
Legato: A Programming Model for the LPU
This post is written for developers at HyperAccel’s customers and partners. It explains what Legato is, what role it plays, why we built it, and how it is designed.
1. What Is Legato, and Why Do We Need It?
1.1 Software Ecosystems Decide the Outcome
What is NVIDIA’s real moat in the AI accelerator market? Many people think of raw GPU compute performance, but the hardware gap between competitors is often smaller than it appears. Transistor process, memory bandwidth, and compute-unit design are areas where several companies are catching up quickly.
What actually creates separation is the software ecosystem. Libraries, frameworks, know-how, and the confidence that “any model will run on NVIDIA eventually” — all built on top of CUDA — form a barrier to entry. No matter how good the hardware is, the market will not move if developers cannot use it freely and comfortably.
1.2 The Software Competitiveness HyperAccel’s LPU Needs
For HyperAccel’s LPU (LLM Processing Unit) to compete, it must go beyond building a fast chip and meet two conditions.
First, developers should not feel friction when using it. If adopting new hardware means throwing away an entire workflow, that hardware gets ignored. It must integrate naturally with the inference stack that is effectively the standard in today’s AI inference market — a torch and vLLM-based stack.
Second, it must support arbitrary models. An accelerator that only runs a handful of internally ported and managed models is not a true platform. It must accept whatever model users bring.
1.3 Legato’s Role
Legato is the interface that connects hardware and software developers and makes all of this possible.
Legato is both a programming language and a programming model for software developers. A programming model is the contract that defines how the LPU appears to software developers.
CUDA makes this idea concrete. We do not know every detail inside an NVIDIA chip, yet once we learn CUDA, we can program any generation of GPU. CUDA provides a simplified programming model that hides chip complexity.
Legato works the same way. It gives developers a simplified view of the LPU so they can program it without knowing low-level hardware details.
1.4 Where Legato Sits in the Stack
Legato’s role becomes clear when you see where it sits in the full inference stack.
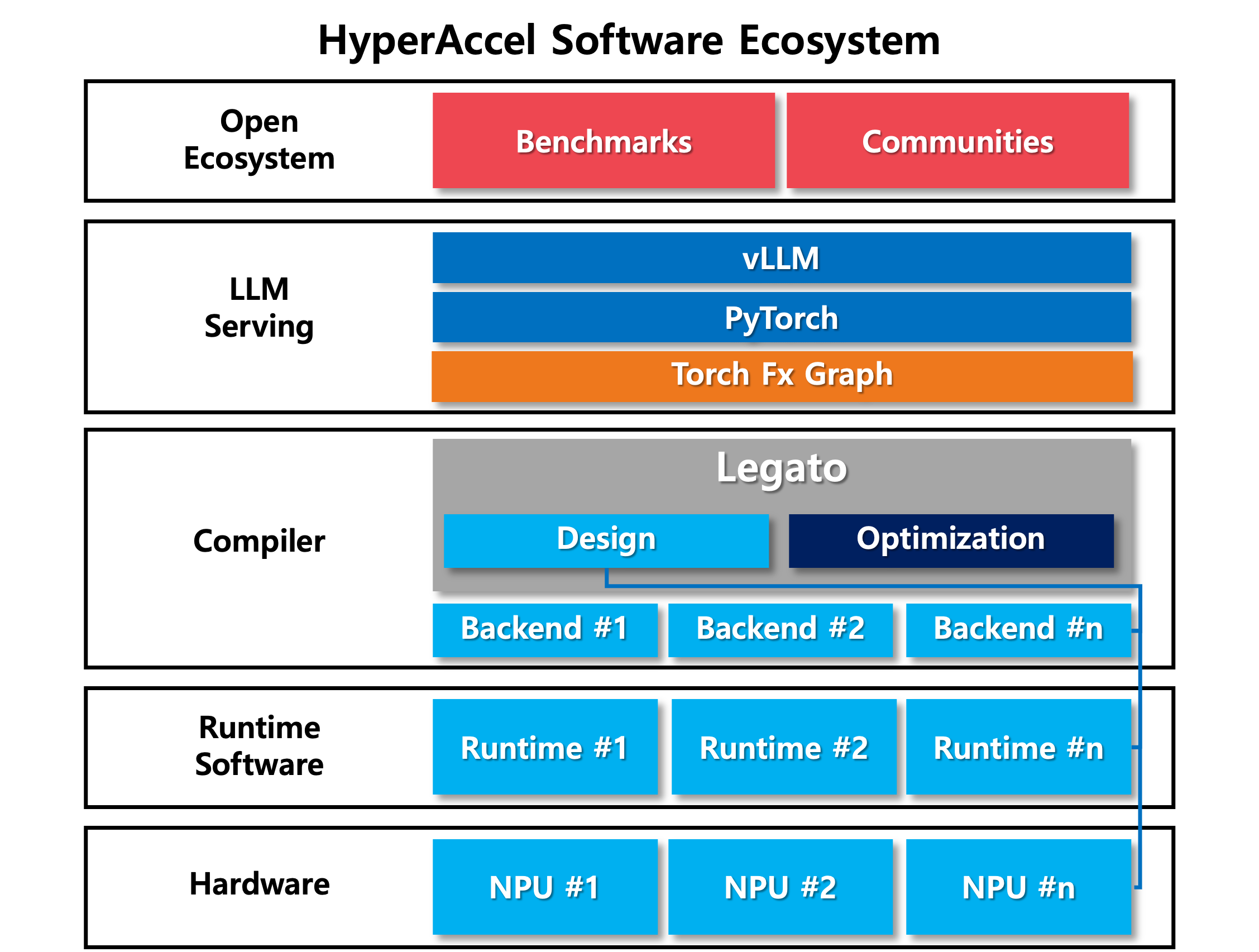
Legato connects the existing ecosystem (PyTorch/vLLM) above with LPU hardware below. Developers write code the way they always have; Legato absorbs the complexity of the hardware below.
2. Legato at a Glance (Quick Look)
Rather than add more abstract explanation, let’s look at code first. Here is a minimal example that performs matrix multiplication (matmul) on the LPU.
import torch
import legato
import legato.model.bertha as bertha
# Set the compile target.
# This example targets a Bertha chip with 128 GB of memory and 32 cores.
def get_bertha(ctx):
gigabyte = 1024**3
return bertha.Bertha(
ctx,
"bertha",
32, # num_cores
False, # use_pim
8, # num_memory_channels
128 * gigabyte, # shared_memory_size
)
# The @legato.compile decorator turns this function from a Python function
# into a Legato kernel that gets compiled. All code inside is Legato code,
# not Python (similar in spirit to Triton or Mojo).
@legato.compile(
backend=get_bertha
)
def simple_matmul(
a: legato.get_model().tensor_type(
legato.types.float("bfloat16"), ((-1, 10), 256), "shared_dram"
),
b: legato.get_model().tensor_type(
legato.types.float("bfloat16"), [256, 128], "mpu_dram"
),
out: legato.get_model().tensor_type(
legato.types.float("bfloat16"), [10, 128], "shared_dram"
)
):
# Load the device provided by the backend.
device = legato.get_context().get_device()
# Code that runs on Bertha's top module.
with device.get_top():
# Copy a and b to core 0's SRAM and mpu_buffer.
legato.tensor.request_load(a, device.get_core(0), "sram")
legato.tensor.request_load(b, device.get_core(0), "mpu_buffer")
# Code region that runs on Bertha's core 0.
with device.get_core(0):
weight_type = legato.get_model().tensor_type(
legato.types.float("bfloat16"), [256, 128], "mpu_weight"
)
# Receive data passed from the top module via request_load.
loaded_a = legato.tensor.receive(a, 0, "sram")
loaded_b = legato.tensor.receive_type(weight_type, 0, None, "mpu_buffer")
# Perform matmul with the received data.
result = loaded_a @ loaded_b
# Copy the result to the out tensor.
legato.tensor.memcpy(out, result)
output = torch.zeros(10, 128, dtype=torch.bfloat16)
# legato.session lets you specify JIT compilation options (output format, output directory, etc.).
# simple_matmul is JIT-compiled at call time; if a compiled binary already
# exists and the code has not changed, the cached binary is reused.
with legato.session(output_type=legato.OutputType.BINARY, output_path="simple_matmul"):
simple_matmul(
torch.randn(10, 256, dtype=torch.bfloat16),
torch.randn(256, 128, dtype=torch.bfloat16),
output,
)
This short snippet captures all of Legato’s core ideas:
@legato.compile— defines the entry point to compile.with device.get_top()/with device.get_core(0)— specify where each operation runs (execution context).- The kinds of contexts can vary slightly from chip to chip.
- In our example, the HyperAccel LPU consists of multiple cores, so we assigned the computation to core 0.
request_load→receive— specify when and where data moves.legato.session(...)— decide what form the compilation output takes and where it is written.- Choosing
BINARYproduces an ELF executable; you can also outputASM,CORE_IR,BACKEND_IR, and more, which are useful during debugging.
- Choosing
3. Legato’s Programming Model (Core Design Concepts)
The heart of Legato’s design is its programming model — that is, how the LPU looks to developers.
3.1 A Simplified Virtual Hardware Model
One important premise: the hardware model shown to developers is intentionally different from the physical hardware. Legato hides complex physical details and presents a simplified virtual machine that programmers can reason about.
That virtual hardware is roughly structured as follows:
- DRAM + Controller — Shared DRAM accessible by all cores. Physically it may consist of multiple memory modules, but the programming model treats them as one large memory.
- Virtual DRAM — A shared region accessed through an MMU, assumed to be preconfigured.
- PIM (Processing-in-Memory) — Used selectively when needed.
- Core — The number of cores depends on the hardware configuration. Each core has a PC and registers, multiple execution units (such as MPU and VPU executors), on-chip SRAM (cache), and private DRAM used only by that core.
3.2 Memory Model
From a software perspective, memory is simplified into three categories:
- Shared Memory — Space shared by all cores. On Bertha, this corresponds to DRAM.
- Virtual Shared Memory — Shared space managed by the MMU.
- Core Memory — Core-local space combining private DRAM and SRAM.
- Each core has SRAM space that can be used as scratchpad memory; the compiler plans how to use it.
- Private DRAM is a per-core DRAM region used for eviction when on-core scratchpad memory is insufficient.
An important design choice appears here. When a programmer allocates data in Core Memory, whether it lands in SRAM or private DRAM is decided by the compiler’s planning phase. Developers work with the abstract notion of “this core’s memory,” and the compiler handles physical placement optimization.
3.3 Execution Context (Executor) and Explicit Data Movement
Legato operations always run inside an execution context that indicates where the next operation executes.
device = legato.get_context().get_device()
with device.get_top():
legato.tensor.request_load(input_data, device.get_core(0), "sram")
with device.get_core(0):
loaded = legato.tensor.receive(input_data, 0, "sram")
result = loaded + loaded
device.get_top()— used for orchestration and top-side load requests.device.get_core(i)— run on a specific core.device.get_all_cores()— run the enclosed region on all cores.
The LPU has the characteristic that each module runs its own program counter (PC) independently. Legato represents this naturally by separating execution contexts through ContextOp.
Data movement is explicit, not implicit. You request a load from a source context with request_load, then receive data in the target context with receive (or receive_type). When and where data moves is visible in the code.
Legato scopes are stricter than Python scopes. If a value created in one region must be used in the next, you must pass it explicitly with yield:
with device.get_core(0):
q = loaded @ weight
yield q
with device.get_core(0):
legato.tensor.memcpy(output, q)
3.4 Forward Compatibility
The biggest payoff of this simplified programming model is forward compatibility.
As long as future LPUs preserve compatibility with this programming model, a program written once can run on the next hardware generation without code changes — the same promise CUDA makes when code written for one GPU generation runs on the next. The stability of the programming model is what makes “hardware evolves, code stays” credible.
4. Legato’s Design Philosophy
4.1 Python-Embedded DSL
Legato is designed as a Domain Specific Language (DSL) embedded in Python. That is intentional. With a single pip install, developers can use it in a familiar Python environment without a separate toolchain, keeping the barrier to entry as low as possible. They start programming the LPU inside syntax they already know: with blocks, functions, and decorators.
4.2 Python-Friendly Tensor Abstraction
Legato operations are built around tensors that many programmers already know. It provides operations similar to PyTorch or NumPy — broadcast, reshape, matmul, and so on.
Beyond that, it also supports advanced programming features such as synchronization and metaprogramming (static evaluation) to make performance tuning easier.
The semantics of each library operation are designed generically so they can be used without code changes even as LPU generations evolve. In other words, the API stays stable while the compiler lowers operations to the best implementation for each generation underneath.
4.3 Explicit Control vs. Automation Trade-off
Legato is a relatively low-level interface where developers explicitly describe execution placement, data movement, and compile-time parameters. That can look verbose, but it is deliberate. For kernels where performance is the value — where you must express data flow clearly — that explicitness is control.
At the same time, Legato also provides automation paths, so users can choose depending on the situation:
- Fully automatic — hand the entire model to the
torch.compilebackend. - Fully manual — write critical kernels directly and tune them in detail.
4.4 Extensibility
Using Legato from PyTorch
Legato implements PyTorch backend operations so the LPU works with torch, similar to how Triton implements GPU operations to support PyTorch. The flow is:
- Implement a Legato function for each PyTorch operation you want to support.
- When one operation has multiple implementations (for example, float32 vs. bfloat16), a resolver function picks the right one and hands it to the compiler.
- Import the implemented module or expose it through a
legato-libraryentry point.
import torch
@torch.compile(backend="legato", options={"legato.device": "bertha"})
def model(x, y):
...
Partial compilation (mixed execution). Not every operation can go to the LPU. Legato wraps the full graph in LegatoGraphWrapper, groups compilable nodes into Legato kernels, and runs unsupported nodes as eager extern calls. If a resolver is missing or a dtype/shape combination raises AssertionError, that node becomes an extern fallback candidate. Models that mix custom or unsupported ATen ops therefore do not fail immediately; compilable regions still accelerate.
Platform-agnostic extension. Legato is not limited to PyTorch. It can extend to NumPy, CuPy, and other platforms. As long as the backend is implemented with Legato, there is no fundamental limit to extensibility.
5. Legato’s Internal Structure
5.1 Compilation Pipeline
A Legato program goes through the following stages to become a hardware artifact:
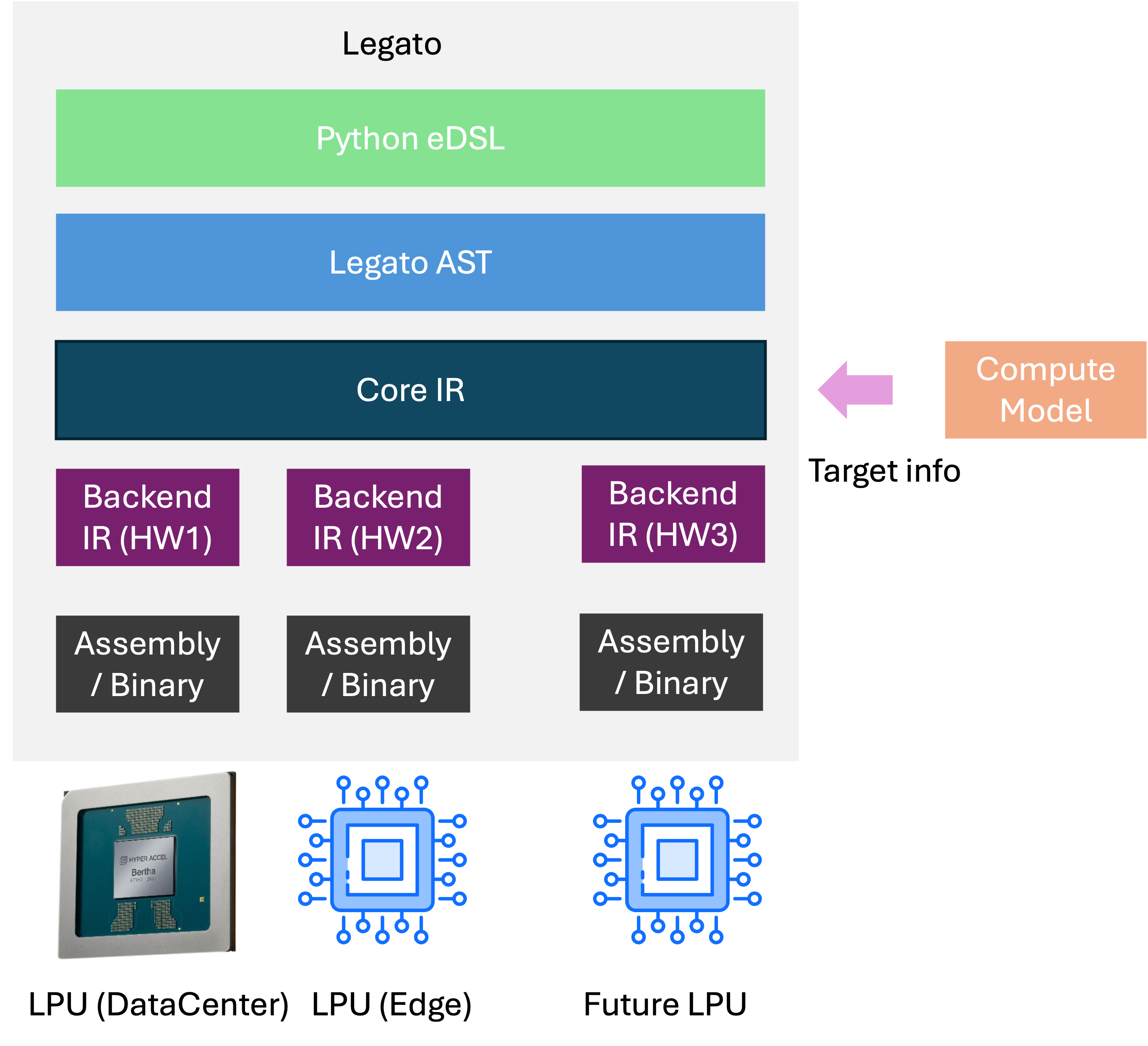
- Frontend — defines the user-facing surface. It takes Legato code written in Python and lowers it to MLIR-based Legato IR.
- Core IR / Backend IR — successive lowering passes move the representation closer to hardware.
- Artifact — the final output is assembly or a binary.
5.2 ComputeModel — Injecting Hardware Information
A ComputeModel is attached throughout the pipeline to supply hardware information to the compiler.
A ComputeModel is a simplified model of the hardware and plays a central role in lowering and optimization decisions. Swapping the ComputeModel is enough to retarget the compiler. As in the get_bertha example, a backend factory creates a ComputeModel instance and passes it to the compiler.
Beyond supplying information, the ComputeModel is the basis for validation. If a user writes an operation that cannot run efficiently (or at all) on a given device, the compiler tries feasible transforms or, when that fails, returns a clear error message to guide the user.
5.3 Per-Hardware Backends
Each hardware target has its own compiler backend that performs hardware-specific lowering. To support a new LPU, implement a backend and ComputeModel for that hardware; the upper-level programming model and user code stay reusable.
5.4 Output Targets — Transparency and Debugging
Legato lets you dump artifacts at any compilation stage. Choose one of the following with legato.session’s output_type:
| Output Type | Description |
|---|---|
MLIR | Initial Legato IR (MLIR form) |
CORE_IR | Core IR stage |
BACKEND_IR | Backend IR stage |
ASM | Assembly |
BINARY | Final executable binary |
with legato.session(output_type=legato.OutputType.MLIR, output_path="test-output"):
kernel(*args)
Being able to inspect IR at each stage means compilation is not a black box. When something goes wrong, you can trace how the program was transformed at each step, which makes debugging and verification transparent.
5.5 ELF Binary
The final output is an ELF binary. It is not just a blob of instructions; it also carries metadata such as hardware information, compiler information, and checksums. At runtime, the runtime reads this metadata to verify that the binary is suitable for the current hardware and environment, preventing accidental execution of the wrong binary on the wrong device.
6. Robustness and Verification (Trust Signals)
For anyone adopting a platform, the key question is: “Can I trust this in production?” Legato answers with verification at several layers.
6.1 ComputeModel-Based Validation
As described earlier, when a user writes an operation that is impossible or inefficient on a target device, the compiler attempts automatic transformation and, if that fails, returns an actionable error message explaining what went wrong and why. Problems surface at compile time instead of silently producing wrong results.
6.2 Type, Layout, and Dynamic Shape Validation
Legato validates tensor types and memory layouts in function signatures. In particular, dynamic dimensions must have an upper bound:
x = torch.zeros(16, 32, 32)
torch._dynamo.mark_dynamic(x, 0, max=128) # dim 0 is dynamic, upper bound 128
Because of hardware characteristics, tensors cannot be fully dynamic. Every dynamic dimension needs an upper bound for buffer allocation and command generation; dimensions without an upper bound raise an error at compile time. This is so the compiler can plan tensor allocation at compile time.
6.3 Host-Device ABI (Instruction Table)
To pass arguments correctly across the host–device boundary, Legato defines a binary ABI called the Instruction Table. It strictly follows 64-bit alignment rules and packs scalar, tensor, and tuple arguments according to a fixed convention. The maximum table size can be computed at compile time from the function signature, so runtime argument passing is predictable and safe.
Q. Do I Need to Learn All of Legato to Use the LPU?
No. Of course you do not. Not every AI developer who uses a GPU knows CUDA, OpenCL, or Vulkan in depth. HyperAccel’s LPU works the same way.
Legato implements backends for torch and other libraries; it is not something every AI developer interacts with directly. When you use torch or numpy on the LPU, you can work the way you do on CPU or GPU today, while the underlying operations are implemented with Legato.
If you want custom kernels or extreme performance tuning, you can use Legato directly. On GPUs, developers sometimes write custom kernels in Triton or CUDA instead of relying only on what torch already provides when they want to push performance or implement operations that do not exist yet. The LPU is no different. Legato is always available for direct use, and you can insert Legato-implemented layers into an otherwise torch-based model, as below:
@legato.compile(backend=bertha)
def custom_kernel(input: legato.get_model().tensor_type(
legato.types.float("bfloat16"), ((-1, 10), 256), "shared_dram"
),
output: legato.get_model().tensor_type(
legato.types.float("bfloat16"), [256, 128], "shared_dram"
)):
# Some implementation...
c = torch.add(a, b)
out = torch.zeros(256, 128)
# Call legato kernel
custom_kernel(c, out)
print(f"output from legato kernel : {out}")
# Keep going with torch
out_exp = torch.exp(out)
7. Summary and Next Steps
7.1 Summary
Legato provides a simplified programming model for the LPU and achieves three goals at once:
- Ecosystem compatibility — it integrates naturally with existing stacks such as
torchandvLLM. - Forward compatibility — as long as the programming model is preserved, code runs on future LPUs without changes.
- Extensibility — new hardware and platforms require only a backend and ComputeModel.
Just as CUDA underpins NVIDIA’s ecosystem, Legato is the foundation of HyperAccel’s LPU ecosystem.
7.2 Supported Targets and Roadmap
Legato currently targets the Bertha architecture (with per-generation guides such as EVT0 and EVT1). Because retargeting is built around swapping the ComputeModel, extension to future LPU generations is prepared at the design level.
P.S.: HyperAccel is Hiring!
We are looking for teammates to help build Legato and the LPU software stack. If you are interested in the technologies we work on, please apply via HyperAccel Career.