
안녕하세요. HyperAccel ML팀에서 재직중인 김남윤입니다.
1편에서 Kubernetes 기반 개발 환경 구축의 배경과 전체적인 설계 방향을 다루었습니다. 이번 글에서는 그 연장선에서 CI/CD 인프라를 어떻게 재설계했는지에 대해 이야기합니다.
개발 환경이 Kubernetes 위로 올라간 이상, CI/CD 파이프라인 역시 같은 환경 위에서 운영하는 것이 아키텍처적으로 일관된 선택입니다. 이 글에서는 기존 Self-hosted Runner가 왜 장기적으로 지속 불가능했는지를 구조적으로 분석하고, ARC(Actions Runner Controller)를 도입하면서 내린 핵심 기술적 의사결정들 — DinD 모드와 Kubernetes 모드의 선택 기준, Rook-Ceph 기반 Ephemeral PVC 전략, Vault를 통한 Secret 생명주기 관리, 그리고 자체 개발한 GitHub Actions Exporter를 통한 파이프라인 관측성(Observability) 확보까지를 다룹니다.
Self-hosted Runner의 구조적 한계
기존에는 서버에 Docker 컨테이너로 Self-hosted Runner를 직접 설치하여 운영했습니다. 러너의 라벨은 호스트명(예: ha-xxx)으로 지정하고, GPU 테스트 워크플로우에서는 --all-gpu 플래그를 통해 해당 서버의 GPU 전체를 사용하는 방식이었습니다.
GitHub의 Hosted Runner(ubuntu-latest 등)를 사용하지 않은 이유는 다음과 같습니다.
- 하드웨어 종속성: FPGA 및 GPU 기반 테스트는 해당 디바이스가 물리적으로 장착된 노드에서만 실행 가능
- 네트워크 격리: 사내 Harbor 레지스트리, Vault 서버 등 내부 인프라에 외부 Runner에서 접근 불가
- 이미지 전송 비용: 수 GB 단위 Docker 이미지의 외부 build/push/pull 순환은 네트워크 대역폭과 시간 양쪽에서 비효율적
Self-hosted Runner로 이러한 제약은 해결했지만, 시간이 지나면서 이 구조 자체의 근본적인 문제가 드러났습니다.
첫째, 서버와 워크플로우의 강결합. 러너 라벨이 호스트명에 종속되어 있으므로, 서버 교체나 이름 변경 시 해당 서버를 참조하는 모든 워크플로우를 수정해야 합니다. 또한 --all-gpu와 같은 플래그 방식은 동시에 두 개의 Job이 같은 서버에 스케줄링될 때 GPU 자원 경합을 제어할 수 없어, 한쪽 Job이 예측 불가능하게 실패하는 문제가 있었습니다.
둘째, 실행 환경의 오염. Runner 프로세스가 호스트 OS 위에서 직접 실행되므로, 빌드 A에서 설치한 패키지나 변경한 시스템 설정이 빌드 B의 동작에 영향을 미칩니다. 이는 빌드 결과의 재현성을 보장할 수 없다는 의미이며, CI 파이프라인의 근본적인 목적을 훼손합니다.
셋째, 탄력적 스케일링의 부재. 동시 실행이 필요한 워크플로우 수는 시간대별로 크게 변동하지만, 서버에 고정 설치된 Runner 수는 정적입니다. Runner를 과소 프로비저닝하면 큐 대기 시간이 증가하고, 과다 프로비저닝하면 유휴 자원이 낭비됩니다.
이 세 가지 문제는 모두 Runner가 Kubernetes의 스케줄링 및 라이프사이클 관리 체계 밖에 존재하기 때문에 발생합니다. Kubernetes 클러스터가 이미 구축되어 있는 환경에서, Runner를 Pod으로 전환하여 클러스터의 제어 하에 두는 것이 논리적으로 맞다고 판단했습니다.
ARC(Actions Runner Controller)의 아키텍처
ARC는 GitHub이 공식으로 지원하는 Kubernetes Operator로, Self-hosted Runner의 전체 라이프사이클을 Kubernetes 위에서 관리합니다. ARC의 아키텍처를 이해하기 위해서는 AutoScalingRunnerSet CRD(Custom Resource Definition)를 중심으로 살펴볼 필요가 있습니다. 이 리소스가 Runner의 생성, 스케일링, 삭제를 제어하는 핵심입니다.
동작 흐름
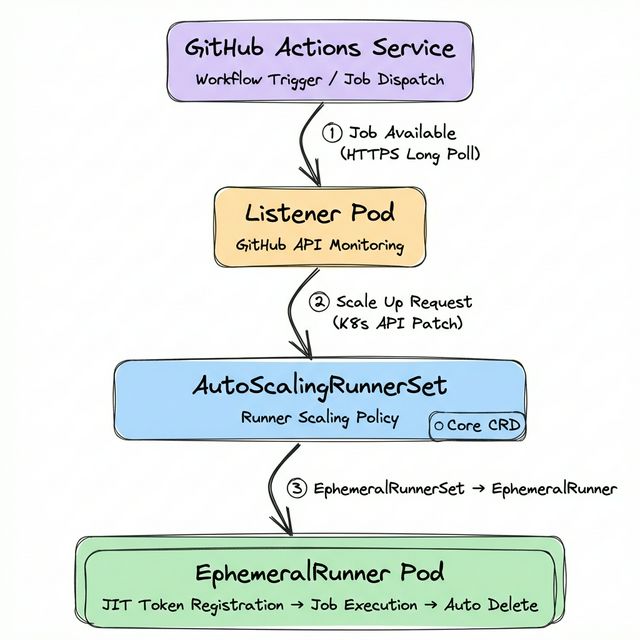
Listener Pod이 GitHub Actions Service와 HTTPS Long Poll 연결을 유지하며 새로운 Job을 감시합니다. 이 연결은 Webhook이 아닌 Polling 방식이므로, 별도의 인바운드 네트워크 설정이 불필요합니다.
Job이 감지되면 Listener는 Kubernetes API를 통해 EphemeralRunnerSet의 replica count를 patch하여 스케일 업을 요청합니다.
EphemeralRunner Controller가 JIT(Just-in-Time) 구성 토큰을 발급받아 Runner Pod을 생성하고, 해당 Pod은 GitHub Actions Service에 자신을 등록합니다.
Job 실행이 완료되면 EphemeralRunner Controller가 GitHub API를 확인한 후 파드를 삭제합니다. 이 일회성(ephemeral) 실행 모델은 이전 빌드의 잔여물이 다음 빌드에 영향을 미치는 문제를 원천적으로 차단합니다.
용도별 AutoScalingRunnerSet 설계
HyperAccel의 CI 워크로드는 범용 빌드, FPGA 합성, GPU 테스트 등 필요 자원의 스펙트럼이 넓습니다. 이를 반영하여 용도별로 7개의 AutoScalingRunnerSet을 배포하고 있습니다.
$ kubectl get autoscalingrunnerset -n arc-systems
NAME MIN MAX CURRENT RUNNING
runner-base 1 10 1 1 # DinD 모드
runner-cpu 1 10 3 3 # Kubernetes 모드
runner-cpu-largememory 1 10 1 1 # Kubernetes 모드
runner-fpga 1 3 1 1 # Kubernetes 모드
runner-gpu 1 3 1 1 # Kubernetes 모드
runner-highcpu 1 10 1 1 # Kubernetes 모드
runner-hybrid 1 4 1 1 # Kubernetes 모드
각 Scale Set은 nodeAffinity 또는 tolerations를 통해 적합한 노드에만 스케줄링됩니다.
- runner-gpu:
nvidia.com/gpu.present=true라벨이 있는 GPU 노드에 배치 - runner-fpga: FPGA가 장착된 특정 노드에만 배치
- runner-cpu / runner-cpu-largememory:
ci=large-memory라벨 노드에 배치
워크플로우에서는 runs-on 키에 Scale Set 이름을 지정하여 원하는 Runner를 선택합니다.
jobs:
gpu-test:
runs-on: runner-gpu # GPU Runner 선택
fpga-synth:
runs-on: runner-fpga # FPGA Runner 선택
build:
runs-on: runner-cpu # 범용 CPU Runner 선택
주목할 점은 runner-base만 DinD 모드를 사용하고, 나머지 6개는 모두 Kubernetes 모드를 사용한다는 것입니다. 이 두 모드의 차이는 ARC 운영에서 가장 중요한 아키텍처적 결정 중 하나입니다.
DinD 모드 vs Kubernetes 모드: 아키텍처적 차이
ARC에서 Runner Pod이 컨테이너를 실행해야 하는 경우(워크플로우의 container: 키 또는 컨테이너 액션), DinD(Docker-in-Docker) 모드와 Kubernetes 모드 두 가지 방식을 제공합니다. 이 두 모드는 컨테이너 실행의 메커니즘, 볼륨 관리, 보안 모델이 근본적으로 다릅니다.
DinD 모드 (runner-base)
Runner Pod 내부에 Docker 데몬을 Sidecar 컨테이너로 실행하는 방식입니다. HyperAccel에서는 runner-base가 이 모드로 운영됩니다.
# runner-base의 핵심 설정 (DinD 모드)
spec:
containers:
- name: runner
env:
- name: DOCKER_HOST
value: unix:///var/run/docker.sock
- name: RUNNER_WAIT_FOR_DOCKER_IN_SECONDS
value: "120"
volumeMounts:
- mountPath: /var/run
name: dind-sock # Docker 소켓 공유
- mountPath: /home/runner/_work
name: work
initContainers:
- name: init-dind-externals # Runner externals 복사
command: ["cp"]
args: ["-r", "/home/runner/externals/.", "/home/runner/tmpDir/"]
- name: dind # Docker 데몬 (Sidecar)
image: docker:dind
securityContext:
privileged: true # ⚠️ Privileged 필수
restartPolicy: Always
args: ["dockerd", "--host=unix:///var/run/docker.sock"]
volumeMounts:
- mountPath: /var/run
name: dind-sock
- mountPath: /home/runner/externals
name: dind-externals
volumes:
- name: dind-sock
emptyDir: {} # 휘발성 볼륨
- name: dind-externals
emptyDir: {}
- name: work
emptyDir: {}
DinD 모드의 구조적 특징은 다음과 같습니다.
첫째, docker:dind 이미지가 initContainers에서 restartPolicy: Always로 실행되어 Sidecar 패턴으로 동작합니다. Runner 컨테이너는 DOCKER_HOST 환경변수를 통해 이 Docker 데몬의 Unix 소켓에 접근합니다.
둘째, Docker 데몬이 컨테이너 레이어 관리, 이미지 pull, 네트워크 생성을 모두 Pod 내부에서 수행하므로, 노드의 containerd 이미지 캐시를 활용하지 못합니다. 이미 노드에 캐시된 이미지라 하더라도 DinD 데몬이 별도로 다시 pull해야 합니다.
셋째, Docker 데몬 실행을 위해 privileged: true가 필수입니다. 이는 Pod에게 호스트의 거의 모든 커널 기능에 대한 접근 권한을 부여하므로, 보안 정책이 엄격한 환경에서는 신중한 판단이 필요합니다.
넷째, 모든 볼륨이 emptyDir로 구성되어 있어 Pod이 삭제되면 데이터가 함께 사라집니다. Docker 빌드 캐시 역시 보존되지 않습니다.
Kubernetes 모드 (runner-cpu, runner-gpu, runner-fpga 등)
Runner Pod이 Kubernetes API를 호출하여 워크플로우의 컨테이너 Step을 별도의 Pod으로 생성하는 방식입니다. ARC의 Container Hook(runner-container-hooks)이 이 과정을 중개합니다.
# runner-cpu의 핵심 설정 (Kubernetes 모드)
spec:
containers:
- name: runner
env:
- name: ACTIONS_RUNNER_CONTAINER_HOOKS
value: /home/runner/k8s/index.js
- name: ACTIONS_RUNNER_CONTAINER_HOOK_TEMPLATE
value: /home/runner/k8s/worker-podspec.yaml
- name: ACTIONS_RUNNER_REQUIRE_JOB_CONTAINER
value: "true"
volumeMounts:
- mountPath: /home/runner/_work
name: work
- mountPath: /home/runner/k8s/worker-podspec.yaml
name: hook-template
subPath: worker-podspec.yaml
volumes:
- name: work
ephemeral:
volumeClaimTemplate: # Ephemeral PVC
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: rook-ceph-block
resources:
requests:
storage: 15Gi
- name: hook-template
configMap:
name: arc-hook-cpu # worker-podspec ConfigMap
Kubernetes 모드의 핵심 메커니즘은 다음과 같습니다.
ACTIONS_RUNNER_CONTAINER_HOOKS는 Container Hook의 진입점(index.js)을 지정합니다. 워크플로우에서 container: 키를 사용하면, Runner가 직접 실행하는 대신 이 Hook이 Kubernetes API를 호출하여 별도의 Workflow Pod을 생성합니다.
ACTIONS_RUNNER_CONTAINER_HOOK_TEMPLATE는 생성될 Workflow Pod의 스펙 템플릿(worker-podspec.yaml)을 지정합니다. 이 템플릿은 ConfigMap으로 관리되며, Runner 유형별로 다른 ConfigMap을 참조합니다(arc-hook-cpu, arc-hook-gpu, arc-hook-fpga 등).
ACTIONS_RUNNER_REQUIRE_JOB_CONTAINER=true는 모든 Job이 반드시 container: 키를 통해 컨테이너 내에서 실행되도록 강제합니다. 이를 통해 Runner Pod 자체에서 직접 작업이 실행되는 것을 방지합니다.
실제로 Job이 실행되면 Runner Pod 외에 별도의 Workflow Pod이 생성됩니다.
$ kubectl get pods -n arc-systems | grep runner-cpu-hh7xv
runner-cpu-hh7xv-runner-4tvrs 1/1 Running 0 9h # Runner Pod
runner-cpu-hh7xv-runner-4tvrs-workflow 1/1 Running 0 4m # Workflow Pod (Container Hook)
두 모드의 구조적 비교
| 항목 | DinD 모드 (runner-base) | Kubernetes 모드 (runner-cpu 등) |
|---|---|---|
| 컨테이너 실행 | Pod 내부 Docker 데몬 | Kubernetes API로 별도 Pod 생성 |
| Privileged 모드 | 필수 (Docker 데몬) | 선택적 (worker-podspec에서 결정) |
| 이미지 캐시 | DinD 내부에 격리 (노드 캐시 미활용) | 노드의 containerd 캐시 공유 |
| 작업 볼륨 | emptyDir (휘발성) | Ephemeral PVC (rook-ceph-block, 15Gi) |
| Step 격리 | 동일 Docker 네트워크 | Step별 독립 Pod 가능 |
| Docker CLI | 완전 호환 | 비호환 (Container Hook 경유) |
| 설정 복잡도 | 낮음 | 높음 (worker-podspec, RBAC 등) |
| 적합한 워크로드 | Docker build/push 필요 시 | 컨테이너 내 빌드/테스트 |
runner-base를 DinD 모드로 유지하는 이유는, Docker CLI를 직접 사용해야 하는 워크플로우(이미지 빌드, 레지스트리 push 등)가 존재하기 때문입니다. Kubernetes 모드에서는 Docker 데몬이 없으므로 docker build를 직접 실행할 수 없습니다.
볼륨 전략: Ephemeral PVC와 캐시 계층
Runner의 볼륨 설계는 빌드 성능과 안정성에 직접적인 영향을 미칩니다. DinD 모드와 Kubernetes 모드에서 볼륨 전략이 질적으로 다릅니다.
DinD 모드의 볼륨: emptyDir
# runner-base의 볼륨 (DinD 모드)
volumes:
- name: dind-sock # Docker 소켓 공유 (Runner ↔ DinD 데몬)
emptyDir: {}
- name: dind-externals # Runner externals 복사본
emptyDir: {}
- name: work # 워크스페이스 (checkout, 빌드 산출물)
emptyDir: {}
- name: harbor-ca # Harbor CA 인증서
configMap:
name: harbor-ca
모든 작업 볼륨이 emptyDir이므로 Pod 삭제 시 데이터가 소멸합니다. Docker 빌드 캐시도 유지되지 않기 때문에, 이전 빌드에서 캐시된 레이어를 재사용할 수 없습니다 — 이는 대규모 이미지 빌드에서 불리한 구조입니다.
Kubernetes 모드의 볼륨: Ephemeral PVC + 캐시 계층
# runner-cpu의 볼륨 (Kubernetes 모드)
volumes:
- name: work
ephemeral:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: rook-ceph-block # Ceph 블록 스토리지
resources:
requests:
storage: 15Gi # Runner당 15Gi
- name: hook-template
configMap:
name: arc-hook-cpu # worker-podspec 템플릿
Kubernetes 모드에서는 작업 디렉토리(/home/runner/_work)에 Ephemeral PVC를 사용합니다. emptyDir과 달리 Rook-Ceph 블록 스토리지를 백엔드로 하므로 노드 로컬 디스크 상태에 무관하게 안정적인 I/O를 제공하며, Runner당 15Gi의 전용 볼륨이 할당됩니다. Ephemeral PVC는 Runner Pod의 라이프사이클에 종속되어 Pod 삭제 시 함께 삭제되므로, 스토리지 누수 없이 일관된 운영이 가능합니다.
worker-podspec의 캐시 볼륨 전략
Container Hook이 생성하는 Workflow Pod에는 추가적인 캐시 볼륨이 마운트됩니다. 이 설정은 각 Runner 유형별 ConfigMap(arc-hook-cpu, arc-hook-gpu 등)의 worker-podspec.yaml에 정의됩니다.
# arc-hook-cpu ConfigMap (worker-podspec.yaml) — 일부 발췌
spec:
containers:
- name: "$job"
env:
- name: HF_HOME
value: /mnt/cache/huggingface
- name: CCACHE_DIR
value: /mnt/cache/ccache
- name: UV_CACHE_DIR
value: /mnt/cache/uv
resources:
limits:
cpu: "32"
memory: "128Gi"
volumeMounts:
- name: huggingface-cache
mountPath: /mnt/cache/huggingface
- name: ccache-cache
mountPath: /mnt/cache/ccache
- name: uv-cache
mountPath: /mnt/cache/uv
volumes:
- name: huggingface-cache
persistentVolumeClaim:
claimName: huggingface-runner-pvc # NFS (모든 Runner 공유)
- name: ccache-cache
hostPath:
path: /tmp/ccache # 노드 로컬 캐시
- name: uv-cache
hostPath:
path: /tmp/uv # 노드 로컬 캐시
볼륨 전략을 계층별로 정리하면 다음과 같습니다.
| 계층 | 볼륨 유형 | 용량 | 생명주기 | 용도 |
|---|---|---|---|---|
| 작업 디렉토리 | Ephemeral PVC (rook-ceph-block) | 15Gi / Runner | Pod 종속 | checkout, 빌드 산출물 |
| 모델 캐시 | PVC (huggingface-runner-pvc) | 영구 (모든 Runner 공유) | HuggingFace 모델, 데이터셋 | |
| 빌드 캐시 | hostPath | 노드 디스크 | 노드 종속 | ccache, uv 패키지 캐시 |
특히 huggingface-runner-pvc는 모든 Runner가 공유하는 PVC로, 수 GB 단위의 LLM 모델을 매 빌드마다 다운로드하는 것을 방지합니다. ccache와 uv 캐시는 hostPath를 사용하여 같은 노드에 스케줄링된 Runner 간에 공유됩니다.
단, hostPath 캐시는 동일 노드에 복수의 Runner가 동시 실행될 경우 lock 경합이 발생할 수 있습니다. 실제로 uv 캐시에서 이 문제를 경험했으며, UV_CACHE_DIR 환경변수로 Runner별 캐시 경로를 분리하여 해결했습니다.
Vault: Secret 생명주기 관리
CI/CD 파이프라인에서 Secret(Registry 인증 정보, API 키, 서명 키 등)의 관리는 보안과 운영 양쪽에서 중요한 문제입니다.
GitHub Secrets의 한계
GitHub의 Repository Secrets, Organization Secrets는 소규모 환경에서는 충분합니다. 그러나 레포지터리가 수십 개로 확장되면 다음과 같은 문제가 발생합니다.
- 중복 관리: 동일 Secret을 여러 레포지터리에 각각 등록 → 로테이션 시 전수 업데이트 필요
- 이력 추적 부재: Secret의 마지막 갱신 시점, 변경 주체를 확인할 수 없음
- 권한 분리 불가: Secret 접근에 레포지터리 Admin 권한이 요구됨
Vault를 도입해야겠다고 생각한 가장 중요한 계기는 devcontainer 이미지 태그 관리였습니다. 기존에는 devcontainer 이미지 태그를 GitHub Repository Variables(vars.DEVCONTAINER_IMAGE_AIDA_CU126 등)로 관리했습니다. 새 이미지가 빌드될 때마다 담당 개발자가 수동으로 변수를 업데이트해야 했고, 이 과정에서 누락이 빈번하게 발생하여 오래된 이미지로 워크플로우가 실행되는 문제가 있었습니다. Vault 도입 후에는 CI 파이프라인이 빌드 완료 시 최신 이미지 태그를 Vault에 자동으로 기록하고, 후속 워크플로우와 Developer Portal이 needs.fetch-secrets.outputs를 통해 항상 최신 값을 참조하는 구조로 전환했습니다. 이미지 버전 정보를 사람이 관리/수정하는 과정이 완전히 제거됩니다.
Vault 도입과 인증 전략
HashiCorp Vault를 Kubernetes 클러스터에 배포하고, 접근 주체에 따라 서로 다른 Auth Method를 적용했습니다.
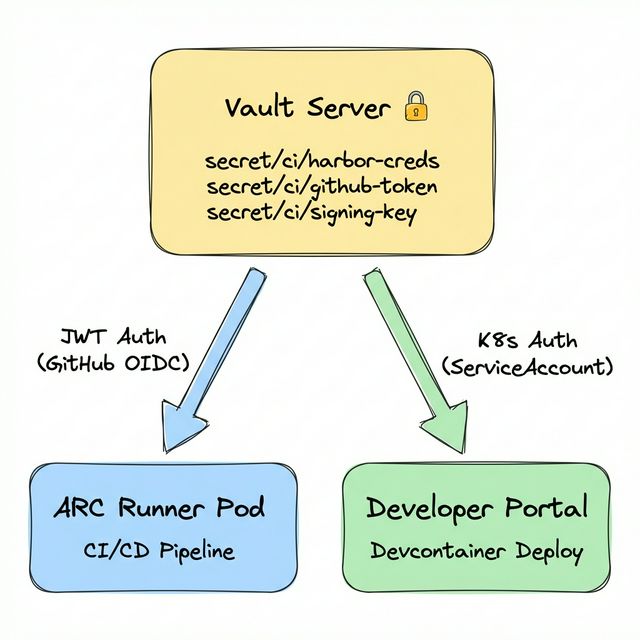
ARC Runner는 JWT Auth Method를 사용합니다. GitHub Actions의 OIDC provider가 발급하는 ID Token을 Vault에 제출하여 인증하는 방식입니다. 워크플로우에 permissions: id-token: write를 선언하면 GitHub이 OIDC 토큰을 자동으로 발급하고, hashicorp/vault-action이 이를 Vault에 전달합니다.
# 워크플로우에서 Vault Secret 주입 (JWT Auth)
permissions:
id-token: write # GitHub OIDC 토큰 발급 허용
contents: read
steps:
- name: Import Secrets from Vault
uses: hashicorp/vault-action@v3
with:
url: ${{ secrets.VAULT_ACTION_URL }}
method: jwt # GitHub OIDC JWT
role: ${{ secrets.VAULT_ACTION_ROLE }}
exportToken: true
secrets: |
secret/data/harbor username | HARBOR_USERNAME ;
secret/data/harbor password | HARBOR_PASSWORD
반면 Developer Portal은 Kubernetes 클러스터 내부에서 직접 실행되는 Pod이므로, Kubernetes Auth Method를 통해 ServiceAccount 토큰으로 인증합니다. 이렇게 접근 주체의 특성에 맞는 Auth Method를 분리 적용함으로써, 각 경로의 보안 모델을 최적화할 수 있습니다.
이 구조의 핵심적인 이점은 두 가지입니다.
단일 관리 지점: Secret 로테이션 시 Vault에서 한 번만 변경하면 모든 파이프라인에 즉시 반영됩니다.
감사 로그(Audit Log): 모든 Secret 접근에 대해 who, when, what이 기록되어 보안 감사 요구사항을 충족합니다.
fetch-secrets: 재사용 워크플로우를 통한 Secret 중앙화
Vault를 도입했더라도, 각 워크플로우가 개별적으로 Vault 인증과 Secret 조회 로직을 구현한다면 중복 코드가 확산됩니다. 이를 방지하기 위해 fetch-secrets라는 재사용 워크플로우(GitHub Actions의 workflow_call)를 설계했습니다. Vault 인증(JWT)과 Secret 조회 로직을 이 워크플로우 한 곳에 캡슐화하고, 호출 측에서는 출력값만 참조하는 구조입니다.
# docker-build-push.yml — 호출 측
jobs:
fetch-secrets:
uses: ./.github/workflows/fetch-secrets.yml # Vault 인증/조회를 위임
secrets: inherit
build:
needs: [fetch-secrets]
steps:
- name: Log in to Harbor
uses: docker/login-action@v3
with:
registry: ${{ needs.fetch-secrets.outputs.harbor_registry_url }}
username: ${{ needs.fetch-secrets.outputs.harbor_username }}
password: ${{ needs.fetch-secrets.outputs.harbor_password }}
빌드 워크플로우는 Vault의 존재조차 알 필요 없이, needs.fetch-secrets.outputs에서 필요한 값을 가져오기만 하면 됩니다. Vault의 Secret path가 변경되더라도 fetch-secrets.yml 한 곳만 수정하면 전체 파이프라인에 반영됩니다.
GitHub Actions Exporter: 파이프라인 관측성 확보
CI/CD 인프라의 운영 성숙도를 높이기 위해서는 관측성(Observability)이 필수적입니다. GitHub Actions 웹 UI는 개별 워크플로우의 상태 확인에는 적합하지만, 여러 레포지터리에 걸친 전체적인 추세, 병목 지점, 이상 징후를 실시간으로 파악하기에는 한계가 있습니다.
이를 해결하기 위해 GitHub Actions Exporter를 Go 언어로 자체 개발했습니다.
개발 배경
기존 오픈소스 Exporter들이 제공하지 않았던 세 가지 메트릭이 필요했습니다.
- 러너 레이블별 큐 대기 시간: ARC Runner와 Hosted Runner를 혼용하는 환경에서 병목 지점을 식별하기 위함
- 연속 실패 추적: 특정 워크플로우의 연속 실패를 실시간으로 감지하여 조기에 대응하기 위함
- 브랜치별 분석:
main과 feature 브랜치의 빌드 패턴이 다르므로 분리된 분석이 필요
아키텍처와 주요 메트릭
GitHub REST API ──→ Collector ──→ /metrics endpoint
│
Prometheus 스크랩
│
Grafana 대시보드 + AlertManager
| 메트릭 | 설명 | 활용 |
|---|---|---|
workflow_runs_total | 워크플로우 총 실행 횟수 | 사용량 추이 분석 |
workflow_failure_rate | 실패율 (0.0 ~ 1.0) | 품질 모니터링 |
workflow_duration_seconds | 실행 시간 히스토그램 | 성능 회귀 감지 |
workflow_queue_time_seconds | 큐 대기 시간 | Runner 부족 감지 |
workflow_consecutive_failures | 연속 실패 횟수 | 즉각 알림 트리거 |
workflow_runs_in_progress | 현재 실행 중 워크플로우 | 실시간 상태 파악 |
workflow_runs_by_branch_total | 브랜치별 실행 횟수 | 브랜치 전략 분석 |
Kubernetes Deployment로 배포하고 Prometheus ServiceMonitor로 스크랩합니다. ARC의 Listener Pod에도 Prometheus 메트릭 annotation이 설정되어 있어, Runner 스케일링 관련 메트릭도 함께 수집됩니다.
관측성을 통한 의사결정
대시보드를 통해 실제로 감지하고 대응한 사례들입니다.
- 큐 대기 시간 급증: 특정 시간대에 동시 Job이 몰리면서
maxRunners한도에 도달 → Scale Set의 최대 Runner 수를 조정 - 특정 워크플로우 실패율 50% 돌파: Docker 레이어 캐시 만료로 인한 빌드 실패 패턴 식별 → 캐시 전략 수정
- 빌드 시간의 점진적 증가: 테스트 케이스 증가로 30분 → 45분 소요 → 테스트 병렬화 적용
# 실패율 20% 초과 워크플로우 식별
github_actions_workflow_failure_rate > 0.2
# 큐 대기 60초 초과 — Runner 부족 징후
github_actions_workflow_queue_time_seconds_avg > 60
# 연속 실패 3회 이상 — 즉각 대응 필요
github_actions_workflow_consecutive_failures >= 3
인프라 운영 및 유지보수 자동화
구축된 인프라의 안정성과 최신성을 유지하기 위해 운영 작업을 자동화했습니다.
Vault 데이터 백업
Vault에 저장된 Secret과 정책(Policy)은 클러스터 장애 시 복구를 위해 필수적인 데이터입니다. 매주 일요일 오전, Raft 스냅샷을 생성하여 두 곳의 저장소(AWS S3, 사내 MinIO)에 이중으로 백업합니다. 오래된 백업은 Retention Policy(기본 6일)에 따라 자동으로 정리됩니다.
ARC 및 Runner 버전 추적
GitHub Actions Runner와 Container Hook은 지속적으로 업데이트됩니다. 매주 월요일, 최신 릴리스 버전을 확인하고 현재 버전을 비교하는 버전 추적 워크플로우가 실행됩니다. 새로운 버전이 감지되면 자동으로 PR을 생성하여 관리자에게 알림을 보내며, 이를 통해 Runner 환경을 항상 최신 상태로 유지할 수 있습니다.

전체 아키텍처
지금까지 소개한 모든 컴포넌트를 하나로 구성하면 다음과 같은 아키텍처가 됩니다.
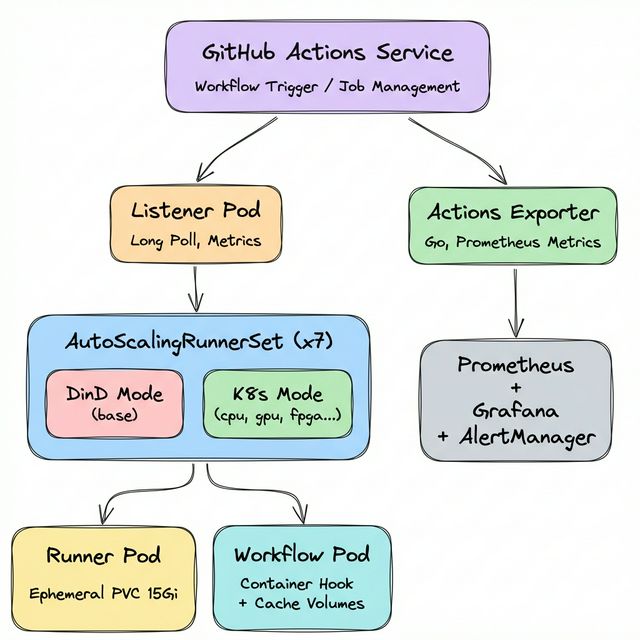
| 컴포넌트 | 역할 |
|---|---|
| AutoScalingRunnerSet (x7) | 용도별 Runner 스케일링 정책 (DinD 1 + K8s 모드 6) |
| Listener Pod | GitHub Long Poll로 Job 감지, Prometheus 메트릭 노출 |
| EphemeralRunner | JIT 토큰 등록 → Job 실행 → 자동 삭제 |
| Container Hook + worker-podspec | Kubernetes 모드에서 Workflow Pod 생성 및 볼륨/리소스 주입 |
| Vault | Secret 중앙 관리, JWT(ARC) / K8s Auth(Portal) 이중 인증 |
| Rook-Ceph | Ephemeral PVC 백엔드 (Runner 작업 디렉토리) |
| GitHub Actions Exporter | 워크플로우 메트릭 수집, Prometheus에 노출 |
도입 후 정량적 변화
| 항목 | 전환 전 | 전환 후 |
|---|---|---|
| 빌드 큐 대기 시간 | 평균 3분 이상 | 15초 이내 |
| Secret 관리 | 레포지터리별 수동 | Vault 단일 관리 |
| 장애 인지 소요 시간 | 문의 후 확인 | Grafana 대시보드 실시간 감지 |
| 하드웨어 자원 관리 | 수동 서버 배치 | nodeAffinity 자동 스케줄링 |
| 빌드 재현성 | 비결정적 | Ephemeral Pod으로 보장 |
GPU와 FPGA처럼 가용 자원이 제한된 하드웨어의 경우, maxRunners(각각 3)를 통해 동시 실행 Job 수를 해당 하드웨어의 가용 수량에 맞추어 자원 경합을 방지하고 있습니다.
마치며
이 글에서는 Self-hosted Runner의 구조적 한계에서 출발하여, ARC 기반으로 CI/CD 인프라를 전면 재설계한 과정을 다루었습니다. 특히 DinD 모드와 Kubernetes 모드의 아키텍처적 차이, Rook-Ceph 기반 Ephemeral PVC와 다층 캐시 전략, Vault를 통한 Secret 생명주기 관리, 그리고 자체 개발한 Exporter를 통한 파이프라인 관측성 확보까지 — 단순히 도구를 도입하는 것을 넘어, 왜 이러한 설계를 선택했는지의 기술적 근거를 공유하고자 했습니다.
읽어주셔서 감사합니다!
추신: HyperAccel은 채용 중입니다!
Vault는 secret을 관리하고, ARC는 워크로드를 스케줄링하고, Rook은 스토리지를 추상화하고, Prometheus는 모든 것을 관측합니다. 각자 다른 역할이지만, 하나의 클러스터 안에서 조합될 때 비로소 완성된 시스템이 됩니다. HyperAccel도 마찬가지입니다 — HW, SW, AI 각 분야의 전문가들이 모여 하나의 목표를 향해 움직이고 있습니다. 이 조합에 함께하고 싶으시다면, HyperAccel Career에서 지원해 주세요.