SDD: Adapting to the Changing Meaning of Work
Table of Contents
- Introduction
- SDD? How is it different from BDD, TDD, RDD?
- The Era of Vibe Coding Ended Before It Began, Engineering Returns
- A Taste of LLM: What are Context Window and Attention?
- Why SDD: Structural Limitations and Collapse of Chat-Based Coding
- Emergence and Standardization of SDD Workflow
- Next-Gen Tools for SDD
- Conclusion: Where Should We Go?
- P.S.
- Reference
Introduction
Hello, I am Seungbin Shin, working as an RTL Designer at HyperAccel.
I want to do my job well, but I don’t want to invest more time than necessary to achieve that goal.
In other words, I am always thinking about “how to increase the cost-effectiveness of work.” If I can improve work quality and do more work in the same amount of time, it is a gain for both me and the company.
2025 was a year where the form of the software development industry changed significantly, enough for many reading this to feel it, along with the development and advancement of generative AI, which was more active than in ‘23 and ‘24.
Even I, a hardware guy with zero knowledge of software development, could create the app I wanted after a few conversations, and I could whip up a homepage too.
However, when I tried to add features I wanted to the app one by one, or modify the design to look better, after a few conversations, bugs I had solved before would reappear, or it would do random things like placing buttons wherever it wanted.
Eventually, I could reach “something in the form I wanted”, but I faced many situations where it was difficult to improve further from a level that was roughly 2%, no, 10% lacking, and the progress saturated.
When this happened, since I am not an expert in that language, I couldn’t modify it based on that codebase, and even if I were an expert, it would have taken a lot of time to understand the spaghetti code tangled by multiple conversations.
I could compromise and use it myself, but thinking about servicing or selling this to people, I thought it would be absolutely unmanageable, and eventually, I felt that this form of development had clear limits.
Of course, it could be a problem because I am not an expert, but even for experts, this type of work process would likely consume more time in code review, refactoring, complying with rules, generating tests, etc., and ultimately has a much higher possibility of leading to a decrease rather than an increase in productivity.
It might look like I’m doing a lot of work, but I’m just producing a lot of useless code and spending a lot of time on maintenance, so the value produced per time could be lower.
I think many of you reading this post have had similar experiences.
Let’s learn about SDD, a methodology to avoid this vicious cycle and obtain the results we want by extracting high-quality tokens from LLMs as efficiently and quickly as possible.
The content of this post is based on what I have personally studied and experienced. If there are any errors, please let me know in the comments at any time.
SDD? How is it different from BDD, TDD, RDD?
In the past, and perhaps still today, many developers use various methodologies to improve process and quality while increasing collaboration efficiency when working with people. Let me introduce a few popular methodologies.
BDD (Behavior-Driven Development)
BDD (Behavior-Driven Development) is a methodology where you first write a scenario defining user behavior in natural language, and then convert it into test code for development. For example, instead of saying “Implement login function”, you write a requirements specification based on concrete user actions like “The user enters an ID and enters a password. Then, when the login button is clicked, it checks the password; if correct, it moves to the main page, and if incorrect, it shows an error message and does not move to the main page.”
TDD (Test-Driven Development)
TDD (Test-Driven Development) is a methodology where you write the minimum test first, write code that passes it, and constantly refactor while developing. Similarly, if you had to implement a login function, development proceeds in a direction of implementing increasingly complex functions starting from “a function that returns false when the ID is empty”, “a function that handles exceptions when the password is wrong”.
RDD (README Driven Development)
RDD (README Driven Development) is about writing the most perfect software manual before writing code, imagining how the user will install and use it while developing. It is especially important in open-source projects, and the point is that implementation takes place after writing a guide for other developers who will use this function.
The biggest difference between the 3 methodologies described above and SDD (Spec-Driven Development) lies in “who the promise is for”.
Basically, existing methodologies were tools for “me” or “our team” to work well. When writing documents, corporate culture or internal characteristics might melt in, making it difficult for other teams to understand. However, since the purpose is to improve internal quality in the first place, it doesn’t matter much.
Now we spend much more time creating results by talking to LLMs than wrestling with code with people. However, even within coding IDEs like Cursor or Antigravity, we change code generation models, start in different sessions, and sometimes scrape code to ask models on other web pages. Every time this happens, LLMs, which are probabilistic generative models, inevitably produce slightly different results. And the biggest problem is that LLMs are not interested in “corporate culture”. In other words, they lack “context understanding” of our development environment and style.
SDD is a strict promise between “me” and “LLM (AI Agent)”. It operates as a rule that any model must follow, and plays a role in guaranteeing the connection and compatibility of generated codes. The era of treating LLMs like magic wands is passing quickly, and the era where methodologies to handle LLMs well are needed has arrived. Of course, SDD is not a panacea. But at least it gives direct help in productivity improvement in that you can continuously verify with one document and obtain results closest to the desired form.
We briefly looked at what SDD feels like, but does that mean TDD is a dead methodology and we should only use SDD? No. SDD is not a methodology that replaces TDD, but a methodology that complements parts that TDD cannot fill while using LLMs more efficiently.
You might still question why SDD is needed, hearing that it’s about generating code after reading a manual, and why this is needed in principle. From the next section, let’s look in more detail from the background of SDD’s emergence to theoretical parts.
The Era of Vibe Coding Ended Before It Began, Engineering Returns
“Huh? This works?”
I remember the thrill when I first asked ChatGPT 3 to write code during my undergraduate days.
The experience of it understanding perfectly and spitting out code even when I spoke roughly was truly new. In the industry, they call this Vibe Coding. Because we could create results with just a feeling (Vibe) through communication with AI.
But this period was short.
As I experienced before, when the project scale grew even a little, or after going through a few conversations, the AI started becoming stupid rapidly.
It forgets variable names, recreates bugs I fixed earlier, and eventually falls into the Doom Loop of modification that makes you think “I’ll just write it myself”.
Even when I realized something was wrong, the code was often too messy and twisted that refactoring or modifying it was almost impossible.
The failure of Vibe Coding is not simply a performance issue of AI models.
This was an accident that inevitably occurs when the intrinsic limitations of LLMs relying on probabilistic generation meet the absence of engineering.
Now is the time to look at AI from the perspective of “Engineering”, not “Magic”.
A Taste of LLM: What are Context Window and Attention?
Why does AI become stupid when the conversation gets long? To understand this, we need to understand Context Window and Attention Mechanism, which are the brain structures of LLMs.
Context Window: A Movie Seen Through a Window
LLM’s memory is not infinite. You must have had times when you thought “It forgot this?” while using chat models.

Have you seen this toy? I remember playing with it when I was young; it’s a toy that uses optical illusion where you can see a horse running through a slit when spun around.
LLM’s Context Window can be thought of as similar to the size of the slit in this toy. In other words, the amount of information it can see at once is limited.
Even the memory to store that information is finite, so it cannot be increased infinitely. Eventually, information that goes out the window is unprocessed or forgotten.
Attention Mechanism: Cocktail Party Effect
Even if the window mentioned above became really wide and infinite, there is another problem. It becomes very difficult to compare and choose what is important.
When we have ten friends, we can remember their faces, names, personalities, and maybe even birthdays and phone numbers.
And all ten friends are precious. But what if there are ten thousand friends? A hundred thousand? It becomes difficult to even remember their names.
Cocktail Party Effect is a phenomenon where party attendees selectively focus on and understand the conversation with their interlocutor despite the surrounding noise. This selective perception or attention, where one ignores the surrounding environment and selectively accepts only meaningful information, refers to the psychological phenomenon that occurs. It is also called ‘self-referential effect’, ‘banquet hall effect’, and ‘feast house effect’.
The Attention Mechanism is quite similar to the Cocktail Party Effect. We’ve all had the experience of hearing a specific friend’s voice well in a noisy bar.
LLMs also have a mathematical mechanism to find important content, that is, key requirements, in tens of thousands of lines of code and chat logs, and that is the Attention Mechanism. It is also the concept presented in the famous paper “Attention is all you need” that you might have heard of or read.
When the conversation is short, AI accurately finds important sections. But if the conversation continues for hundreds of turns, the party hall becomes a mess, and the AI slows down, makes mistakes, and spits out different answers.
Why SDD: Structural Limitations and Collapse of Chat-Based Coding
Once we know this technical background, it becomes clear why we suffered when writing code in chat windows.
Lost in the Middle Phenomenon: According to research, LLMs remember the beginning and end of text well, but amazingly forget the content in the middle. If data structures or utility functions defined early in the chat are buried in the middle of the conversation, the AI starts creating already existing functions anew (duplicate code) or creating random variables to use.
Attention Dilution: As the conversation gets longer, the ‘concentration’ that AI can pour into each piece of information decreases. Important requirements get diluted mixed between small talk or error logs. Simply typing “No, not that” made things harder for our LLM. Emotionally and memory-wise…
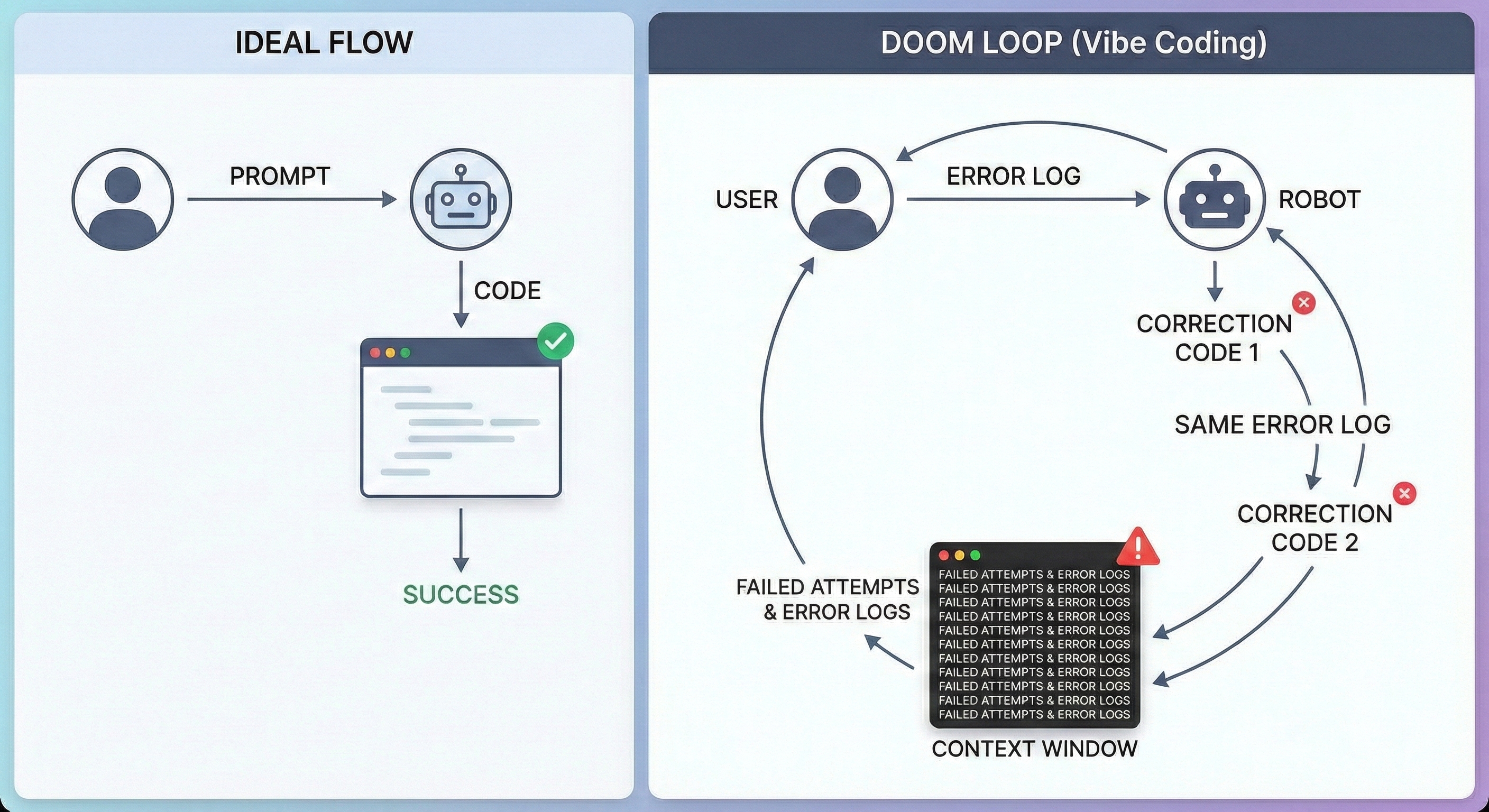
Doom Loop: When an error occurs and you give the log, usually AI gives correction code. But the same error occurs again. The AI’s context window becomes filled with ‘failed attempts’ and ’error logs’, becoming a state where it has learned wrong answer patterns rather than finding the right answer. It’s rare that it actually learns and gives that answer forever, but finding the question itself becomes difficult in a window filled with wrong answers that aren’t even correct.
Eventually, “using chat logs as specs” itself was a game structurally bound to fail. So we must switch to SDD, providing refined documents while minimizing chat. We must minimize chat logs, organize necessary contents into documents, and switch to a method where AI writes code based on documents.
Emergence and Standardization of SDD Workflow
The core of SDD is simple. It’s the philosophy that Code is volatile, Spec is permanent. Code is treated as an ‘Artifact’ that can be extracted from the spec at any time, and the ‘Source of Truth’ we must manage becomes the ‘Natural Language Specification’. Especially as the performance of LLM models improves geometrically, rather than worrying about “code quality”, we should value “the quality of the spec document” I write more. The literary literacy I lack the most is becoming necessary again…
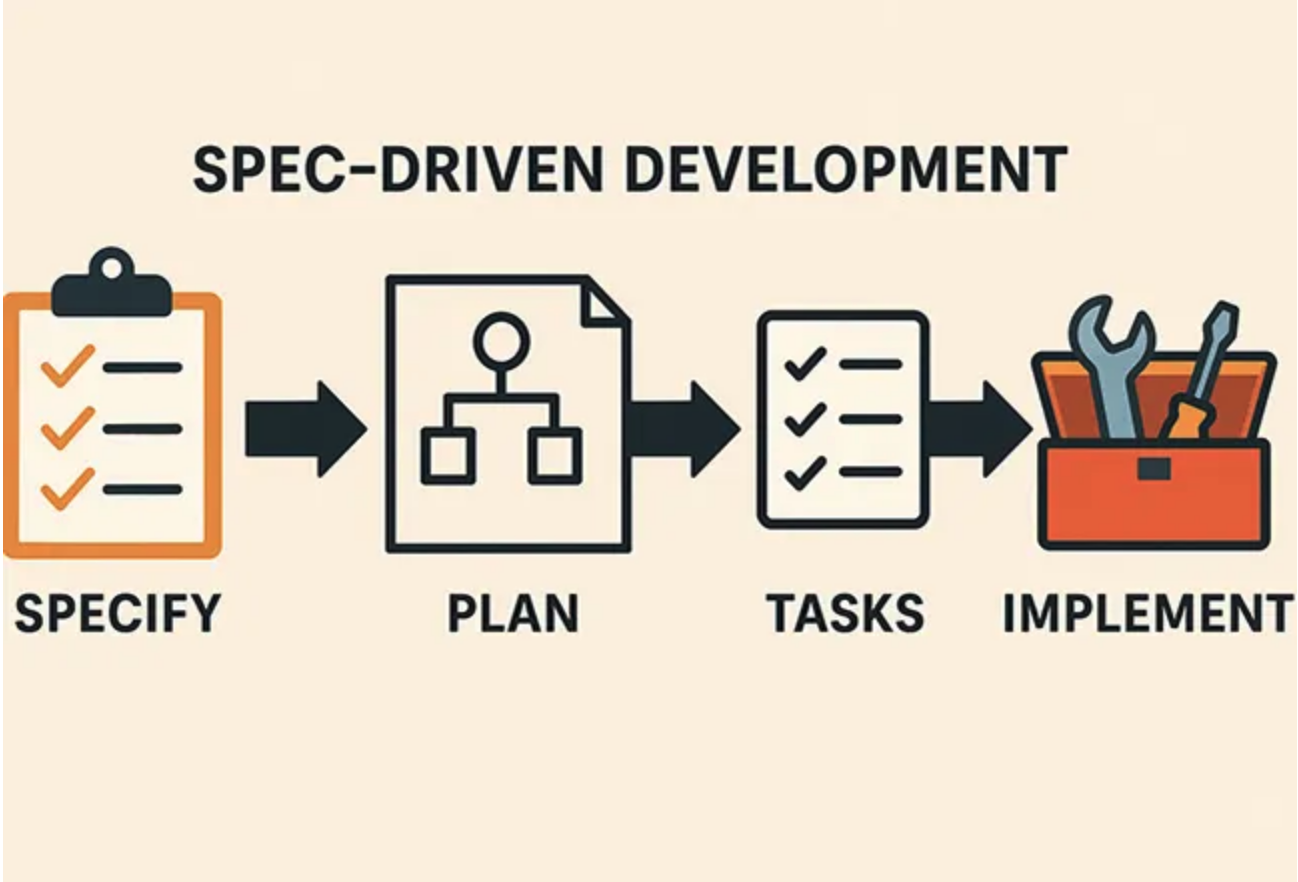
The general SDD workflow is as follows.
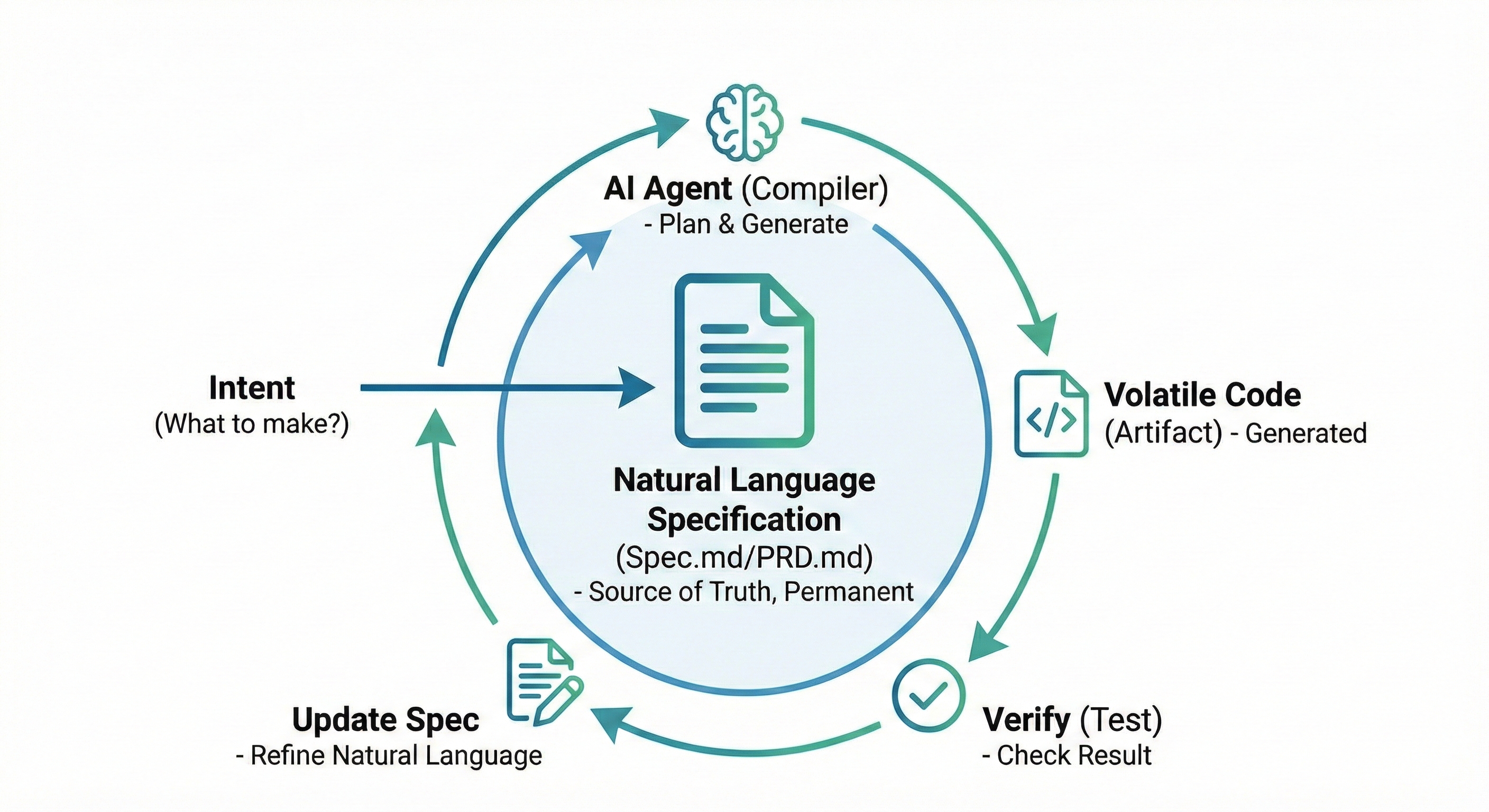
Intent: Define “What do you want to make?”.
Spec Writing: Write spec.md or PRD.md files conversing with AI. Fill this with features, data models, and constraints tightly. This file is continuously referenced, mutually modified, and continuously updated and preserved by LLM.
Generation: Command “Implement according to this spec”. AI sets up an implementation plan (Plan) looking at the spec and writes code. I felt Antigravity is especially good at this part.
Verification: Is the result strange? Don’t fix the code. Fix the spec and generate again, or write a document for testing.
This process is like giving user source code to a compiler to extract an executable file. Here, ‘source code’ is ’natural language spec’, and ‘compiler’ becomes ‘AI Agent’. Wait, are you curious about what a compiler is? Then try reading this post.
Next-Gen Tools for SDD
You probably have a thought about what SDD is, why it appeared, and that you should use it. I’ll introduce coding IDEs where you can simply try SDD. Fortunately, starting from 2025 and 2026, powerful tools supporting SDD are pouring out.
Cursor & .cursorrules:
The most accessible tool. If you make a .cursorrules file at the top of the project, any model references this rule whenever it runs. This file works like a kind of prefix for LLMs. I usually set up rules related to RTL Design or C++ coding and used them; example_cursorrules.txt is a rule file I actually used. At the time, I didn’t know well so I found and pasted from https://cursorrules.org/category. Strictly speaking, rather than SDD, it can be used for the purpose of unifying the overall code generation style. It’s a Spec definition in a broad sense.
Google Antigravity
An ‘Agent-First’ IDE released by Google. Here, AI doesn’t just code, but creates documents (Artifact) like Implementation Plan or Task List first and gets approval. It feels like systemizing the mentoring of a senior saying “Plan before coding”. If writing a spec document is actually difficult, it might be okay to start based on this implementation plan document.
Oh-My-OpenCode (OpenCode)
A counterattack from the open-source camp. It works in the form of a plugin like oh-my-zsh, but the interesting thing is ‘Ultrawork’ mode. Should I call it “Don’t go home until this works” mode. If an error occurs, the AI agent (Sisyphus) finds documents, debugs, and retries on its own. Especially since various models can be used, I think we can get a glimpse of an AI Agent closer to the form of “operating on its own”. It’s a bit different from how I work so I don’t use it well, but it’s receiving a lot of attention recently.
The reason all this is possible is because technologies like SGLang or Guidance force the results spat out by AI into JSON or specific formats. Thanks to this, hallucinations of AI are suppressed, and a structure where systems can talk to each other has been created. Since I covered SGLang in detail in a previous post, please refer to it if you are curious.
Conclusion: Where Should We Go?
I think SDD is a point where the identity of the developer changes rather than simply a change in development methodology. Of course, I am not a SW developer generally called a developer, but I feel something is changing or possibilities are showing in HW development (RTL Design) as well.
Now all of us who code must transform into small PMs directing smart AI workers.
The ability to organize ambiguous thoughts into clear writing will become much more important than the ability to type code fast.
The era where we have to do Literature to do Engineering is blooming.
Furthermore, since the majority of LLMs are trained more on English input, it seems almost obvious that writing documents in English will bring better results.
Some say that the foundation for the birth of a ‘1-Person Unicorn’ company has been laid. A future where one person operates planning, design, development, and deployment by delegating to dozens of AI agents. Of course, it’s a future that can absolutely not be achieved with vibe coding alone, and we must ponder how to achieve the best efficiency and the goal I want without too much paperwork in spec writing.
Recently, Jensen Huang, the CEO of Nvidia, said in many interviews that ‘use AI as much as possible’. This interview is in stark contrast to the many concerns about AI bubbles and job losses.
Personally, I also find it interesting that such an interview is interesting from the perspective of RTL developers who also code. However, I think it’s important to interpret it based on one’s own perspective, rather than just being optimistic.
When the calculator first appeared, most people who used to do manual calculations lost their jobs. However, it’s not that the concept of “calculation” itself disappeared. In the end, those people were at least one step ahead of others in terms of using calculators.
I also think that the current situation is not so different. The entry barrier for coding has become much lower. However, can a person who has never coded create a Google, Amazon, or YouTube-like mega-service? Even if we assume infinite time, in the end, there will only be a heap of spaghetti and failure. I can confidently say this. I have many more things I want to say about this, but in summary, I think the world where “people who know well do better” is already here, and we need to take advantage of the advantage we have now, which is one step ahead.
Perhaps we are passing through a period. A new protocol where humans and AI create systems together, SDD is at that starting point. What features or services are you developing right now? The moment you open a markdown file and define the content you are imagining as a spec, a new engineering will begin.
P.S.
I am continuing to worry about “what kind of engineer should I grow into?”, and I got to know SDD in that process. Personally, I think SDD will become a mainstream development methodology in the near future, and the ability to write spec documents itself can become a competitiveness. Eventually, people will ask generative AI models to even write these spec documents someday, but even then, you’ll be able to get the “best spec document” only if you can write “specs for spec documents” well. Naturally, I should be able to explain well what I am doing, but the ability to accurately convey what I want to the LLM that does not know the Context of this development will become important.
The era of writing code from a pure empty main.cpp has passed. Now is the time to ponder where to find my competitiveness, and I think the start is developing the ability to write spec documents. What do you think?
For individual growth, writing spec documents well is important, but I think “who you work with” is also very important. In this regard, I pride myself that HyperAccel is the best company in this area. Whether it becomes an LLM or a person, knowledge in various fields is required to give work instructions. We are a company that handles all of HW, SW, and AI for the launch of LLM acceleration ASIC chips, gathering outstanding talents across all fields. If you want to grow together sharing knowledge and learning broadly, even deeply, not confined to one field in this environment, please apply to HyperAccel anytime!
Recruiting Site: https://hyperaccel.career.greetinghr.com/ko/guide
Reference
- Cocktail party effect
- Zoetrope
- Why Your AI Coding Agent Keeps Making Bad Decisions(And How To Fix It)
- Spec-Driven Development: Building Better Software, Faster with Kiro
- Lost in the Middle: How Language Models Use Long Contexts
- Attention Dilution
- Reasons I Found Why AIs Struggle With Coding
- introducing-google-antigravity
- The Ultimate Guide to AI-Powered Development with Cursor: From Chaos to Clean Code
- Oh-My-OpenCode
- The Rise of the “Zero-Employee” Unicorn: The Comprehensive Guide to the Post-Labor Startup
- Extract, Edit, Apply – a design pattern for AI