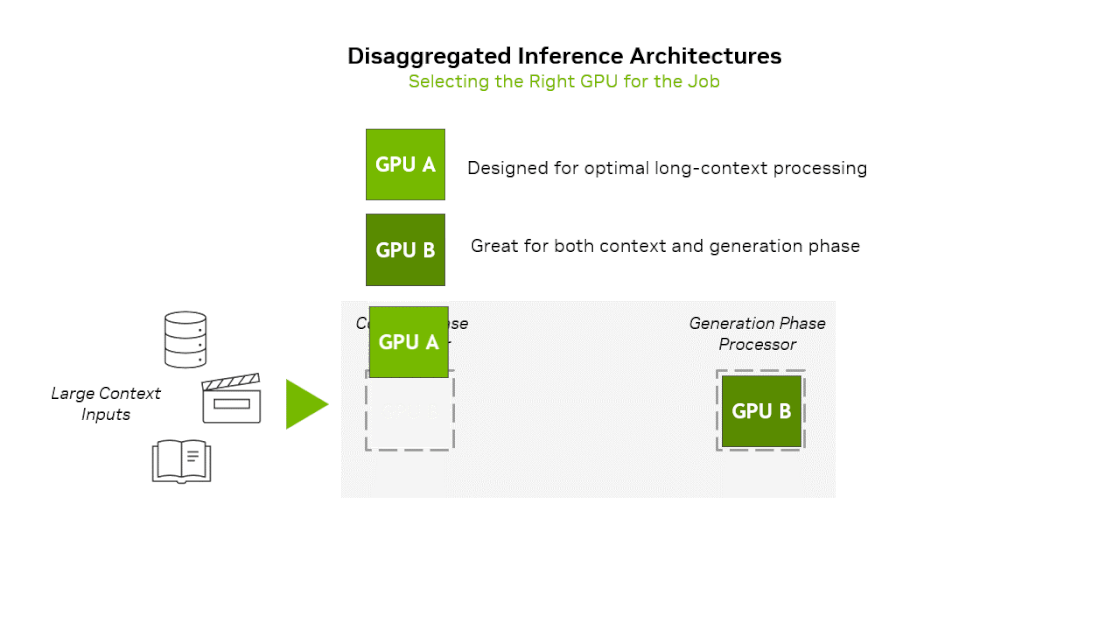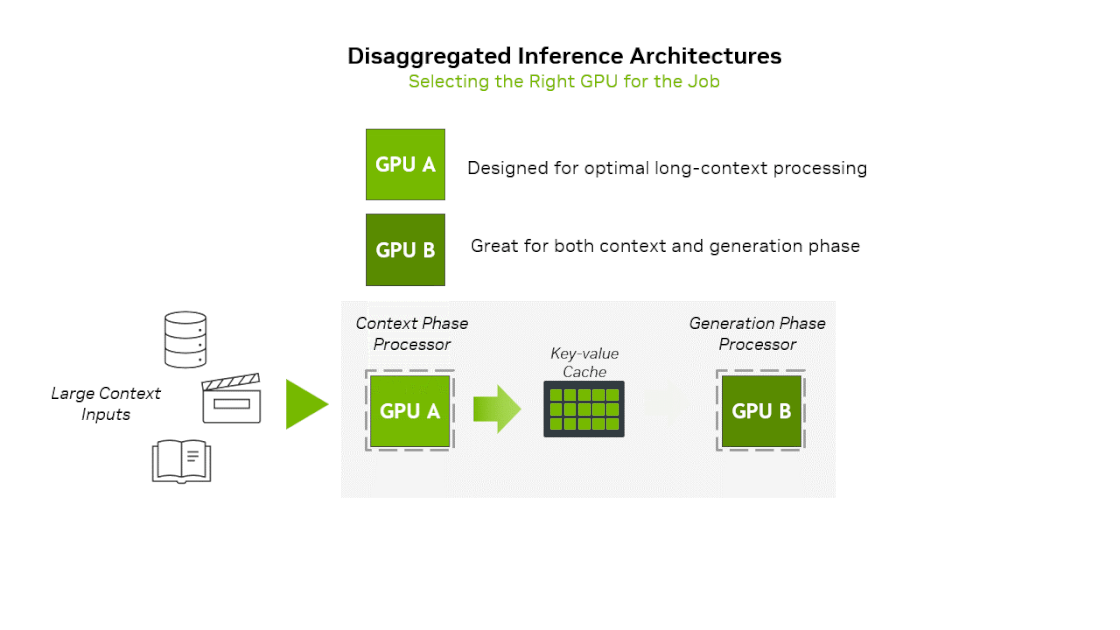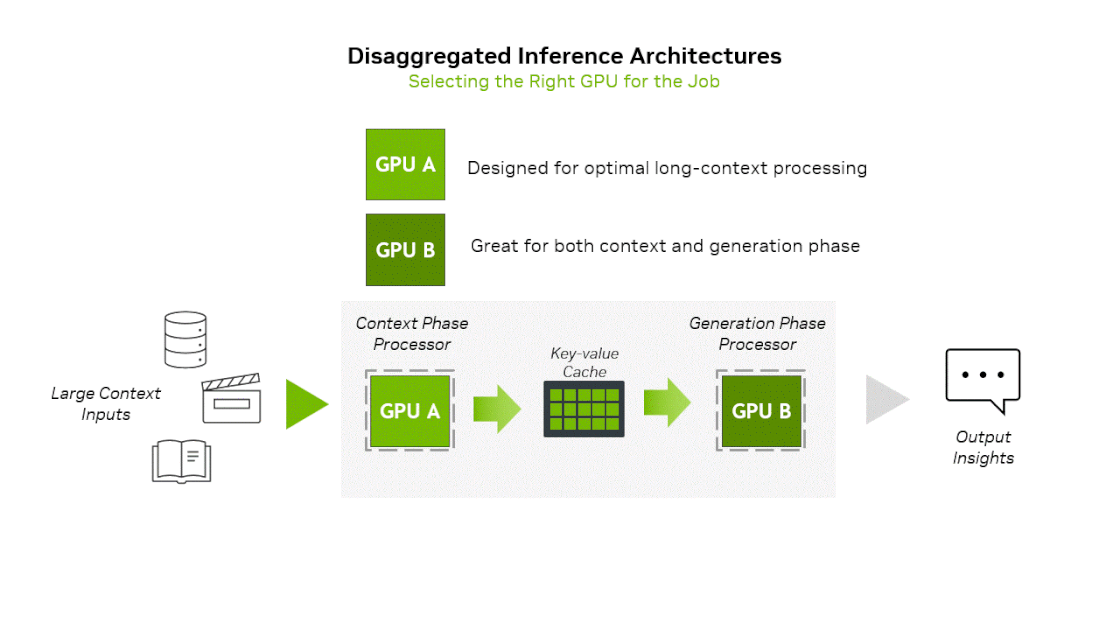
- Prefill(Context) phase : 입력 프롬프트를 한 번에 집어넣어서 많은 연산 필요 → Compute Bound
- Decoding(Generation) phase : 첫 토큰 생성 이후 생성되는 토큰을 하나씩 순차적으로 입력 → Memory Bound

엔비디아는 작년말 prefill과 decode별로 다른 연산기를 사용하는 이종 하드웨어 플랫폼을 공개한 바 있습니다. 차세대 GPU 아키텍쳐인 Rubin 아키텍쳐를 기반으로 context-phase에 특화하여 제작한 Rubin CPX를 공개하며 이것이 탑재된 플랫폼을 같이 공개하였습니다. 해당 플랫폼의 아이디어를 요약하면 Prefill stage는 Rubin CPX → Decoding stage는 Rubin GPU에서 실행하는 것입니다. 이 플랫폼에 그록의 LPU 아키텍쳐를 활용한다면 아래와 같은 2가지 방식의 새로운 플랫폼을 상상해볼 수 있습니다.
- 현재 플랫폼에 Rubin GPU 대신 GPU + LPU 혼합 하드웨어(Rubin LPU) 장착
- Rubin CPX → Prefill
- Rubin LPU → Decoding
- 현재 플랫폼에 1에서 언급한 하드웨어 추가
- Rubin CPX → Prefill
- Rubin LPU → Decoding
- Rubin GPU → Prefill + Decoding
하지만 현실적으로 위와 같은 플랫폼 구축을 위해서는 어려움이 많을 것으로 예상됩니다. LPU와 GPU의 하드웨어 아키텍쳐간 차이가 크기 때문에 단일 플랫폼 내 통합이 쉽지 않기 때문입니다. 따라서 저는 이 시나리오보다는 다음에 소개할 시나리오가 더 가능성이 높다고 생각합니다.
가설2 : 하이브리드 AI 기가 팩토리 구축

엔비디아는 단순 하드웨어 기업에서 나아가 직접 데이터센터를 구축하고 있습니다. 엔비디아가 준비중인 이른바 AI 기가 팩토리는 그들의 하이퍼스케일러(Meta, Google, Amazon)들이 구축하는 데이터센터를 본인들이 직접 구축하여 다른 고객들에게 제공하기 위한 플랫폼입니다. 그록이 제공한 GroqCloud API의 확장된 버전이라고 생각하시면 되겠습니다.
데이터센터 구축은 단순 하드웨어 지식을 넘어 시스템 전반에 대한 이해, 고객사 경험 등 다양한 유/무형 자산을 필요로 하기 때문에 이를 할 수 있는 기술력을 갖춘 회사들은(특히 하드웨어 회사들 중에서는) 많지 않습니다. 보통 하이퍼스케일러들이 데이터센터를 구축하면서 본인들의 노하우나 기술력을 구축한 경우가 대부분입니다. 그록은 실제로 본인들의 추론 칩으로 데이터센터를 구축하고 실제 API를 제공한 하드웨어 기업입니다. 엔비디아 입장에서 그록을 인수하게 된다면 본인들의 기가 팩토리에 들어갈 하드웨어 라인업을 확장할 수 있습니다.
앞서 말한 이종 컴퓨팅을 서버나 노드 단위가 아닌 데이터센터 단위로 확장해본다면
- 학습을 비롯한 GPU 특화된 작업은 GPU 클러스터에서 연산
- LPU에서 더 빠르게 진행할 수 있는 작업은 LPU 클러스터에서 연산
그러면 LPU가 더 빠르게 진행할 수 있는 작업은 무엇이 있을까요? 이전에 이야기한 LLM 추론 연산 자체의 관점에서 본다면 추론 과정 중 Prefill/Decoding 작업을 GPU와 LPU 클러스터가 분리해서 진행하는 것을 생각해볼 수 있습니다. 이번에는 추가로 작업 단위의 관점에서 LPU가 강점을 지닐만한 workload 몇개를 소개해볼까 합니다.
(여기부터는 제 사견이 많이 반영되어 있습니다.)
Speculative Decoding
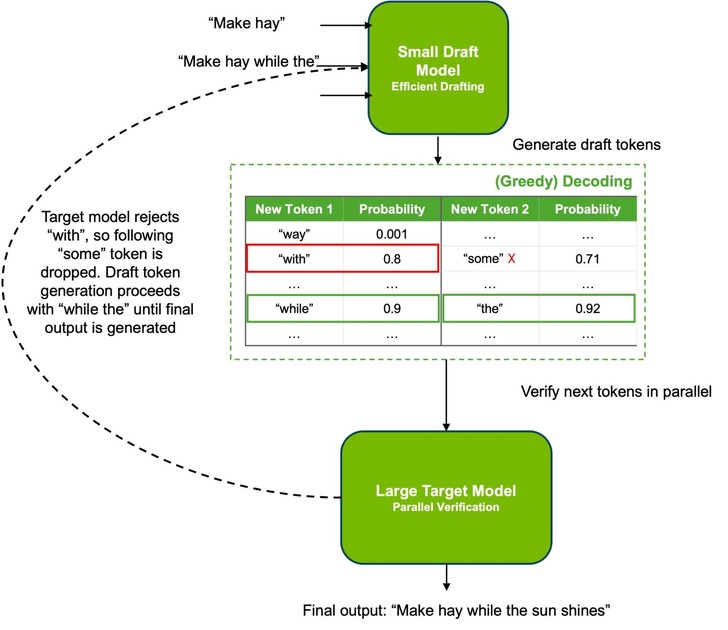
최근 LLM 서빙의 트렌드 중 하나는 Speculative Decoding(추측 디코딩)입니다. 모델 사이즈가 커지면서 연산 시간이 오래 걸리다보니 기존 모델(Target Model)을 증류하거나 비슷한 동작을 하도록 훈련된 작고 빠른 모델(Draft Model)이 문장의 뒷부분을 미리 빠르게 생성하면, Target Model이 이를 병렬로 검증하는 방식입니다. 그록의 LPU 클러스터는 여기서 작은 사이즈의 Draft Model 연산에 사용될 수 있습니다. LPU는 작은 사이즈의 모델에서 압도적인 토큰 생성 속도를 자랑하기 때문입니다. 전체적인 관점에서 LPU/GPU 클러스터의 역할을 구분해보면 아래와 같습니다.
- LPU : 빠른 속도로 후보 토큰들을 생성
- GPU : LPU에서 던져준 토큰들이 맞는지 한 번에 검증
다만 이러한 시스템은 근본적으로 한계가 있습니다. GPU - LPU 클러스터간 통신 오버헤드 때문이데요. LPU가 생성한 토큰들만 GPU로 던져주면 오버헤드가 크지 않겠지만, Speculative decoding의 Target Model은 토큰 검증을 위해 Draft Model에서 생성된 데이터(KV cache)들을 필요로 합니다. 하나의 칩이나 노드 안에서 통신이 이뤄진다면 오버헤드가 상대적으로 적겠지만, 클러스터끼리 통신에서 대용량의 KV cache 이동이 필요하다면 오버헤드가 커지는 것은 큰 문제입니다. 서비스 자체의 성능을 오히려 저하시킬 수 있기 때문입니다. 이는 speculative decoding 뿐만 아니라 prefill-decode disaggregation을 클러스터 단위로 수행하는 경우에 공통적으로 고민해야 하는 문제이기도 합니다.
더욱이 최근 speculative decoding은 위에서 설명한 target-draft 방식으로 모델을 분리하지 않고 단일 모델에서 내부 최적화를 통해 이를 적용하는 방식으로 변모하면서 이종 컴퓨팅을 사용하기 어려운 환경으로 변화하고 있습니다.
Agentic AI
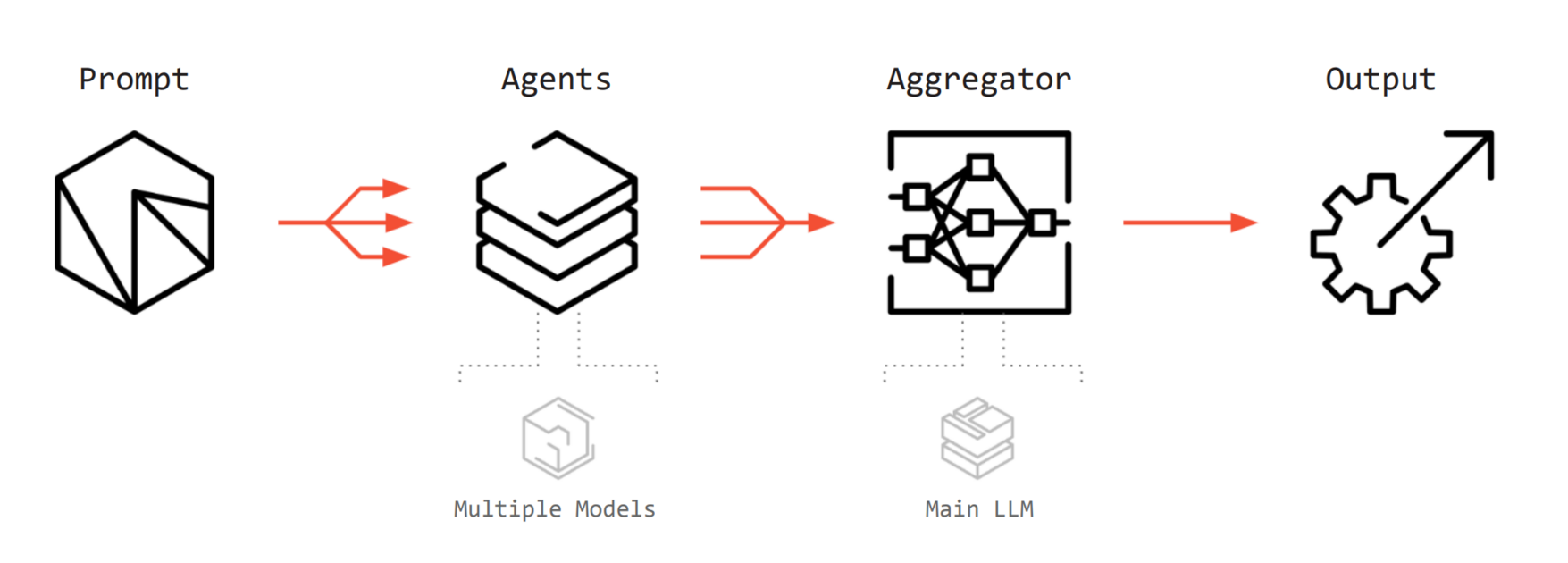
또 다른 시나리오는 Agentic AI입니다. AI는 단순히 답변만 하는 챗봇을 넘어, 스스로 계획을 세우고 도구를 사용하며 여러 단계의 추론을 거치는 에이전트 형태로 진화하고 있습니다. 계획을 세우고, 도구를 사용하는 각각의 단계에서 크고 작은 모델들이 각자 생성한 데이터를 주고받는 최종 결과물을 생성하게 됩니다. 다양한 모델이 사용된다는 관점에서 직전에 언급한 Speculative Decoding과 비슷하게 이종 컴퓨팅을 사용하는 시나리오를 생각해볼 수 있습니다.
- LPU : 단순한 판단, 도구 선택, 반복적인 루틴 작업, 라우팅(Routing) 등 빠른 반응이 필요한 가벼운 에이전트 작업(Worker)을 담당
- GPU : 복잡한 논리 추론, 코드 생성, 이미지 렌더링 등 막대한 연산이 필요한 무거운 작업 담당
Agentic AI 시스템은 KV cache와 같은 텐서 형태가 아닌 텍스트(JSON) 기반으로 통신하기 때문에 물리적인 하드웨어 분리가 자유롭습니다. Speculative decoding에서 이야기한 병목인 통신 오버헤드에 대한 우려가 적기 때문입니다. 때문에 LPU + GPU 클러스터를 결합한다면 Agentic AI 서빙에 최적화된 데이터센터 플랫폼을 구성할 수 있을 것으로 생각됩니다.
정리
이번 글에서는
- LPU의 등장 배경과 범용칩/전용칩의 차이
- 그록의 하드웨어/소프트웨어 설계 철학
- 엔비디아의 그록 인수 이후 예상되는 몇가지 기술적 시나리오
위 3가지에 대해 알아보았습니다.
개인적으로 이번 인수건은 엔비디아가 자본력으로 하드웨어 시장에서 독점적 지위를 유지하기 위한 움직임으로 보여 무서운 감정이 들면서도, 저희 회사에서도 사용하는 LPU라는 용어가 시장과 대중들에게 한번 더 알려지는 계기가 된 듯 하여 양가적인 감정이 들게 하는 뉴스였습니다. 시장에서 저희 제품을 증명하게 된다면 저희 회사에게도 큰 기회가 많이 열릴 것이라는 기대감도 들었습니다.
총 3편에 걸쳐 엔비디아의 GPU, 구글의 TPU, 그리고 그록의 LPU까지 다양한 AI 가속기에 대해 살펴보았습니다. 지금까지는 가속기의 아키텍쳐와 연산 구조에 중점을 두었지만, 다음 글에서는 연산 바깥에서 가속기만큼 중요한 역할을 하는 스토리지로 주제를 확장해보고자 합니다. 다음 편에서는 올해 CES에서 주목을 받은 엔비디아의 BlueField를 중심으로, AI 데이터센터에서 중요한 역할을 담당하는 스토리지와 DPU(Data Processing Unit)에 대해 알아보겠습니다.
추신 : HyperAccel은 채용 중입니다.
저희 HyperAccel은 LPU 첫 제품 출시를 목전에 두고 있습니다. 이번 제품뿐만 아니라 앞으로 나올 다른 제품 개발을 위해서도 HyperAccel은 더 많은 훌륭한 엔지니어를 필요로 하고 있습니다.
저희가 다루는 기술들을 보시고, 관심이 있으시다면 HyperAccel Career로 지원해 주세요!
HyperAccel에는 정말 훌륭하고 똑똑한 엔지니어분들이 많습니다. 여러분의 지원을 기다립니다.
Reference
Jonathan Ross Interview
Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads, ISCA 2020
A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning, ISCA 2022
What is Language Processing Unit? - groq blog
groq whitepapers
Speculative Decoding - Nvidia blog
Rubin CPX platform - Nvidia blog
NCCL Collective Operations