
이 글은 AI 시대의 필수 소비재, 메모리 이해하기 시리즈의 2편입니다.
1편: HBF 이해하기 에서는 HBF가 무엇이고 메모리 계층의 어디에 위치하는지를 다뤘습니다.
이번 편에서는 그 한계를 안고도 HBF가 효과적으로 쓰일 자리는 어디인가 를 묻고, SK하이닉스가 제안한 H³ 아키텍처와 그 너머의 잠재 워크로드까지 살펴봅니다.
들어가며
안녕하세요? HyperAccel 하드웨어 검증 엔지니어 임재원입니다.
지난 1편에서는 메모리의 종류와 메모리 계층 구조의 새로운 자리를 차지하려는 HBF(High Bandwidth Flash) 에 대해 알아보았습니다. HBF의 특징을 한 줄로 표현해보면 다음과 같습니다.
대역폭과 용량은 크지만, 너무 느린 메모리.
더 정확히 말하면, HBF는 HBM(High Bandwidth Memory) 에 견줄 만한 대역폭에 8-16배 더 큰 용량을 얹은 메모리입니다. 단, 지연시간(latency)은 기존 SSD와 비슷한 수준으로 HBM 대비 약 100배 깁니다. bandwidth와 capacity는 HBM에 비견되거나 오히려 우월한데 latency는 SSD급, 결과적으로 어디에 끼워 넣어야 의미가 있을지 자체가 애매한 스펙입니다. 그래서 HBF가 잘 맞는 워크로드를 따로 발굴하는 과정이 필요합니다.
1편이 “HBF란 무엇인가"에 답했다면, 2편은 그 다음 질문으로 넘어갑니다.
“HBF, 실질적으로 어떻게 쓸 수 있을까?”
HBF는 아직 상용화 전 단계입니다. 시장과 가속기 회사 입장에서는 spec 너머의 그림. 즉, 어떤 워크로드에서 쓰일지, 그 근거가 무엇인지가 분명해져야 비로소 채택 결정이 움직입니다. 그래서 이번 편의 출발점은 이 질문입니다.
HBF의 잠재 workload를 조사하면서 알게 된 점은, 적절한 워크로드에 약간의 하드웨어 기법을 더하면 HBF의 약점은 숨길 수 있다는 것입니다. 이번 편에서는 SK하이닉스가 IEEE Computer Architecture Letters 2026에 발표한 H³ 아키텍처를 중심으로, HBF가 효과적으로 쓰일 자리들을 찾아봅니다.
HBF의 한계, 다시 짚기
1편에서 다룬 HBF의 약점을 다시 정리하면 세 가지입니다.
첫째는 지연시간입니다. HBF는 NAND flash 셀에 패키징을 입혀 만든 메모리입니다. 셀 자체의 읽기 메커니즘이 DRAM보다 본질적으로 느려서, HBM이 수십-수백ns 수준에서 데이터를 읽는 동안 HBF는 약 10-20μs를 필요로 합니다. 약 100배 차이입니다. 이 격차는 패키징을 아무리 잘 해도 셀 차원의 한계라 사라지지 않습니다.
둘째는 write endurance입니다. NAND flash는 erase/write 사이클에 물리적 수명 제한이 있습니다. 같은 위치에 반복해서 쓰는 워크로드라면 셀이 빠르게 마모됩니다. 학습이나 빈번하게 갱신되는 데이터에는 어울리지 않습니다.
셋째는 read granularity입니다. HBF는 NAND 기반이라 한 번의 읽기 요청이 page 단위(약 4KB)로 처리됩니다. HBM4가 32B 단위로 fine-grained access가 가능한 것과 대조적이죠. 워크로드가 작은 chunk를 random하게 골라 읽어야 한다면, 매 요청마다 4KB 중 실제로 쓰이는 데이터는 일부에 불과해 effective bandwidth가 급감합니다. 명목 bandwidth가 HBM에 견줄 만해도 실효 bandwidth는 훨씬 낮아질 수 있다는 뜻입니다.
한계를 비껴가는 워크로드 조건
위 세 약점을 동시에 무력화하려면 워크로드가 아래 조건을 만족해야 합니다.
- 한 번 적재하고 여러 번 반복 읽기: write endurance 무력화
- 데이터 접근이 예측 가능: 접근할 주소를 미리 알 수 있다면 prefetch로 latency를 숨김
- 큰 단위로 묶어 읽기: 한 번 page를 가져올 때 그 안의 데이터를 충분히 활용해 effective bandwidth를 유지
이 조건이 LLM 워크로드 어디에 들어맞을지 보려면, 가장 먼저 학습(training) 과 추론(inference) 을 비교해 볼 만합니다. 둘은 메모리 입장에서 정반대 성격을 가집니다.
학습 은 매 step마다 weight를 갱신합니다. backward pass에서 gradient를 계산하고 optimizer state까지 함께 update하기 때문에 메모리 위에서 “쓰기"가 끊임없이 일어납니다. 이는 write endurance에 한계가 있는 HBF에는 가장 부적합한 워크로드입니다.
추론 은 이야기가 다릅니다. 일단 학습이 끝난 뒤의 weight는 추론 내내 웬만해선 갱신되지 않습니다. Llama 3.1 405B를 FP8로 돌린다고 가정하면 weight 한 벌이 약 405GB이고, 이걸 매 batch마다 처음부터 끝까지 읽기만 합니다. HBF가 원하는 read-only 패턴이 여기에 있습니다.
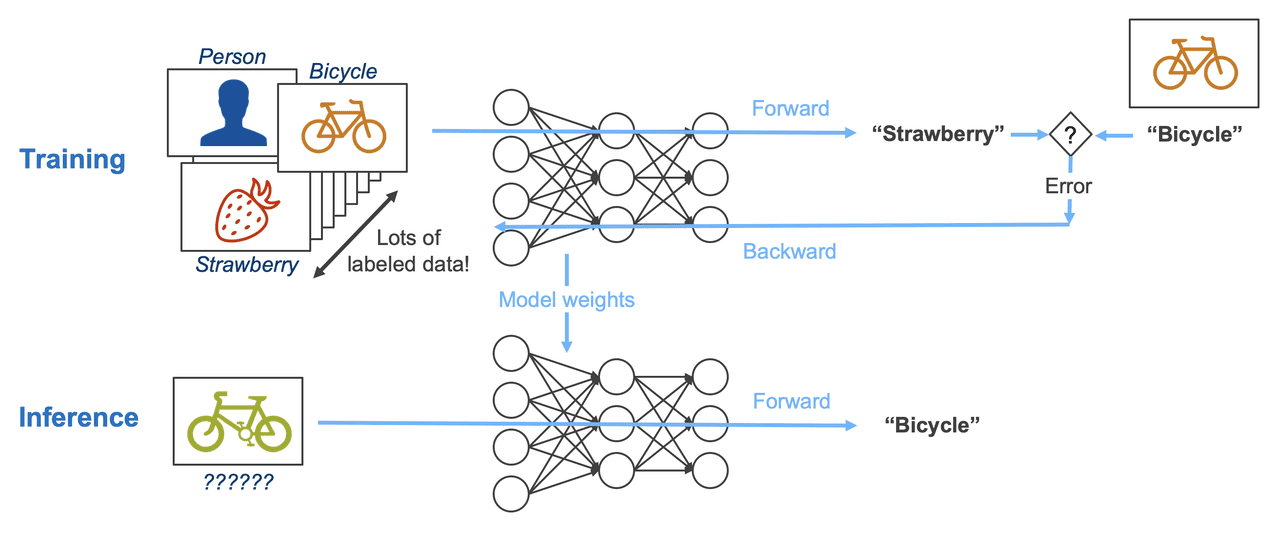
그런데 추론에서 weight만큼 거대해질 수 있는 데이터가 하나 더 있습니다. KV cache 입니다. 짧은 context에서는 문제가 되지 않지만, 최근 나오는 모델들은 1-10M에 달하는 context window를 지원합니다. 이를 고려한다면 KV cache는 수백 GB - 수 TB까지 부풀어 오릅니다. 이걸 HBF에 올릴 수 있다면 활용 폭이 단번에 넓어집니다. 하지만, 일반적인 KV cache는 write가 빈번하게 일어나기 때문에, 일반적인 상황에서 HBF를 KV cache를 저장하는 주요 공간으로 설정하기에는 무리가 있습니다.
CAG, 한 번 연산한 KV cache를 여러 번 재사용하기
앞서 설명한 KV cache를 HBF에 올리기가 까다로운 이유를 자세히 설명하면 두 가지입니다.
- 매 토큰마다 새로 쓰입니다. decode 단계에서 출력 토큰이 하나씩 생성될 때마다 모든 layer의 KV에 새 entry가 누적됩니다. write 빈도가 무척 높습니다.
- 요청마다 값이 다릅니다. 사용자 query가 매번 다르니, 같은 모델이라도 KV cache 내용은 매번 새로 계산됩니다. 한 요청을 위한 cache가 다른 요청에서 재사용되지 않습니다.
두 특성은 정확히 HBF가 약한 지점입니다. 잦은 write는 endurance를 깎고, 재사용되지 않는 데이터는 HBF의 거대 capacity를 살릴 명분이 없습니다. 즉, KV cache를 단일 write × 다중 read 형태로 바꿀 수 있다면, 비로소 HBF가 의미를 가집니다.
그렇다면 실제 LLM 추론에서 사용되는 기법들은 KV cache를 어떻게 다루고 있을까요?
LLM 응답 품질을 올리는 가장 흔한 기법은 Retrieval-Augmented Generation(RAG) 입니다. 외부 지식 베이스(보통 vector DB)에서 질의에 관련된 문서를 검색해 prompt에 끼워 넣고, 그 위에서 답변을 생성하는 방식이죠. 매 요청마다 retrieve가 일어나고, 가져온 context로 새 KV cache를 만들어 냅니다. 여기까지는 KV cache가 여전히 per-request 단발성이라 위 두 특성을 그대로 안고 있습니다.
그런데 만약 모델이 참조해야 하는 지식이 요청마다 크게 바뀌지 않는 거대한 공유 자료 라면 어떨까요? 같은 매뉴얼, 같은 코드베이스, 같은 사내 문서를 매번 retrieve & 재계산하는 것은 명백히 낭비입니다.
2024년 말 발표된 한 논문은 이 낭비를 극복할 수 있는 새로운 패턴을 제안했습니다. 바로 Cache-Augmented Generation(CAG) 입니다.
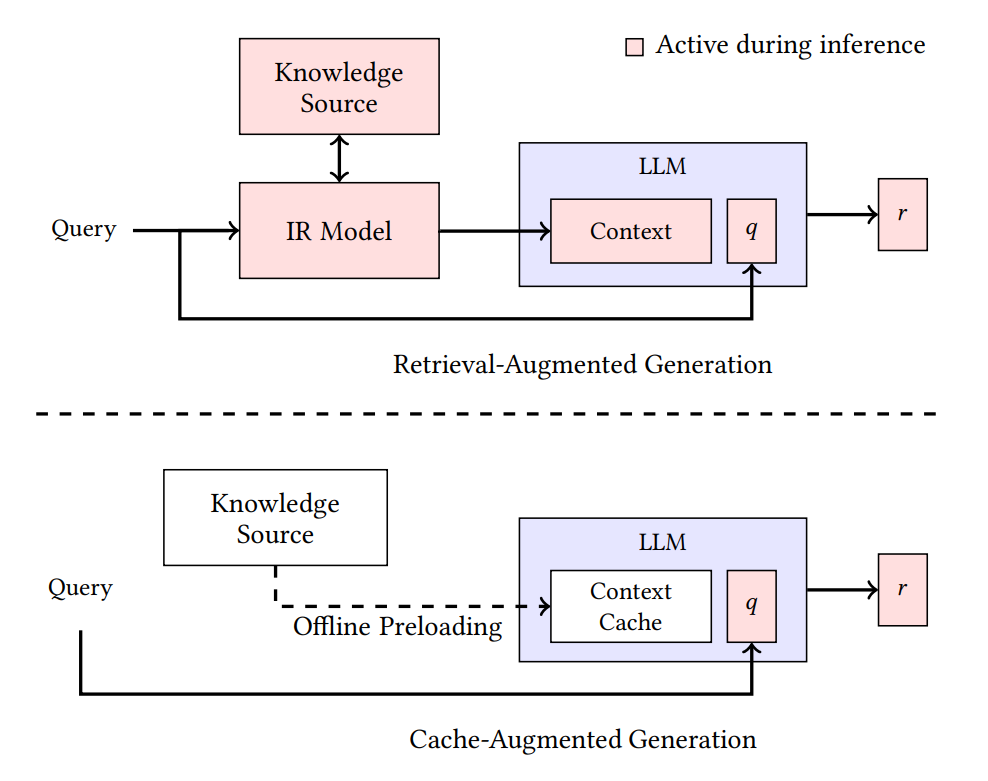
CAG의 작동 방식은 단순합니다.
- 공유될 만한 거대 지식 자료를 사전에 한 번 모델에 통과시켜 KV cache를 만들어 둡니다.
- 사용자 질의가 들어오면, 이 사전 KV cache를 prefix처럼 그대로 활용해 답변을 생성합니다. 같은 자료를 다시 계산하지 않습니다.
- 여러 요청이 들어오면 같은 KV cache를 공유 하면서 각자의 답변을 만들어 냅니다.
RAG와 CAG를 한 줄로 비교하면 이렇습니다.
- RAG: retrieve + 매 요청마다 KV cache 재계산
- CAG: 사전에 한 번 KV cache 연산, 여러 번 반복 read
메모리 입장에서 보는 차이는 더 극명합니다. RAG의 KV cache는 요청별로 짧고 일회용이지만, CAG의 KV cache는 read-only이며, 여러 요청에서 반복 접근됩니다. CAG로 만들어지는 데이터가 1M context면 수백 GB, 10M context면 수 TB 수준입니다.
이러한 CAG의 특성을 앞 절에서 정의한 “HBF의 약점이 숨겨지는 조건"과 비교해보겠습니다.
- read-only → write endurance 문제 해소
- 한 번 적재 후 반복 읽기 → 매번 다시 계산하지 않고 한 번 만든 cache를 여러 요청이 나눠 씀
- layer 별로 사용되는 KV cache는 예측 가능 → prefetch로 latency 숨김 가능
조건에 적합한 워크로드임을 알 수 있습니다. SK하이닉스가 H³를 정당화하는 핵심 use case로 CAG를 꼽은 이유가 여기 있습니다. 다음으로는 하이닉스가 제시한 하드웨어 아키텍처를 살펴보겠습니다.
SK하이닉스의 H³: HBM과 HBF의 역할 분담
SK하이닉스 연구진이 발표한 H³ 의 핵심 아이디어는 한 줄로 요약됩니다.
HBF로 HBM을 대체하지 말고, 거대 read-only 데이터 전용 슬롯으로 옆에 추가하자.
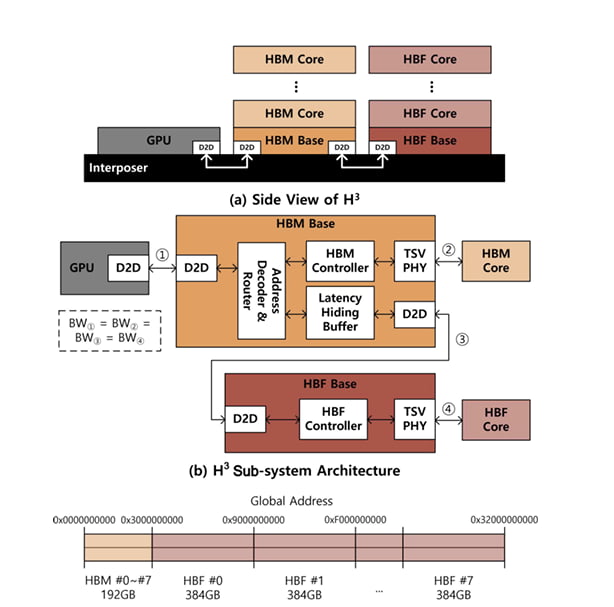
물리 구조: HBM 뒤에 HBF를 연결
일반적인 GPU에서는 HBM 스택들이 인터포저 위에서 GPU와 나란히 배치되어, GPU shoreline의 한정된 공간을 모두 사용합니다. H³는 이 구조를 건드리지 않습니다. HBM은 그대로 GPU shoreline에 직접 연결합니다.
HBF는 그 뒷 단에서 연결됩니다. 각 HBM 스택의 base die에 Die-to-Die(D2D) 인터페이스를 추가해, HBM 뒤로 HBF 스택을 한 단계 더 잇습니다. GPU 입장에서는 HBM과 HBF 모두 통합 주소 공간(unified address space) 안의 main memory처럼 보입니다. HBM base die 안의 address decoder & router가 들어온 요청을 HBM으로 보낼지, HBF로 보낼지 판단합니다.
이 구조의 장점은 GPU shoreline 면적을 더 쓰지 않으면서 HBM 용량의 수십 배를 추가로 끌어다 쓸 수 있다는 점입니다. SK하이닉스의 가정에 따르면 GPU당 HBM3e가 192GB / 8TB/s라면, 같은 GPU 뒤로 붙는 HBF는 GPU당 약 3TB / 8TB/s를 더해 줍니다. 약 16배의 메모리 용량이 추가됩니다.
데이터 배치 규칙: 누가 어디에 위치하는가
H³의 운영 철학은 데이터의 성격에 따라 두 메모리에 나눠 배치하는 것입니다.
- HBF: 모델 weight, CAG의 사전 계산 공유 KV cache
- HBM: 생성 중인 KV cache, activation, 그 밖에 자주 갱신되는 데이터
앞서 이야기한 바와 같이 이러한 형식으로 데이터를 용도별로 나눠서 저장하게 된다면 HBF의 약점을 상쇄할 수 있게 됩니다.
Latency Hiding Buffer
그래도 한 가지 문제는 남습니다. NAND 셀의 약 수십 μs latency입니다. HBM의 ns 단위 응답을 가정하고 동작하던 GPU compute pipeline이 갑자기 μs 단위 메모리를 만나면 거의 멈추게 됩니다.
SK하이닉스의 해법은 Latency Hiding Buffer(LHB) 입니다. HBM base die 안에 prefetch 전용 SRAM 버퍼를 통합하는 방식입니다.
작동 원리는 LLM 추론의 한 가지 특성에 기댑니다. 데이터 접근 패턴이 결정론적이다 는 점입니다. 다음 layer에서 어떤 weight와 KV cache가 필요한지 미리 알 수 있다는 뜻이죠. 딥러닝 framework가 이 정보를 prefetch hint로 넘겨주면, LHB는 다음 layer 데이터를 미리 끌어와 두고, 현재 layer 계산이 진행되는 동안 latency를 시간적으로 숨깁니다.
LHB의 사이즈는 단순한 식으로 정해집니다.
Capacity_LHB = 2 × BW_HBF × Latency_HBF
double buffering을 가정한 식입니다. 논문에서 든 예시 숫자(BW 1 TB/s, latency 20 μs)로 계산하면 약 40MB 가 됩니다. 3nm SRAM 공정 기준으로 따져도 약 8mm² 정도이고, 이는 HBM base die 면적(약 121mm²)의 6.7%에 해당합니다. base die의 여유 공간 안에서 충분히 수용 가능한 오버헤드입니다.
즉 H³는 “HBM의 빈 자리(base die 면적)에 약간의 SRAM을 추가하는” 방식으로 latency 문제를 푼 셈입니다.
시뮬레이션 결과
SK하이닉스 연구진은 H³를 Llama 3.1 405B (FP8, 약 405GB weight) + NVIDIA B200 GPU 셋업으로 시뮬레이션해 평가했습니다. HBM-only 대비 H³가 가지는 강점은 다음과 같습니다.
| 지표 (HBM-only 대비 H³ 비율) | 1M context | 10M context |
|---|---|---|
| 최대 batch size | ~2.6× | ~18.8× |
| Throughput (Tokens Per Second / request) | ~1.25× | ~6.14× |
| Throughput per power (최대) | — | ~2.69× |
long-context로 갈수록 이득이 가파르게 커집니다. 또한 단일 GPU로 1M context 추론, GPU 두 장으로 10M context 추론 이 가능했습니다. HBM-only로는 각각 8장, 32장이 필요한 워크로드입니다.
H³ 너머: HBF가 어울릴 다른 workload
H³는 HBF + LLM 추론(특히 CAG)이라는 한 조합을 보여 주었습니다. 그런데 HBF의 “약점이 약점 아닌 조건”(거대, read-only, deterministic prefetch 가능)을 만족하는 워크로드는 CAG만 있는 것이 아닙니다. 제가 생각하는 HBF 후보지 두 개를 짚어 보겠습니다.
후보 1. Mixture of Experts(MoE) weight 저장소
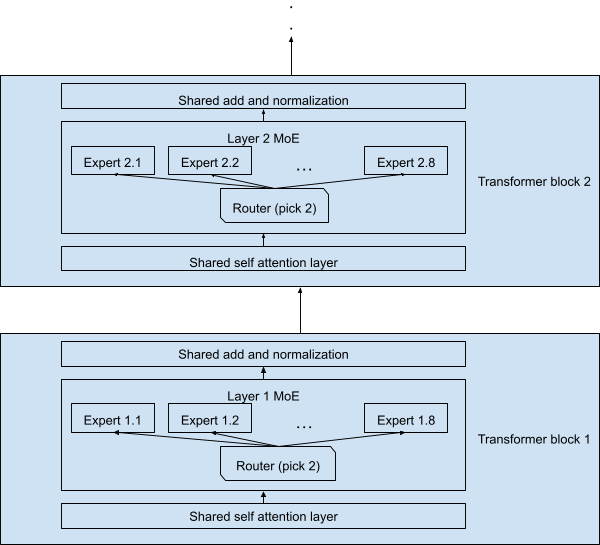
최근 frontier LLM의 상당수는 Mixture of Experts(MoE) 구조를 쓰고 있습니다. 모델 안에 수십-수백 개의 expert Feed-Forward Network(FFN) 이 있고, 토큰마다 일부만 활성화됩니다. 활성화되지 않은 expert도 메모리에는 상주해야 하므로 weight 총합이 빠르게 trillion 단위까지 증가합니다.
이 거대 weight를 HBM 위주로 운영하려면 GPU 여러 장으로 모델을 분산해야 합니다. 이 경우 각 GPU에서 다른 GPU로 weight를 옮겨주거나 중간 연산값을 옮겨주는 과정에서 추가적인 communication overhead가 필요합니다. 그러나 HBF를 통해 메모리 용량을 확장한다면 다른 그림이 가능해집니다. 모든 expert weight를 통째로 HBF에 올려, T급 모델 하나를 단일 칩에서 서빙하는 것 입니다.
- HBF: model weight (read-only)
- HBM: attention KV cache, activation, hot path
한계: 문제는 각 layer마다 어느 expert가 선택될지 예측하는 것이 힘들다는 것입니다. 입력 token이 attention layer를 거친 뒤에 router에서 어느 expert를 사용할지가 결정되기 때문입니다. expert weight를 불러오기 위한 latency를 숨기기 위해서는 어떤 expert가 선택될지 효과적으로 예측하고 HBF 측에 prefetch hint를 줄 수 있는 추가적인 지원이 필요합니다.
후보 2. RAG vector DB 저장
앞에서 다뤄본 RAG의 vector DB에서 임베딩 컬렉션은 종종 billion-scale에 달합니다. 용량이 수백 GB - 수 TB 수준이기 때문에, 실제 서비스 환경에서 이 vector DB는 HBM과 같은 memory가 아닌 host 메모리나 별도의 storage에 보관됩니다.
전형적인 RAG 추론에서는 query encoder가 만든 query embedding이 vector DB의 모든 항목과 유사도 비교를 거쳐 top-k 후보를 추리고, 추려진 top-k 후보의 raw embedding 또는 원문 chunk가 LLM의 prompt에 합쳐집니다.
이 과정에서 HBF를 활용하면 vector DB를 가속기에 매우 가까이 위치시킬 수 있고, 한 발 더 나아가 HBF와 가속기 사이에 search 전용 엔진을 두는 그림이 가능해집니다. 올해 초 발표된 연구인 HAVEN이 이러한 구조를 채택하고 있습니다. 거대 vector DB는 HBF에 두고, search 엔진을 HBF 인접에 배치해 유사도 비교·top-k 선정을 그 자리에서 처리합니다. 가속기는 좁혀진 top-k의 full payload만 받아 옵니다.
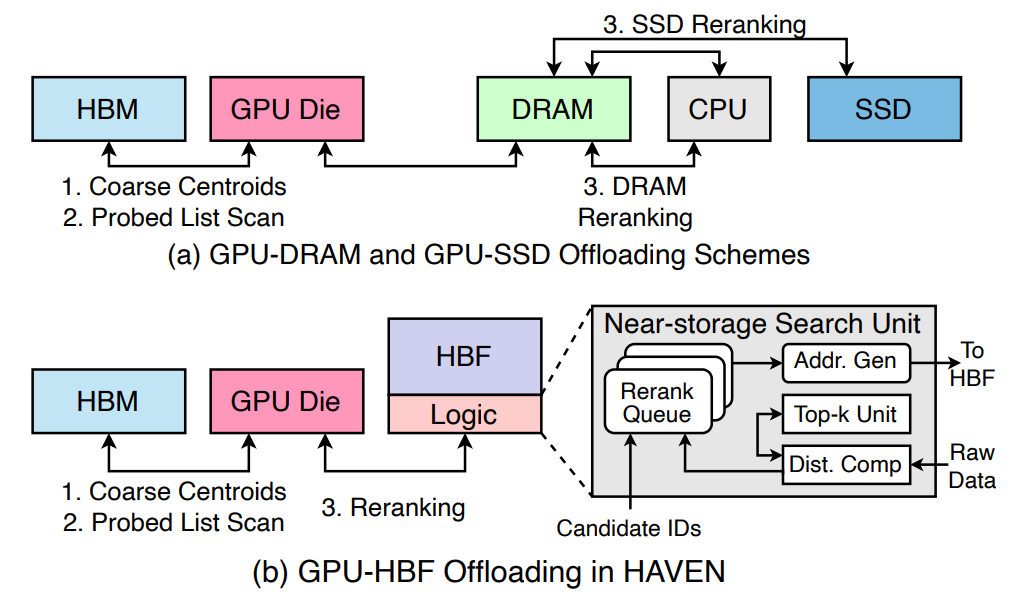
- HBF: vector DB 전체 (raw embedding + 원문 chunk)
- HBF 인접 search 엔진: 유사도 비교 + top-k 선정
- HBM / 가속기: query encoder, LLM 본체
이 구조의 이점은 traffic · latency 측면에서 살펴볼 수 있습니다. search에 따르는 read-access가 여전히 발생하지만, 그 traffic이 HBF ↔ search 엔진 사이의 짧은 경로 안에서만 흘러갑니다. HBF ↔ 가속기 사이에는 좁혀진 top-k 결과만 page 단위로 전달되므로, 가속기 측 메모리 인터페이스가 깨끗하게 유지되고, vector DB가 가속기 가까이 위치한 만큼 search 자체의 속도도 빨라집니다. RAG vector DB가 커질수록 (수십억 문서 규모) HBF의 capacity와 인접 search 엔진의 결합이 cost · throughput 양쪽에서 직접적인 이점이 됩니다.
한계: 이 구조는 vector DB 옆에 search 엔진을 별도로 둬야 하기 때문에, HBM의 표준 base die에는 없는 search 가속 로직이 추가됩니다. 즉 표준 base die가 아닌 custom base die 를 제작해야 한다는 뜻입니다. 이는 표준 packaging 라인에서 그대로 양산되는 그림이 아니라 vendor·워크로드별 맞춤 base die 제작이 필요함을 의미합니다.
마무리
이번 글에서는 HBF의 치명적인 약점들을 극복할 수 있는 워크로드의 조건과 그에 부합하는 LLM 워크로드 에 대해 알아보았습니다. 하지만 오늘 알아본 workload들은 전체 LLM 서비스의 일부에 불과합니다. HBM과 비슷한 규모의 시장성을 갖추기 위해서는 조금 더 범용적으로 사용될 수 있는 방안을 찾아야 하지만, HBF에는 극복해야 할 기술적인 과제와 한계가 여전히 존재합니다. 다음 편에서는 기존의 Flash memory가 LLM 서비스에서 어떻게 활용되는지 살펴보면서, HBF가 실질적으로 상용화되기 위해 극복해야 할 숙제들에 대해 알아보겠습니다.
추신: HyperAccel은 채용 중입니다!
메모리 계층이 다양해질수록 가속기 설계자가 풀어야 할 문제는 더 흥미로워집니다.
저는 HyperAccel DV팀에서 LLM 가속 ASIC의 하드웨어 검증을 담당하고 있습니다. 단일 칩의 검증을 넘어 메모리 계층, 시스템 통합, 워크로드 매칭까지 함께 고민할 수 있는 자리에서 매일 새로운 문제를 만나고 있습니다.
HyperAccel은 HW, SW, AI를 모두 다루는 회사입니다. 폭넓은 지식을 깊게 배우며 함께 성장하고 싶으신 분들은 언제든지 채용 사이트 에서 지원해 주세요!
Reference
- M. Ha, E. Kim, H. Kim, “H³: Hybrid Architecture using High Bandwidth Memory and High Bandwidth Flash for Cost-Efficient LLM Inference,” IEEE Computer Architecture Letters, 2026. DOI: 10.1109/LCA.2026.3660969
- B. J. Chan, C.-T. Chen, J.-H. Cheng, H.-H. Huang, “Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks,” Proc. The ACM Web Conference (WWW) 2025, 2025. arxiv:2412.15605
- SanDisk, “Memory-Centric AI: Sandisk’s High Bandwidth Flash Will Redefine AI Infrastructure”
- P.-K. Hsu, W. Xu, Q. Liu, T. Rosing, S. Yu, “HAVEN: High-Bandwidth Flash Augmented Vector Engine for Large-Scale Approximate Nearest-Neighbor Search Acceleration,” 2026. arxiv:2603.01175