
지피지기면 백전불태 1편: GPU의 역사와 기초
지피지기면 백전불태(知彼知己 百戰不殆)
상대를 알고 나를 알면 백 번 싸워도 위태롭지 않다는 뜻입니다.
이 시리즈는 AI 가속기 설계를 위해 경쟁사들의 하드웨어를 깊이 이해하는 것을 목표로 합니다.
첫 번째 글에서는 가장 강력한 경쟁자인 NVIDIA GPU를 다룹니다.
2020년대 핫 이슈를 이야기할 때 NVIDIA GPU를 빼놓을 수 없습니다.
AI 반도체 설계 회사로서 NVIDIA와 경쟁하려면,
먼저 NVIDIA가 어떻게 여기까지 왔는지, 그리고 GPU가 어떤 장치인지를 이해해야 합니다.
이 첫 번째 글에서는 NVIDIA GPU가 어떻게 탄생했고, 어떤 아키텍처 선택이 오늘의 위치를 만들었는지 살펴보고,
하드웨어 엔지니어 관점에서 이 설계의 강점과 구조적 특성을 정리합니다.
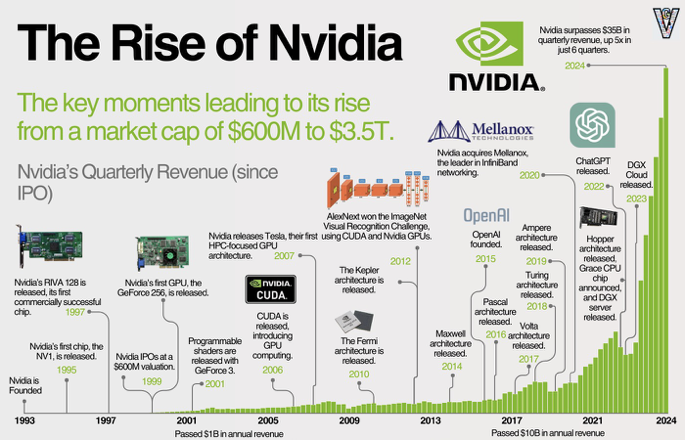
NVIDIA는 1993년 설립되어 1995년 NV1로 그래픽 시장에 진입했습니다.
RIVA 128(1997)과 GeForce 256(1999)으로 PC 그래픽 카드 시장에 자리를 잡았지만,
GeForce FX 시리즈 실패로 큰 위기를 맞았습니다.

이 실패를 딛고 NVIDIA는 GPU 아키텍처를 재구축하며 G80 Tesla 아키텍처와 CUDA를 선보였습니다.
이 전환으로 GPU는 “그냥” 그래픽 칩에서 벗어나 HPC와 GPGPU 시장까지 지배할 수 있는 플랫폼이 되었습니다.
2012년, GPU로 훈련한 AlexNet이 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)에서 우승하며
GPU는 딥러닝과 떼려야 뗄 수 없는 관계가 되었습니다.
2022년 ChatGPT 출시로 생성형 AI가 대중화되면서, AI 하드웨어 시장이 사실상 NVIDIA 중심으로 통합되었고,
NVIDIA는 세계 시가총액 1위 기업으로 올라섰습니다.
오늘날 NVIDIA GPU는 더 이상 “그냥 그래픽 가속기"가 아닙니다.
AI 인프라 레이어를 사실상 지배하는 범용 병렬 컴퓨팅 플랫폼 이며,
우리 관점에서는 새로운 가속기가 반드시 넘어야 할 기준점(baseline) 입니다.
그렇다면 GPU는 어떻게 탄생했고, 어떻게 확산되면서 AI 시장까지 진입하게 되었을까요?
그래픽 카드의 탄생

초창기 대중화된 컴퓨터는 CLI(Command Line Interface) 방식을 사용했습니다.
화면은 대부분 초록색 글자와 검은색 배경이었고, 그래픽 작업은 거의 없었죠.
그래서 CPU가 다른 작업을 처리하면서 화면 업데이트까지 함께 할 수 있었습니다.
하지만 CLI는 사용자가 명령어를 외워야 해서 진입장벽이 높았고, 대중적 매력이 부족했습니다.
Xerox의 Alto, Apple의 Lisa 같은 시스템이 윈도우, 아이콘, 마우스를 갖춘 GUI(Graphic User Interface) 시대를 열었습니다.
GUI는 사용성을 크게 개선했지만, CPU 부담이 늘어났습니다.
이에 발맞춰 IBM 같은 제조사들이 메인보드의 그래픽 회로를 점점 강화해 나갔고,
VGA(Video Graphics Array)에 이르러서는 그래픽이 PC의 핵심 구성 요소가 되었습니다.
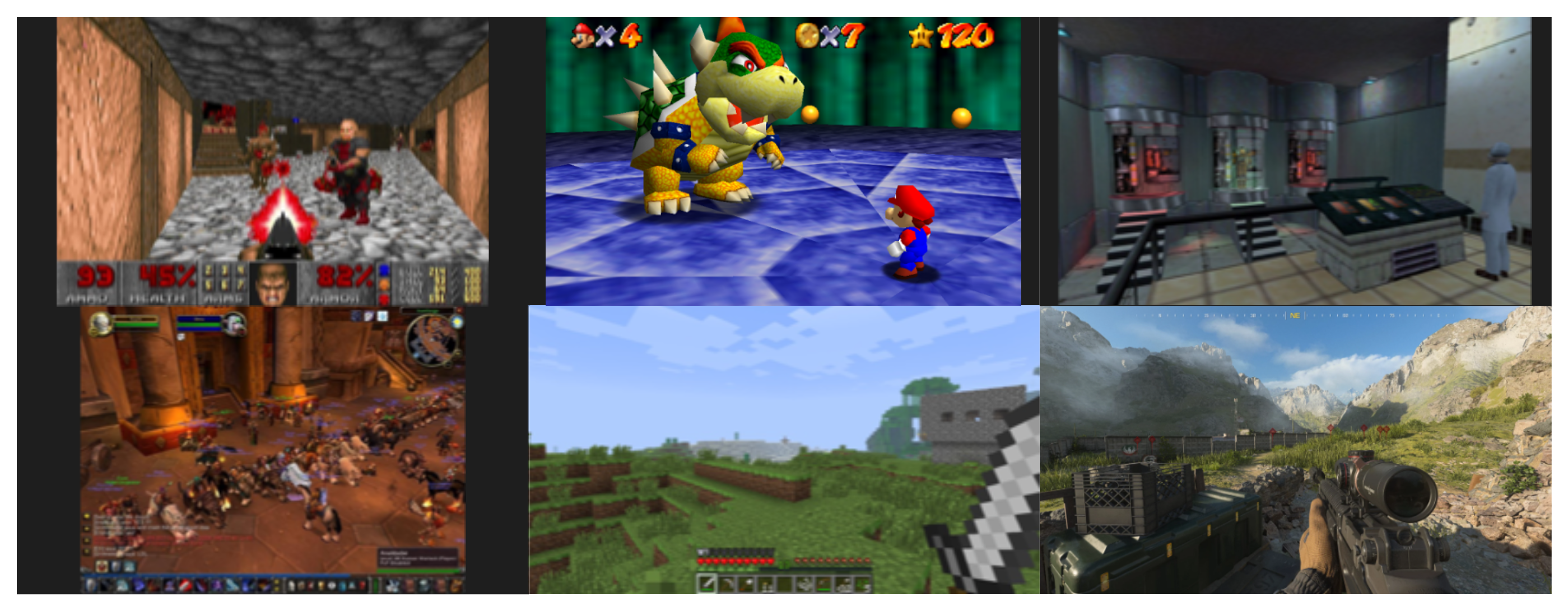
1990년대부터 3D 그래픽 게임에 대한 수요가 폭증하면서 그래픽 연산 능력에 대한 필요성도 급증했습니다.
1993년도에 출시한 DOOM은 3D 그래픽 게임에 혁신을 가져왔는데, 플레이 시 초당 약 1000만 번의 연산이 필요했습니다.
비디오게임에 필요한 연산은 초당 프레임 수 × 해상도 × 물리 시뮬레이션 × 텍스처 효과로 여러 방면 기술이 혼합되어 있고, 각 분야가 발전하면서 필요한 연산의 횟수는 기하급수적으로 늘어났습니다.
게임별로 필요한 연산량을 살펴보면:
- DOOM (1993): 초당 약 1000만 번
- Super Mario 64 (1996): 초당 1억(100M) 번
- Half-Life (1998): 초당 5억 번
- World of Warcraft (2004): 초당 22억 번
- Minecraft (2011): 초당 1000억(100G) 번
- Call of Duty: Modern Warfare III (2023): 초당 30~40조 번
30년 만에 연산량이 약 3~4백만 배 증가한 셈입니다.

여기서 말하는 그래픽 연산은 어떻게 진행될까요?
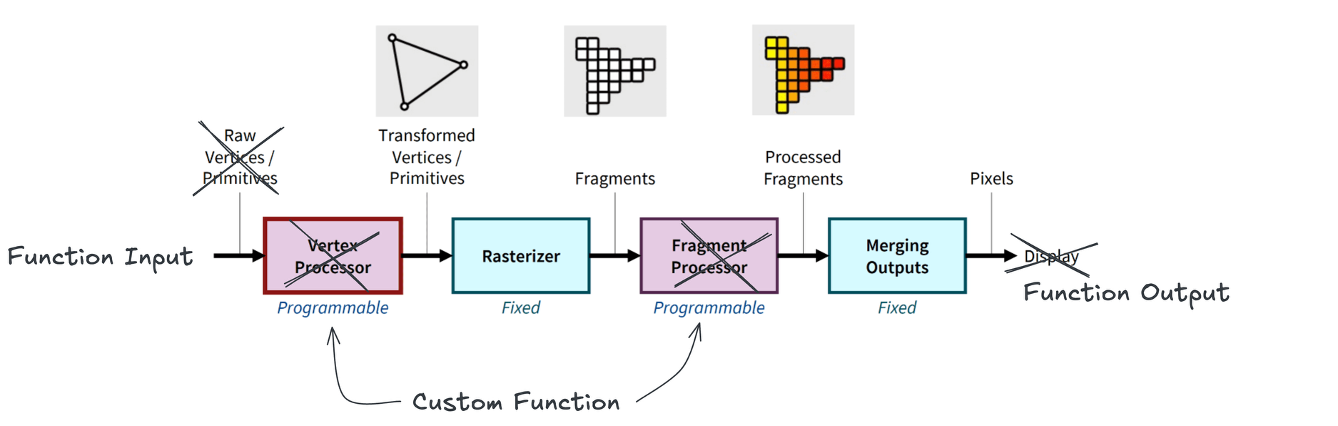
CPU가 먼저 가상 3D 공간의 기하학적 정보인 정점(vertex)들을 전송합니다.
GPU는 이 정점들을 화면상의 최종 픽셀 색상으로 변환하기 위해 셰이더(shader) 를 실행합니다.
셰이더는 렌더링 파이프라인의 각 단계를 프로그래밍 가능하게 제어하는 작은 프로그램으로,
정점이나 픽셀에 대한 변환, 조명, 색상 계산 등의 연산을 수행합니다.
먼저 vertex shader 가 정점들을 화면 좌표에 배치합니다.
이어서 primitive generation과 rasterization을 거쳐 픽셀로 매핑되고,
각 픽셀마다 fragment shader 가 최종 색상을 계산합니다.
이렇게 계산된 픽셀 색상들이 framebuffer에 저장되어 화면에 표시됩니다.
이러한 기본 그래픽 파이프라인 위에,
더 현실적인 표현을 위해 anti-aliasing, blending, transparency, shadow mapping 같은 추가 효과가 적용되었습니다.
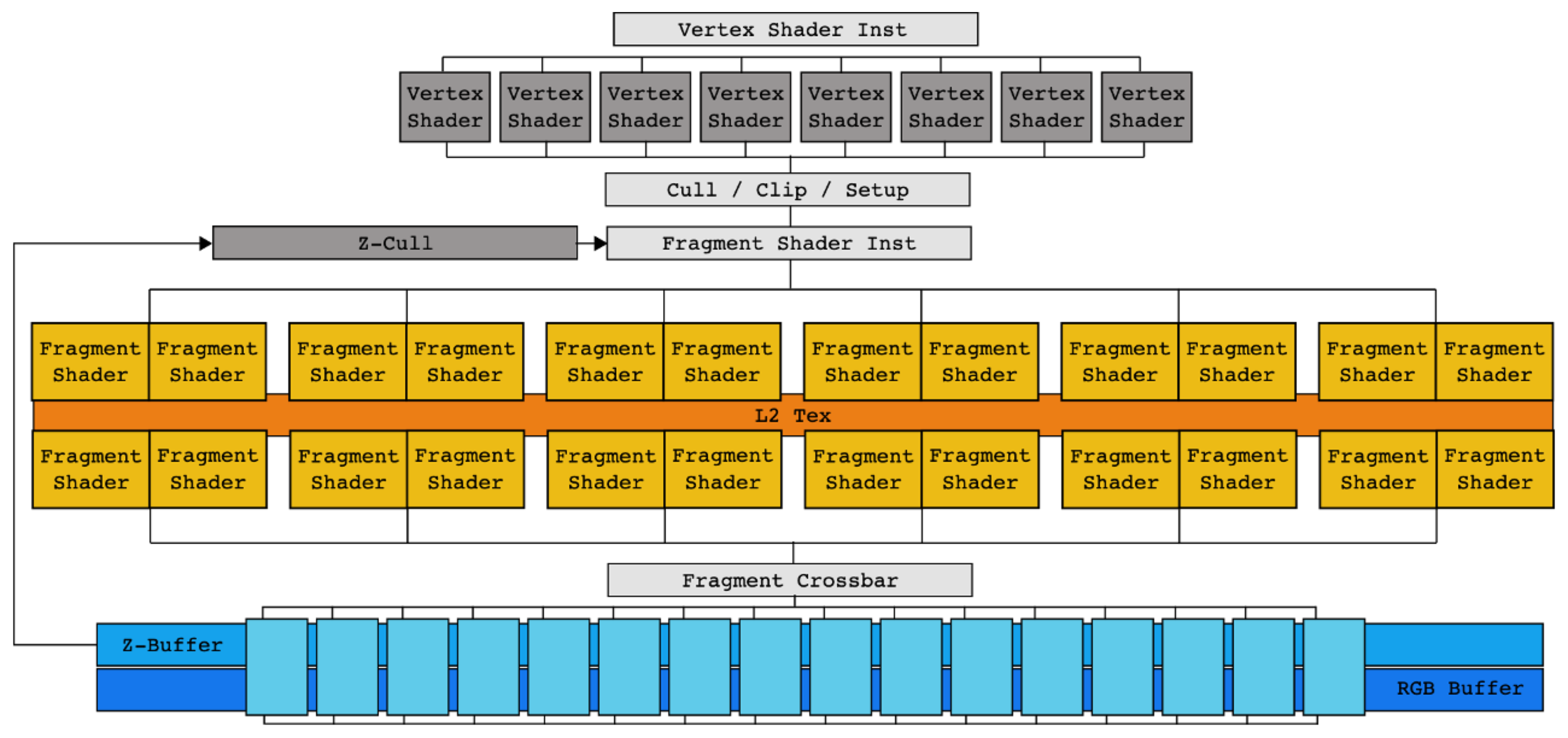
NVIDIA FX 그래픽 카드를 보면, 초기 GPU는 이 그래픽 파이프라인을 하드웨어로 그대로 옮겨놓았습니다.
vertex shading을 위한 vertex shader 회로가 따로 있고, fragment shading을 위한 fragment shader 회로가 따로 있었죠.
즉, 그래픽을 위해 고정된 가속장치(fixed-function accelerator) 였습니다.
이런 일방향 파이프라인 구조에는 큰 문제가 있었습니다.
중간 단계가 오래 걸리면 앞단계가 stall되어 버블이 생기고 하드웨어 활용률이 떨어집니다.
이 문제는 Programmable Shader 가 등장하면서 더욱 심해졌습니다.
커스텀 shader 함수는 연산 시간이 더 오래 걸리는 경우가 많아서 전체 하드웨어 활용률을 저해했고,
파이프라인이 길어지면서 병목이 어디서 발생하는지 파악하기 어려워졌습니다.
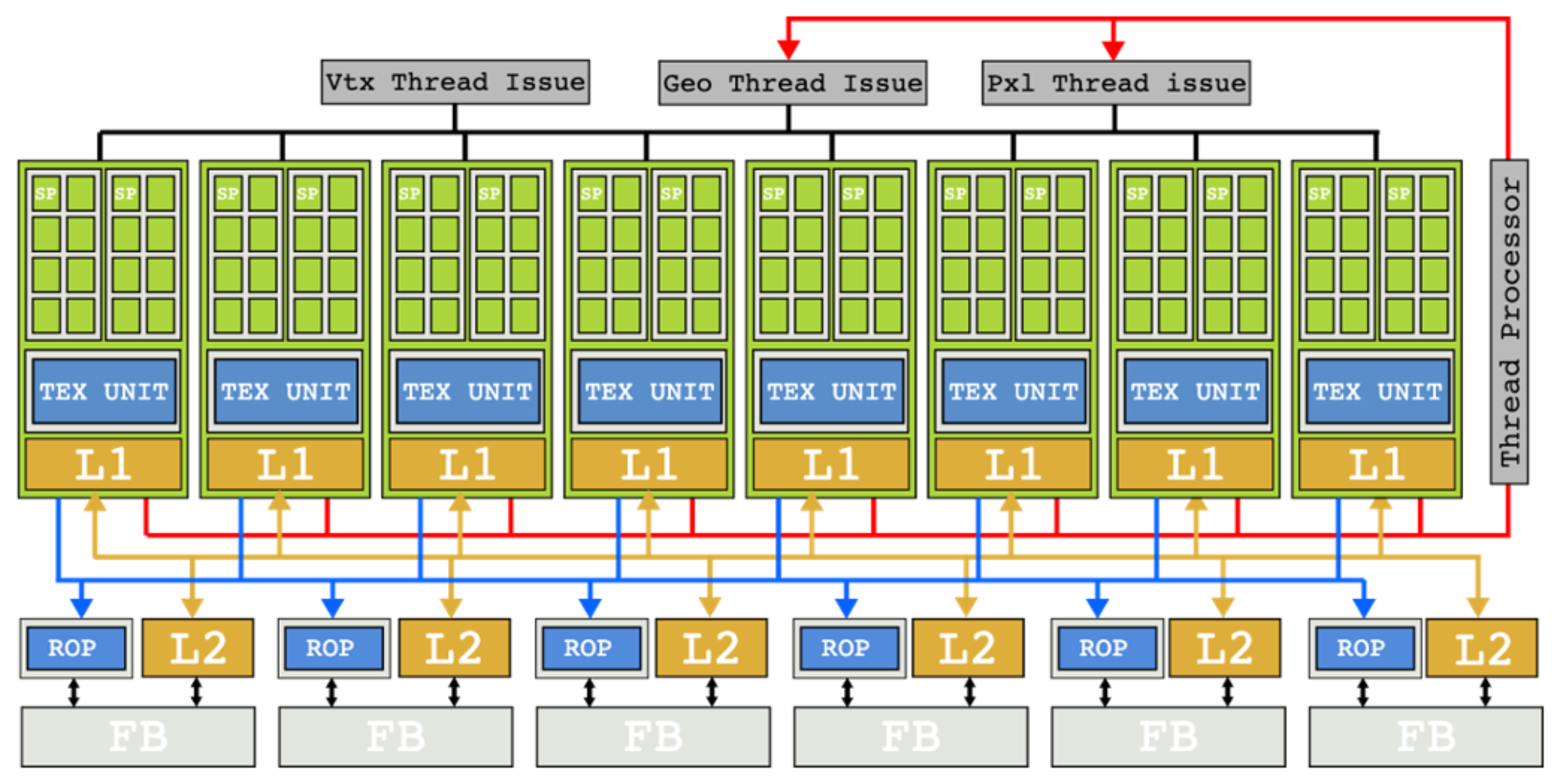
이런 상황에서 NVIDIA는 혁신적인 해결책을 내놓았습니다. 바로 Unified Shader를 도입한 G80 Tesla 아키텍처였죠.
별도의 vertex shader와 fragment shader 하드웨어 대신, 모든 shader 작업을 하나의 코어 풀에서 처리할 수 있게 했습니다.
기존에 몇 픽셀씩 벡터로 묶어서 처리하던 방식을 개별 픽셀 단위로 분해하고,
여러 픽셀에 대한 연산을 묶어서 스케줄링하는 방식으로 패러다임을 전환했습니다.
이런 아키텍처 전환 덕분에 특정 shader 연산이 오래 걸리더라도,
같은 코어에서 다른 shader 작업을 계속 진행할 수 있게 되었습니다.
일방향 파이프라인에서 발생하던 병목 현상이 혁신적으로 개선되었고,
이를 통해 GPU를 바라보는 새로운 관점이 열렸습니다: HPC(High Performance Computing)를 위한 GPGPU 입니다.
GPGPU와 CUDA의 등장
그래픽 처리 장치로서 발전을 거듭한 GPU가 연구자들의 눈에 띄게 됩니다.
2003년 두 연구팀이 각자 독립적으로 연구한 결과,
“GPU로 일반 선형대수학 문제를 풀면 기존 고성능 CPU보다 빠르다” 는 사실이 밝혀지면서
본격적으로 GPGPU 바람이 불기 시작했습니다.
GPU는 초당 연산량이 높다. 그럼 다른 데 쓰면 어떨까?
배경을 살펴보면, 그래픽 발전을 위해 DirectX 8(2000)이 Programmable Shader 개념을 도입하여
개발자가 전용 셰이더 하드웨어에서 실행되는 커스텀 셰이더 프로그램을 만들 수 있게 했습니다.
DirectX 9(2002)에서는 셰이더 언어 HLSL(High-Level Shader Language)을 추가하여
Programmable Shader를 본격적으로 실용화했습니다.
이때 GPU의 특성인 “다수 픽셀에 대한 동일 연산” 이
행렬 곱셈 같은 선형 대수학 문제의 “다중 데이터에 대한 동일 연산 실행” 과 매우 유사하다는 점에 착안하여,
입력 정점(input vertex)을 함수 입력으로, 프레임 버퍼(frame buffer)를 함수 출력으로 해석하는 방식으로
“범용 GPU(GPGPU)” 개념이 정립되었습니다.
다만 당시 하드웨어는 여전히 그래픽 파이프라인으로 만들어져 있었습니다.
그래서 당시 GPGPU는 일종의 “해킹” 과 같은 방식이었습니다.
선형 대수학 문제를 그래픽 문제로 재해석하고, 그래픽 파이프라인에 맞춰야 했으며,
기존 C 코드를 HLSL이나 GLSL(OpenGL Shader Language) 같은 셰이더 언어로 다시 작성해야 했죠.
강력했지만 매우 번거로웠습니다.
이 문제는 Tesla 아키텍처(2006)와 뒤이어 나온 CUDA(Compute Unified Device Architecture)(2007)를 통해 완벽히 해결됩니다.
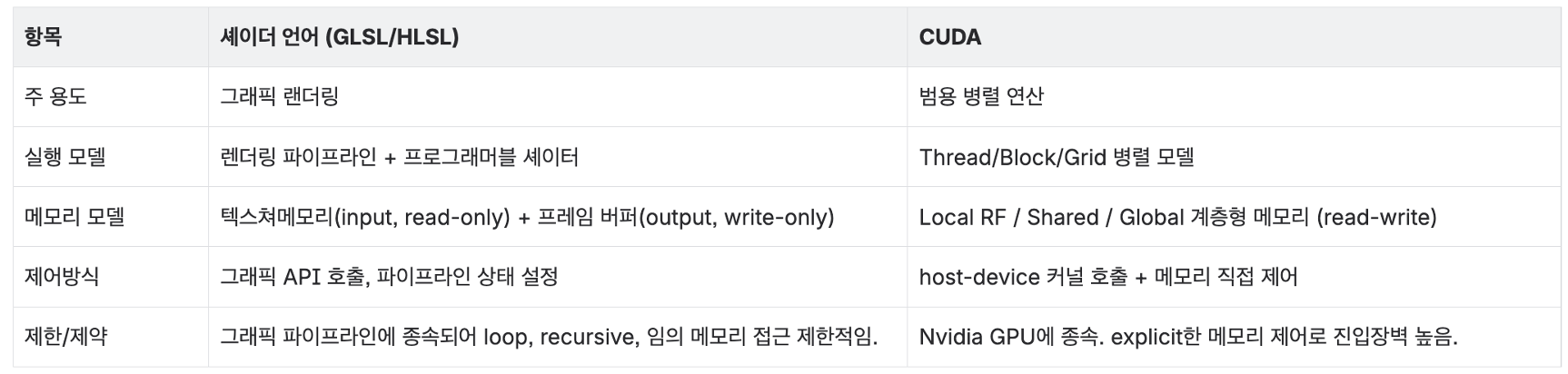
CUDA는 태생부터 그래픽이 아닌 병렬 연산에 초점을 맞추어 설계되었는데, Tesla의 Unified Shader 구조에 맞추어
- 하나의 데이터 포인트에 대한 작업을
thread - 한 하드웨어
SM에 배정되는 thread 묶음을block - 함수 실행 시 생성되는 전체 thread를
grid
로 정의하여 C언어의 개념체계를 그대로 사용하여 커널 함수를 구현할 수 있도록 하였습니다.
Tesla 아키텍처와 CUDA 프로그래밍 모델을 통해 GPU는 진정한 GPGPU의 세계로 들어갈 수 있었습니다.
이제 현대 GPU인 Hopper 아키텍처를 기준으로 과연 GPU는 어떤 식으로 만들어졌는지 살펴봅시다.
현대 GPU 구조
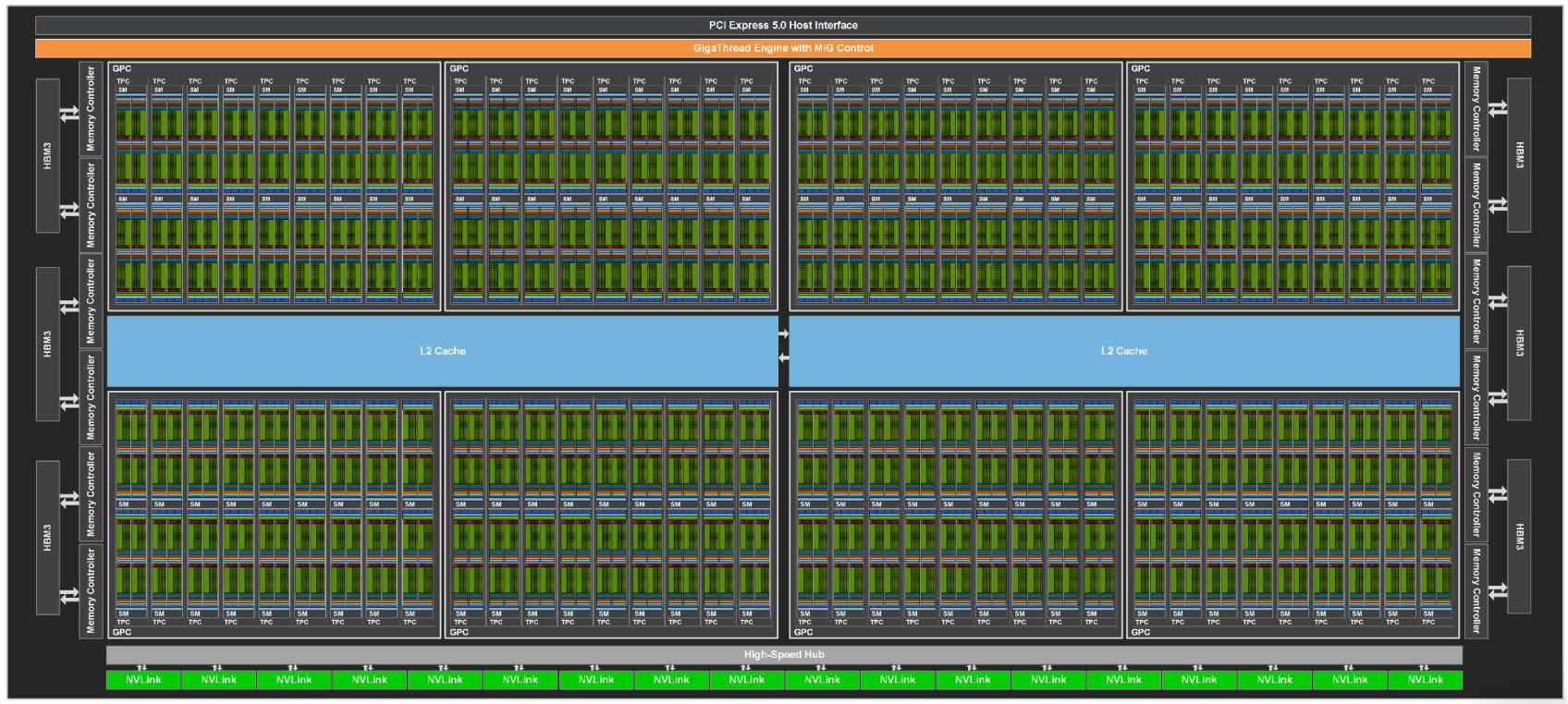
GPU (Device)
- 아래와 같은 구성 요소를 포함하는 전체 Device 입니다.
- 여러 GPC(Graphics Processing Cluster)
- 메모리(HBM(High Bandwidth Memory) 혹은 GDDR(Graphics Double Data Rate))
- 메모리 컨트롤러
- L2(Level 2) 캐시
- PCIe(Peripheral Component Interconnect Express)/NVLink(NVIDIA NVLink) 인터페이스
- GigaThread Engine: GPU 최상단에서 커널 실행 요청을 받아, 수천 개의 스레드 블록을 각 GPC와 SM으로 분배하는 전역 스케줄러 역할을 수행합니다.
GPC (Graphics Processing Cluster)
- 여러 개의 SM을 묶어 관리하는 상위 하드웨어 단위입니다.
- 래스터화 엔진(Raster Engine) 등 그래픽 처리를 위한 공통 자원을 공유합니다.
- Hopper 아키텍처에서는 스레드 블록 클러스터(Cluster)가 실행되는 경계가 됩니다.
- GPC 내부에는 SM 간의 초고속 연결망이 있어 Distributed Shared Memory(DSMEM) 접근이 가능합니다.(Hopper 이상)

SM (Streaming Multiprocessor)
GPU의 핵심 연산 블록(Building Block)이자, 스레드 블록(Block)이 실행되는 물리적 공간입니다.
CPU의 코어(Core)와 유사한 개념이지만 훨씬 더 많은 스레드를 동시에 처리합니다.
하나의 SM은 동시에 수십 개의 워프(Warp)를 활성화 상태로 유지하며(Active Warps), 메모리 대기 시간이 발생하면 즉시 다른 워프로 전환하여 파이프라인을 꽉 채웁니다(Latency Hiding).
주요 구성 요소:
- 4개의 SM Sub-partition: 연산 유닛들의 집합.
- Unified Shared Memory / L1(Level 1) Cache: 데이터 공유와 캐싱을 위한 고속 메모리. (Hopper 기준 256KB)
- TMA (Tensor Memory Accelerator): Hopper 아키텍처에서 도입된 연속된 메모리(주로 텐서) 복사를 전담하는 비동기 복사 엔진.
SM Sub-partition (Processing Block / SMSP)
- SM 내부를 4개로 쪼갠 구획입니다. (현대 NVIDIA GPU의 표준 구조)
- 각 파티션은 자체적인 Warp Scheduler (1개), Dispatch Unit, Register File (64KB), 그리고 할당된 CUDA Cores 및 Tensor Cores 세트를 가집니다.
- SM 하나를 통째로 관리하는 복잡도를 줄이고, 4개의 파티션이 독립적으로 워프를 스케줄링하여 병렬성을 극대화합니다.
그럼 이 하드웨어 위에서 작업은 어떻게 구조화될까요? CUDA 프로그래밍 모델을 조금 더 살펴봅시다.
CUDA 프로그래밍 모델의 구조
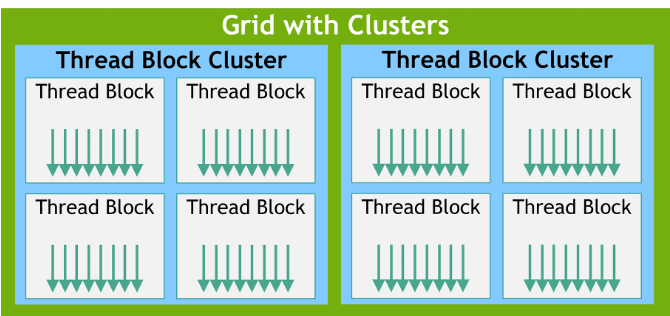
이러한 하드웨어 아키텍처 상에서 GPU는 병렬 작업을 총 5단계로 Thread를 묶어서 관리합니다.
스레드 (Thread)
병렬 처리의 최소 단위
- CUDA 연산의 가장 작은 논리적 단위입니다.
- 개발자가 작성한 커널(Kernel) 코드는 SPMD (Single Program Multiple Data) 방식에 따라 모든 스레드에 복제되어 실행됩니다.
- 각 스레드는 고유한 thread ID를 부여받으므로, 이를 이용해 서로 다른 메모리 주소에 접근하거나 각기 다른 제어 흐름을 가질 수 있습니다.
- 물리적으로는 CUDA Core 파이프라인을 점유하며 실행됩니다.
워프 (Warp)
하드웨어 실행의 최소 단위
- 워프는 32개의 연속된 스레드를 묶은 집합이며, 실질적인 명령어 실행(Instruction Issue) 단위입니다.
- 한 워프 내의 모든 스레드는 Instruction Cache 내의 명령줄을 가리키는 Program Counter(PC)를 공유합니다. (동일 명령, 동시 issue)
- 워프가 실행(issue)되면, PC가 가리키는 명령줄이 Dispatch Unit으로 전송되어 실행되고, 명령 실행이 종료되면 워프가 release되면서 PC가 증가합니다.
- 만약 워프 내 스레드들이 if-else문 등으로 서로 다른 실행 경로로 갈라진다면(Branch Divergence), 하드웨어는 모든 경로를 순차적으로 처리(Serialization)한 뒤 다시 합류시킵니다.
- 따라서 동일 워프 내 스레드들의 실행 경로를 일치시키는 것이 성능의 핵심입니다.
- SM 내부의 Warp Scheduler는 실행 가능한 상태의 워프를 빠르게 교체(Context Switching)하며 메모리 대기 시간(Latency)을 숨깁니다.
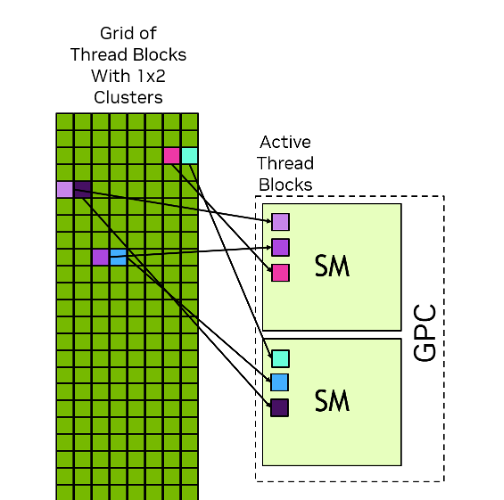
스레드 블록 (Thread Block / Cooperative Thread Association)
협력과 공유의 단위
- 서로 긴밀하게 협력할 수 있는 스레드들의 그룹(최대 1024 스레드) 입니다.
- 같은 블록 내의 스레드들은 Shared Memory를 공유하고,
__syncthreads()배리어(Barrier)를 통해 실행 단계를 동기화할 수 있습니다. - 하나의 블록은 물리적으로 반드시 하나의 SM (Streaming Multiprocessor)에 할당되어 생애주기를 마칩니다.
- SM의 자원(Register, Shared Memory 용량) 한계가 곧 블록 크기의 제약이 됩니다.
- 1차원~3차원(
Block(x,y,z))으로 구성 가능하여, 이미지나 볼륨 데이터 같은 다차원 문제를 직관적으로 맵핑할 수 있습니다.
스레드 블록 클러스터 (Thread Block Cluster)
블록 간 고속 통신을 위한 상위 계층 (Hopper 이상)
- Hopper 아키텍처에서 도입된 상위 계층으로, 여러 개의 스레드 블록을 묶은 단위입니다.
- 기존에는 블록 간 통신이 매우 제한적이었습니다 (Global Memory 경유).
- 클러스터는 물리적으로 GPC (Graphics Processing Cluster)에 매핑됩니다.
- 클러스터 내의 블록들은 DSMEM 기술을 통해, L2 캐시를 거치지 않고 서로의 Shared Memory에 직접 접근(P2P, Peer-to-Peer)할 수 있습니다.
그리드 (Grid)
커널 실행의 전체 단위
- 커널이 호출(Launch)될 때 생성되는 모든 스레드 블록의 집합입니다.
- 커널 호출 한 번이 곧 하나의 그리드입니다.
- 그리드 내의 블록들은 서로 독립적입니다.
- 실행 순서가 보장되지 않습니다.
- 서로 다른 SM에서 병렬로 실행될 수도, 하나의 SM에서 순차적으로 실행될 수도 있습니다.
- 이 독립성 덕분에 동일한 코드가 SM이 10개인 보급형 GPU에서도, SM이 144개인 H100에서도 수정 없이 동작하는 확장성(Scalability) 이 보장됩니다.
GPU는 어떻게 동작하는가?
그렇다면 코드를 넣었을 때 GPU는 도대체 어떻게 동작하는 것일까요? Scheduling 예시를 통해 차근차근 알아보겠습니다.
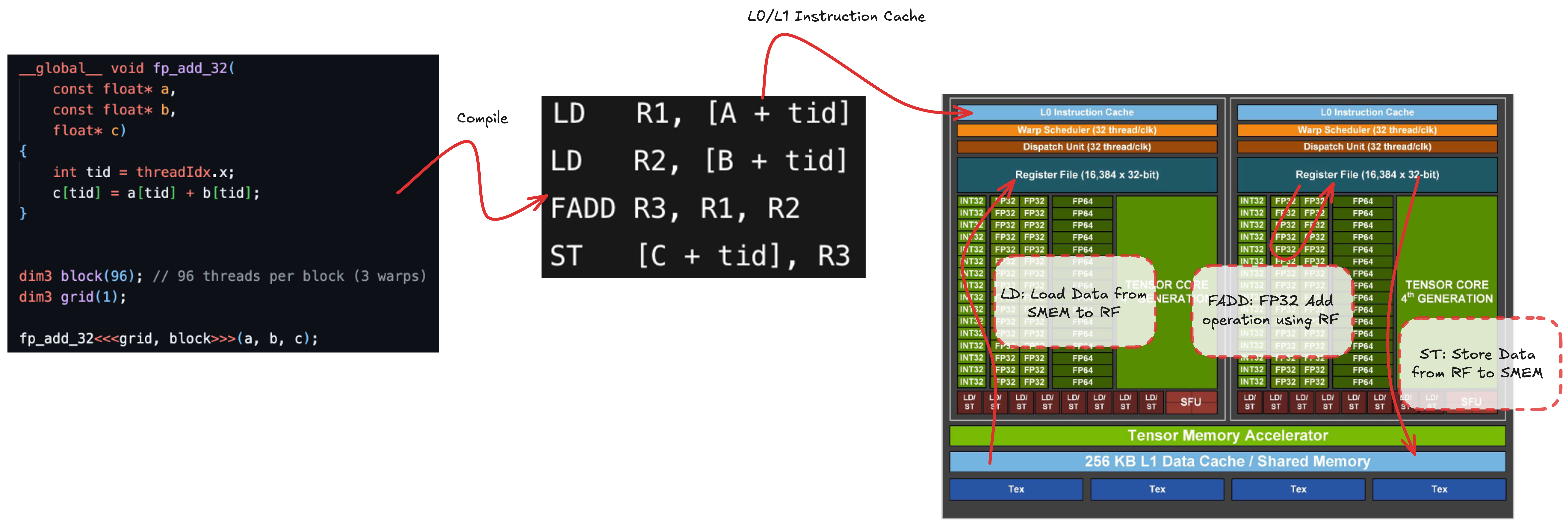
간단한 fp32(32-bit floating-point) 덧셈 커널을 예시로 살펴봅시다.
그리드를 블록 1개, 각 블록은 96개의 스레드로 구성하여 커널을 실행합니다.
실제로는 커널이 머신 코드(SASS, Shader Assembly)로 컴파일되지만, 편의상 4단계의 논리적 과정으로 생각해볼 수 있습니다:
- 오퍼랜드
A를 메모리(SMEM/Shared Memory, L1, L2, global)에서 레지스터 파일로 불러오기 (LD, Load) - 오퍼랜드
B를 레지스터로 불러오기 (LD) - 레지스터에 있는 오퍼랜드로
FADD(Floating-Point Add)R3, R1, R2연산을 수행하여 결과를 레지스터에 저장 - 계산 결과를 다시 메모리(SMEM/L1/L2/global)에 저장하기 (
ST, Store)
LD와 ST 연산은 연산 파이프라인 관점에서 비동기적으로 동작 합니다.LD/ST 유닛은 메모리 주소를 계산하여 메모리 서브시스템에 요청을 보내고,
메모리 서브시스템이 나중에 이를 완료합니다.
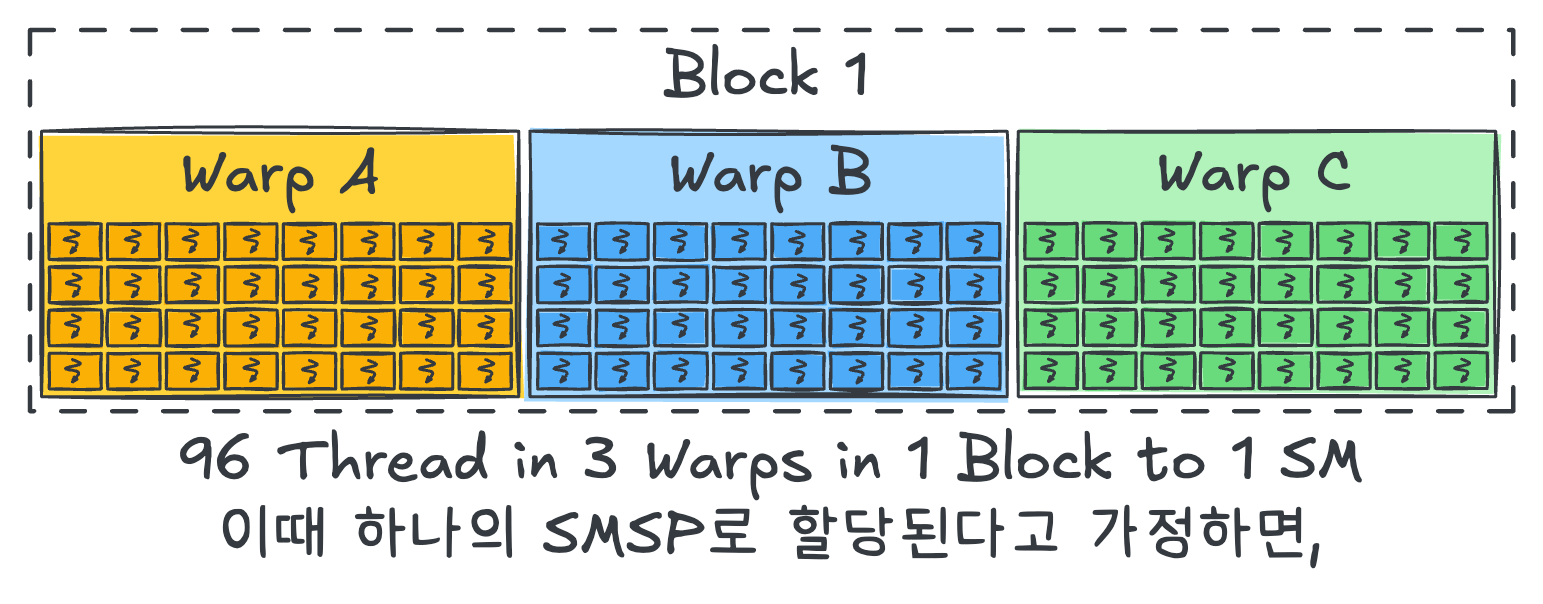
만들어진 총 96개의 스레드는 3개의 warp로 나뉘고, 1개의 block에 배정되어 있으므로 1개의 SM에 할당됩니다.
이때 scheduling 예시 편의를 위해 모두 같은 SMSP에 할당된다고 가정합시다.
Hopper에서의 Warp 스케줄링 하드웨어
본격적인 스케줄링 예시로 들어가기 전에, Hopper 기준으로 Warp Scheduler와 Dispatch Unit이 어떤 역할을 하는지를 먼저 짚고 가겠습니다.
Warp Scheduler는 scoreboard를 이용해 각 warp의 의존성 상태를 추적하면서,
지금 당장 실행 가능한(eligible) warp를 고르는 역할을 합니다.
이때 Dispatch Unit의 처리 능력, 예를 들어 Hopper에서 대략 32 threads/clk 수준의 issue 폭을 고려해,
해당 사이클에 자원이 부족한 warp는 나중에 issue하도록 뒤로 미룹니다.
Dispatch Unit은 이렇게 선택된 warp의 명령을 실제 실행 파이프라인에 태우는 모듈입니다.
Warp Scheduler는 warp 단위로 issue하지만, Dispatch Unit은 32개의 스레드를 여러 사이클에 나누어 보내거나,
LD/ST·INT(Integer)·FP(Floating-Point) 같은 서로 다른 타입의 파이프라인에 적절히 섞어서(co-issue) 보내
GPU의 자원을 최대한 채우려고 합니다.
이제 이 하드웨어 위에서, 첫 번째 warp인 Warp A가 어떻게 스케줄되는지를 단계별로 살펴보겠습니다.
Single Warp Scheduling

Warp A는 Warp Scheduler(WS)에 의해 issue됩니다.
PC(Program Counter) 값에 따라 첫 번째 명령어인 LD R1, [A+tid]가 Dispatch Unit으로 전송됩니다.
Dispatch Unit은 현재 SMSP에서 사용 가능한 자원을 스캔하여 8개의 LD/ST 유닛이 사용 가능함을 확인합니다.
이후 issue된 32개의 스레드를 8개씩 4 사이클에 걸쳐 LD/ST 유닛에 할당합니다.
각 유닛은 할당받은 명령어를 기반으로 메모리 주소를 계산하여 메모리 서브시스템에 로드 요청을 보냅니다.
이러한 로드 명령은 비동기적으로 처리됩니다.
5번째 사이클에 LD/ST 동작이 끝나면, WS는 Warp A를 release하면서 PC 값을 증가시킵니다.
다음 사이클에 WS는 release된 Warp A를 다시 issue하여 같은 방식으로 두 번째 LD 명령을 수행합니다.
두 번의 LD가 모두 issue된 후, Warp A는 바로 FADD R3, R1, R2를 실행할 수 없습니다.R1과 R2가 아직 비동기 로드에 의해 채워지는 중이기 때문입니다.
워프는 두 오퍼랜드가 모두 준비될 때까지 기다려야 합니다.
이 대기 시간 동안 FP 유닛은 유휴 상태가 되며, stall이 발생합니다.
메모리 로드 시간은 대략적으로 다음과 같습니다:
- L1(Level 1) cache: ~20 사이클
- L2(Level 2) cache: ~100 사이클
- HBM(High Bandwidth Memory): 수백 사이클 (300~800)
메모리 로드가 완료되고 의존성(Dependency)이 해결되면, Warp A는 다시 eligible 상태가 되어 WS에 의해 issue됩니다.FADD 명령은 FP32(32-bit Floating-Point) 파이프라인으로 전송됩니다.
Hopper에서는 SMSP당 32개의 FP32 유닛이 존재하므로, 워프 내 32개 스레드를 한 번에 처리할 수 있습니다.
FADD 연산이 완료되면 워프가 다시 release되고, 마지막 ST 명령은 LD와 유사한 방식으로 동작합니다.
Double Warp Scheduling
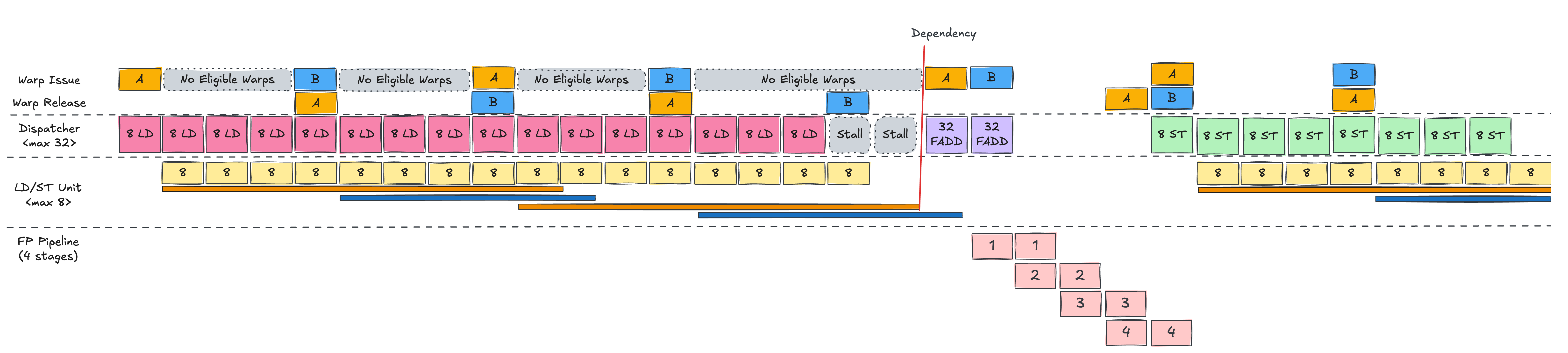
이제 Warp B를 추가해봅시다.
Single warp 시나리오에서는 첫 번째 LD가 끝났을 때, Warp A의 PC(Program Counter)가 아직 완전히 이동하지 않은 상태라서
WS가 즉시 Warp A를 다시 issue할 수 없어 한 사이클의 유휴 상태가 발생했습니다.
하지만 Warp B가 있으면 이 유휴 슬롯을 활용할 수 있습니다.
Warp A가 모든 LD/ST 유닛을 사용 중일 때는 Warp B를 실행할 수 없습니다.
하지만 A의 LD가 모두 dispatch되면, WS는 Warp B를 issue하여 같은 방식으로 LD를 수행합니다.
이렇게 A와 B를 번갈아가며 총 네 번의 LD 명령을 issue합니다 (워프당 두 번씩).
그 후 두 워프 모두 FADD를 수행하기 전에 로드가 완료되기를 기다립니다.
Single warp 케이스와 비교했을 때 핵심 차이점은 Warp A의 메모리 레이턴시가 Warp B의 로드와 오버랩된다는 것입니다.
이로 인해 보이는 stall 시간이 줄어듭니다.
Warp A의 두 번째 LD 이후 Warp B의 LD가 바로 이어지기 때문에, Warp A의 비동기 메모리 로드 시간이 오버랩되어 stall 시간이 감소합니다.
Warp A의 메모리 로드가 완료되면 즉시 FADD가 issue 및 dispatch됩니다.
예시에서는 Warp B의 의존성도 곧바로 해결되어 다음 사이클에 FADD가 연달아 수행됩니다.
연산기가 파이프라인 구조로 되어 있기 때문에, 각 스테이지별 유휴 상태가 독립적으로 관리되며
레이턴시를 효과적으로 숨길 수 있습니다.
Multiple Warp Scheduling
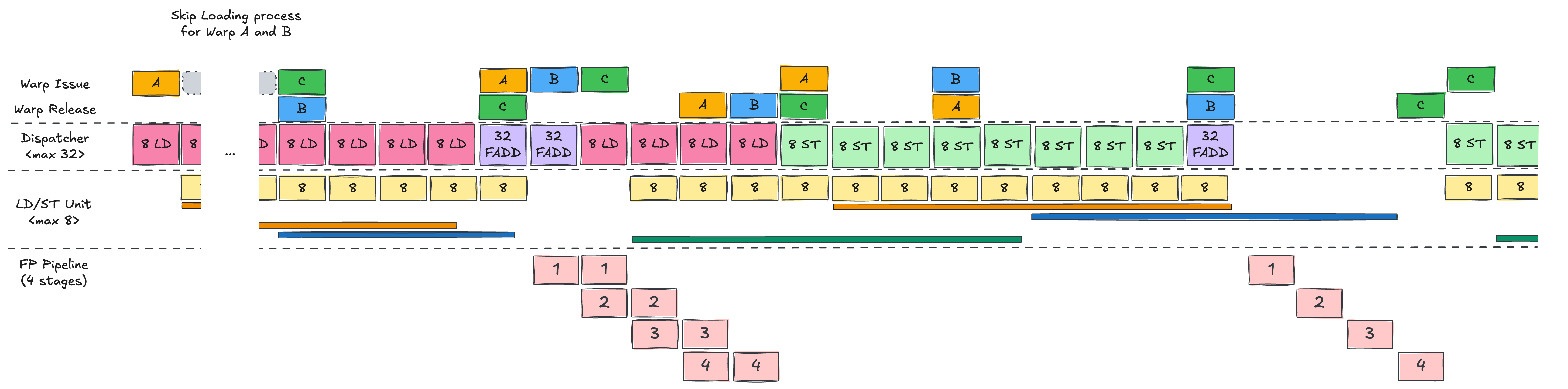
마지막으로 Warp C를 추가합니다.
세 개의 워프가 동시에 실행되면, GPU는 메모리 연산과 계산을 더욱 효과적으로 오버랩할 수 있습니다.
이를 통해 발생할 수 있는 대부분의 stall이 사라집니다.
결론적으로, Hopper에서의 CUDA 프로그래밍은 SMSP 파이프라인에 충분한 독립적인 작업을 채우는 것이 핵심입니다.
여러 워프에서 로드, 산술 연산, 스토어를 issue하여 비동기 메모리 통신 시간을 효과적으로 오버랩하는 방식으로 동작합니다.
정리하자면…
이 글에서는
① 그래픽 카드에서 출발한 NVIDIA의 역사,
② Tesla·CUDA를 거치며 GPGPU 플랫폼으로 확장된 과정,
③ Hopper 세대 기준의 하드웨어 구조와 스케줄링 예시를 살펴보며,
궁극적으로
“GPU는 느린 메모리를, 많은 워프 간의 빠른 컨텍스트 전환과 여러 연산의 동시 실행으로 가리는 장치”
라는 결론에 도달했습니다.
결국 메모리 계층, 스케줄러 정책, 실행 파이프라인까지 GPU의 모든 설계 요소가 이 목표를 중심으로 짜여 있다는 점이 핵심입니다.
다음 글에서는 최근 무섭게 AI 하드웨어 시장을 뺏어가고 있는 Google의 TPU에 대해서 살펴보겠습니다. TPU의 역사와 최신 TPU 아키텍처인 Ironwood에 대한 분석을 진행할 예정이니 많은 관심 부탁드립니다.
그럼 지피지기면 백전불태 2편: TPU의 등장과 부상 에서 다시 뵙겠습니다.
추신: HyperAccel은 채용 중입니다!
지피지기면 백전불태라지만 백전백승을 위해서는 훌륭한 인재가 많이 필요합니다!
저희가 다루는 기술들을 보시고, 관심이 있으시다면 HyperAccel Career로 지원해 주세요!
HyperAccel에는 정말 훌륭하고 똑똑한 엔지니어분들이 많습니다. 여러분의 지원을 기다립니다.