
PyTorch Conference 2025 Report
Introduction
Hello, I’m Minho Park, Lead of the ML Team at HyperAccel. I attended the PyTorch Conference 2025 held in San Francisco on October 22-23, and I’d like to share my observations and insights.
About HyperAccel

HyperAccel is a company that designs AI chips for efficient inference of Large Language Models (LLMs). We have completed IP verification with FPGA, and our ASIC chip and server are scheduled for release next year. For ASIC, we plan to provide an SDK that supports PyTorch for inference, along with vLLM and Kubernetes support.
Motivation for Attendance
The main objectives of attending this conference were:
Gaining Insights for Torch Hardware Backend Implementation: We wanted to understand PyTorch’s hardware backend implementation methods and latest trends to gain technical insights for developing an optimized backend for our chip.
PyTorch Foundation Membership Consideration: HyperAccel is considering joining the Foundation membership to contribute to the PyTorch ecosystem and collaborate with the community. At PyTorch Conference 2025, we met with Meredith Roach, Membership Solutions at Linux Foundation, to discuss PyTorch membership.
Learning from Other Hardware Vendors: We wanted to gather information on how other hardware vendors such as Google TPU, AMD, Rebellions, and Furiosa AI approach and integrate with PyTorch, vLLM, SGLang, etc.
Key Highlights of PyTorch Conference 2025
Scalable
Scalability solutions for large-scale model training and inference received significant attention. Previously, third-party software was often required for large-scale distributed training/inference (Megatron, DeepSpeed, Horovod, …). However, at this PyTorch Conference, PyTorch Organization introduced its own distributed training frameworks, communication libraries, and abstraction concepts.
Monarch
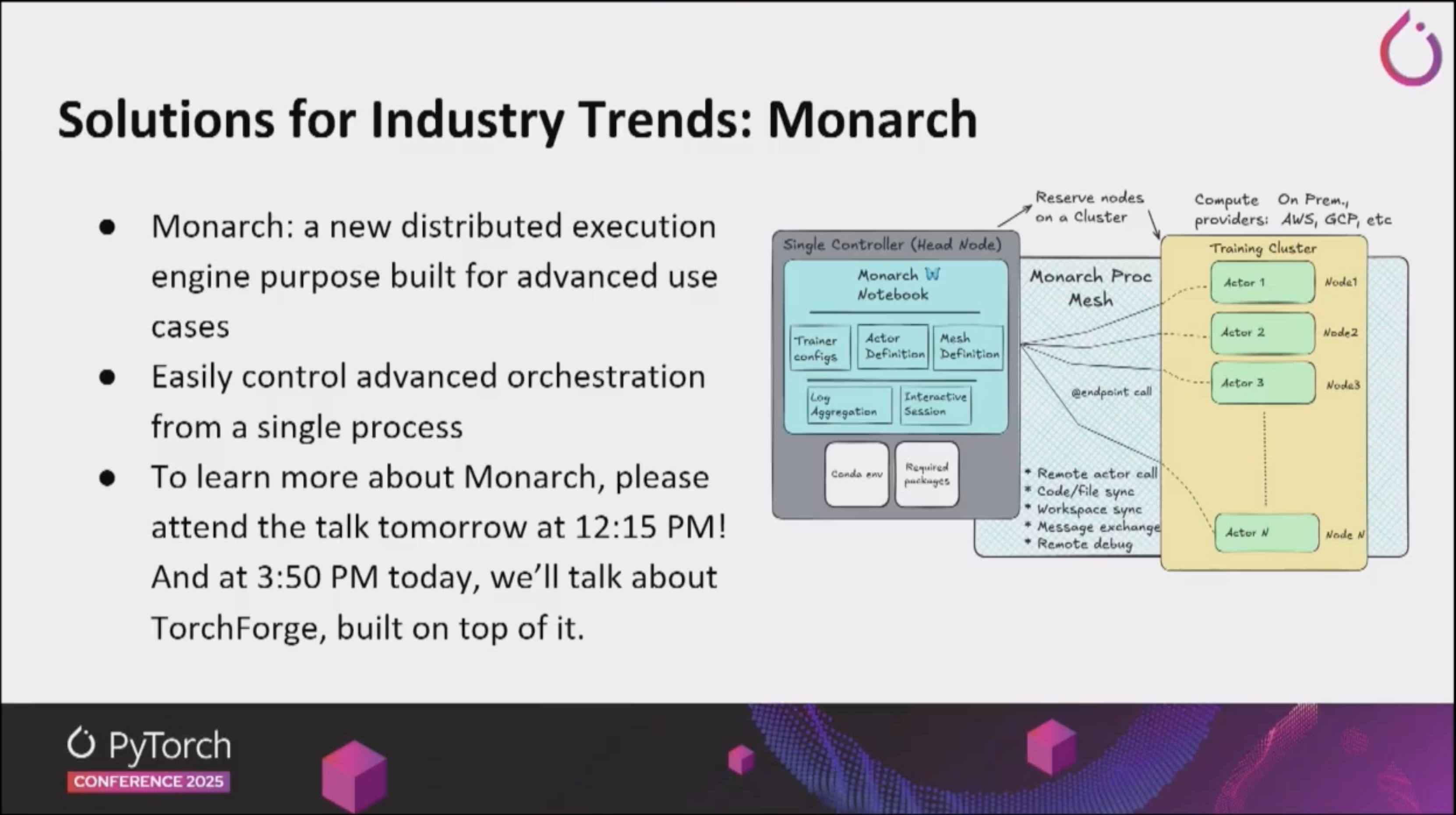
- Monarch is a Distributed Programming Framework for PyTorch, designed to support efficient distributed training and inference of large-scale models.
- Looking at the API, it appears to be heavily influenced by Ray’s Actor and Task concepts.
- It provides automated partitioning and communication optimization without the need to manually configure complex parallelization strategies.
- This significantly reduces code complexity and communication overhead compared to existing distributed training frameworks.
- DTensor: Simplifies model parallelization across multiple devices. It’s an abstraction layer that enables efficient execution of large-scale models without complex distributed setup.
TorchComms

- A new API to support PyTorch’s next-generation distributed communication.
- The existing PyTorch Distributed’s
c10d::Backendhas significant technical debt, making modernization and extension difficult, which created challenges for adding new hardware. - By separating the communication layer from PyTorch core, new collective communication or backends can be implemented more quickly and independently.
- The ease of implementing new backends is extremely important for us at HyperAccel. For LLM Inference, implementing Tensor Parallelism is essential to reduce latency, and at this point, implementing a communication backend for our chip is necessary. We believe this can be implemented independently through TorchComms.
Ray
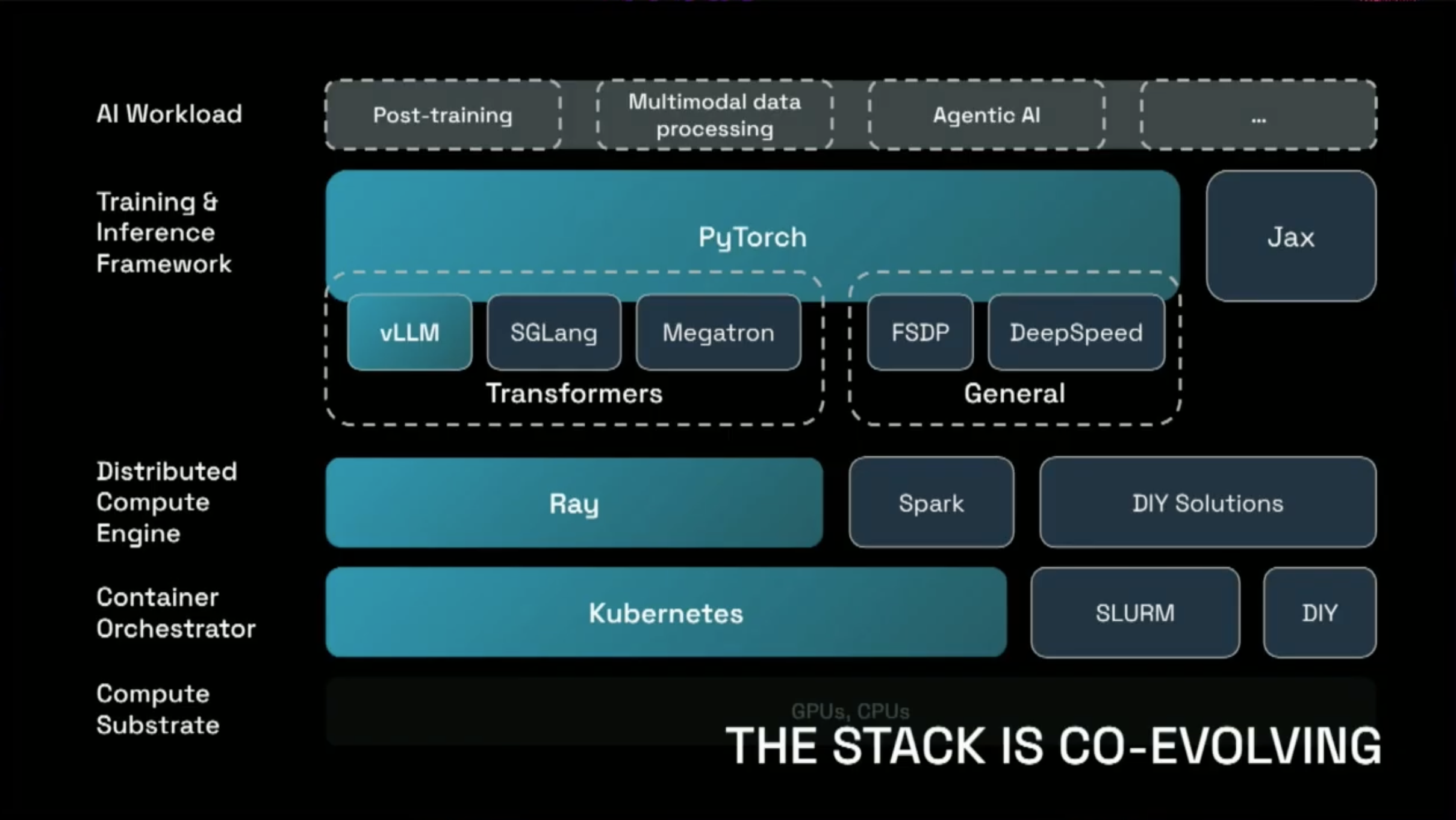
- A computing framework for distributed Python processing that enables easy scaling of large-scale ML workloads through integration with PyTorch.
- Python functions are treated as Tasks and classes as Actors, which can be executed anywhere within a Ray Cluster.
- Ray operates as a Distributed Compute Engine on top of Kubernetes, a Container Orchestrator, and helps efficiently distribute workloads provided by PyTorch-based training & inference frameworks such as vLLM, SGLang, and Megatron.
Even faster for advanced users
Performance optimization tools for advanced users were introduced.
Helion

- PyTorch’s eDSL (Embedded Domain-Specific Language) that maximizes runtime performance through compile-time optimization. It enables more efficient execution of complex computation graphs.
- To run Transformers quickly, various companies use an enormous amount of Custom Kernels, but supporting Custom Kernels on new hardware is difficult, which can quickly become technical debt.
- It’s a Higher Level DSL that automates manual tasks when writing Triton kernels.
- The actual result of Helion DSL becomes a Triton Kernel, and by adding a Triton Kernel Backend, various hardware support becomes possible.
- It appears to be an essential Abstraction Layer that can support various hardware agnostically.
- From a PyTorch user’s perspective, it could be a means to write more efficient kernels.
CuTile

- As GPU Architecture evolves, various features have been added (e.g., TMA in Hopper, TensorCore from Turing Architecture).
- When implementing through GPU Kernel PTX, there’s a problem where existing kernels have difficulty supporting new hardware specs when they are added.
- Additionally, PTX-level implementation requires users to manually divide work into blocks, divide data into tiles, and even map to threads directly. Such abstraction leads to extensive code writing.
- In the case of Tile IR, the system performs the work of mapping work to threads on behalf of the user.
- This Tile Level abstraction was introduced in Triton-lang, and Helion mentioned above also supports DSL through Tile Level abstraction.
- By supporting Tile Level DSL and IR in CUDA as well, an appropriate abstraction layer has been established between the User and System.
Runs Everywhere
Projects were announced to enable PyTorch to run on various platforms and devices.
PrivateUse1 and torch.accelerator
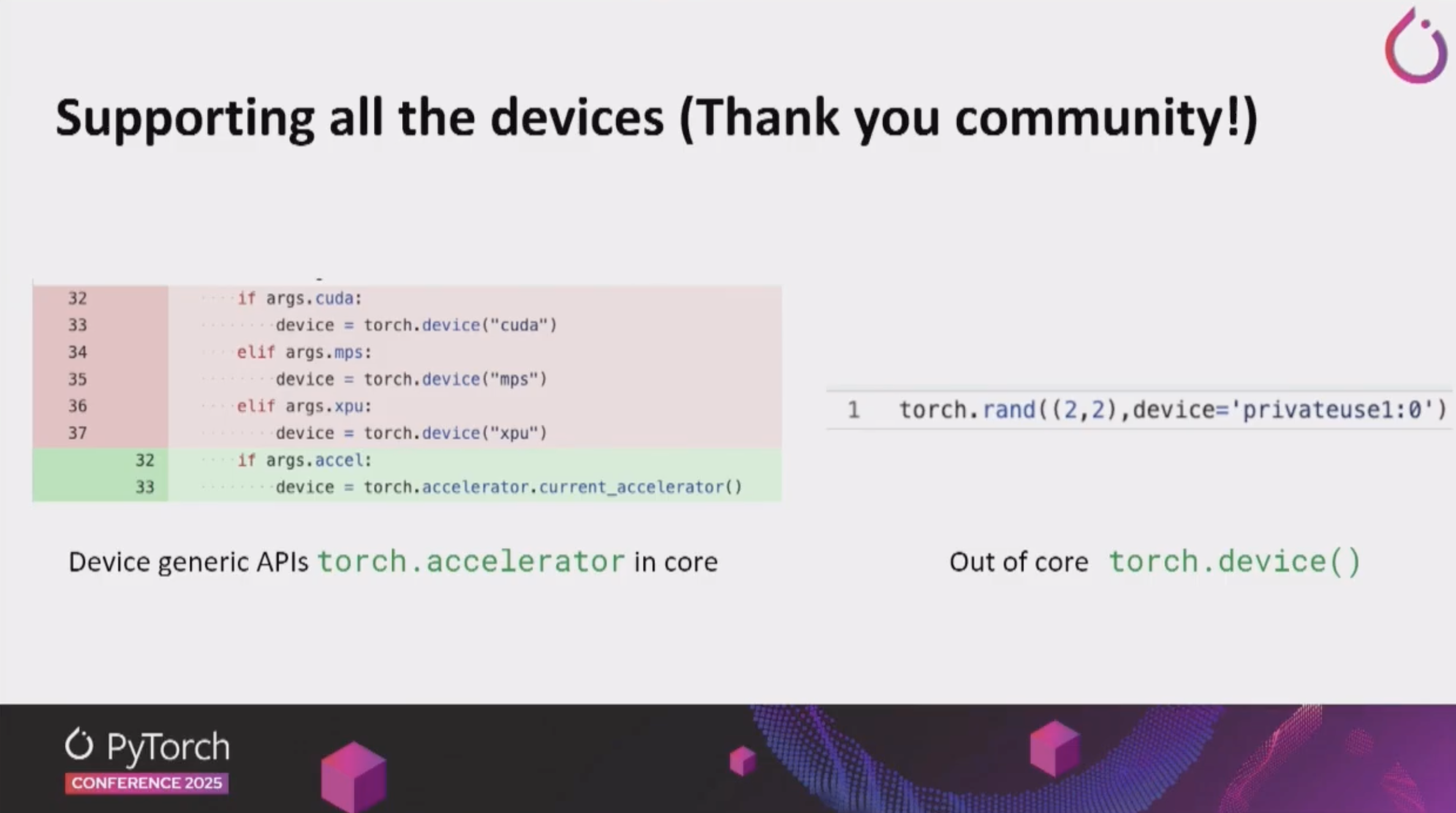
- torch.accelerator
- A unified accelerator abstraction API that enables using various hardware backends through a consistent interface.
- Previously,
torch.cuda.*was frequently used in PyTorch code under the assumption that only NVIDIA GPU would be used. However, such code reduces hardware portability. - Now, PyTorch supports
torch.accelerator, a Device generic API, enabling hardware agnostic code writing.
- PrivateUse1
- An extensible interface for custom hardware backends. It’s an important feature that enables AI chip vendors like us to port PyTorch to their hardware.
- PyTorch support is possible through an Out-Of-Tree plugin format without needing our backend to be included in the PyTorch main branch. (PyTorch support method of Rebellions, Huawei Ascend)
Executorch:
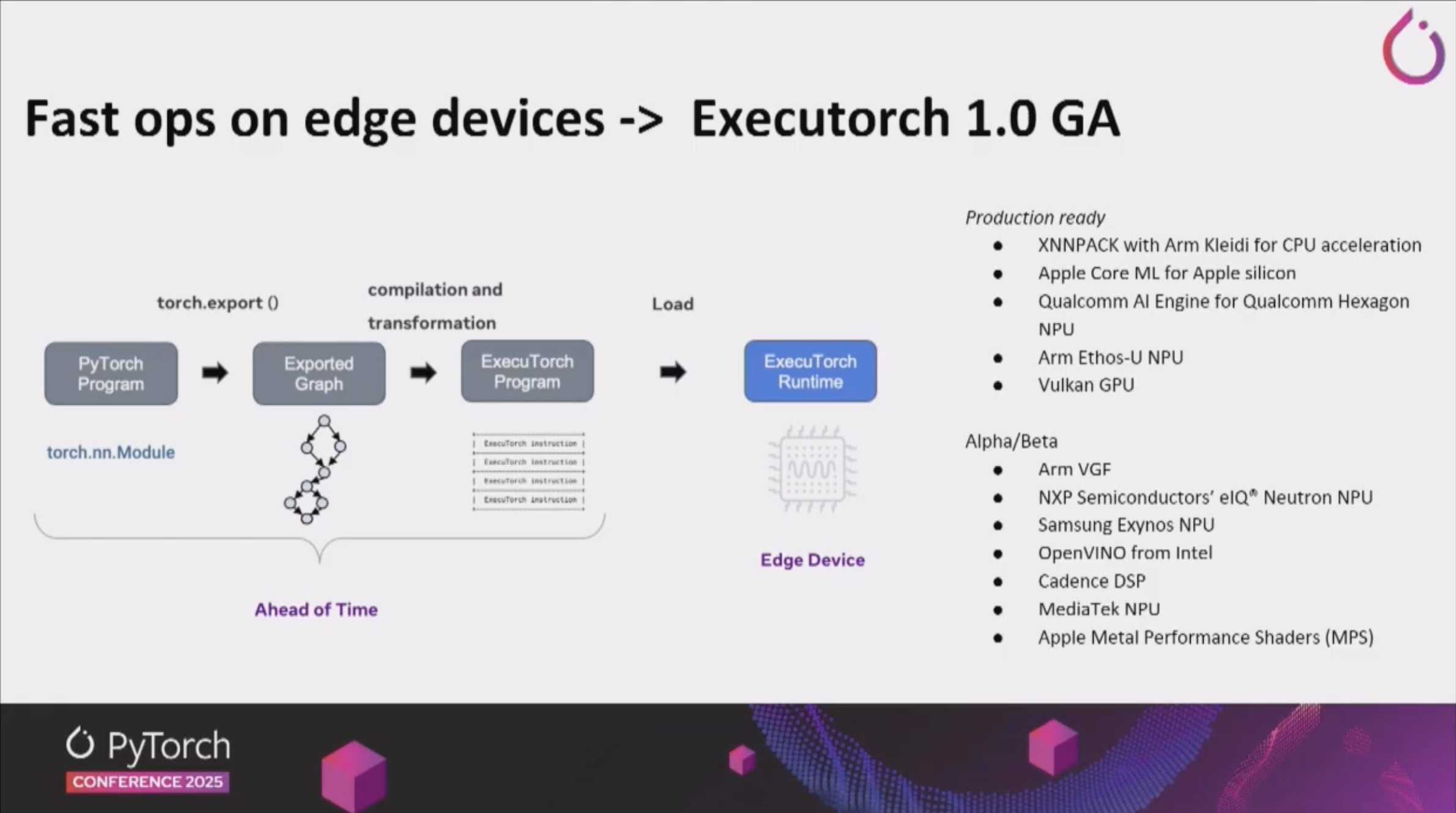
- A lightweight PyTorch runtime for edge devices that enables efficient execution of PyTorch models on mobile and IoT devices.
LLM Inference Engine
There were many sessions on LLM inference engines, and real-world industry application cases were shared.
vLLM:

- vLLM is becoming increasingly integrated with PyTorch, and vLLM plays a significant role in improving PyTorch’s features, while vLLM is being further accelerated by PyTorch’s new features.
- vLLM serves as a Hub that can support new models and hardware as an LLM Inference Framework.
- At PyTorch Conference 2025, it was one of the most important projects, with 7 related presentations in the keynote and standalone sessions.
- At HyperAccel, supporting vLLM’s features to the maximum extent is the Software Group’s biggest goal.
SGLang

- SGLang is also an LLM Inference Framework widely used in the industry, similar to vLLM.
- It’s a framework being actively adopted by xAI Grok, AMD, TogetherAI, etc.
- Plugin functionality to attach non-GPU hardware as a backend was not yet supported, but at this Conference, plans were shared to support various hardware through multi-platform abstraction refactoring.
Industry Application Cases

- Spotify presented a case study of applying LLM to a large-scale music recommendation system by combining vLLM with Google TPU. Performance optimization and operational experiences in actual production environments were shared, which was very useful.
- In Prefill Heavy situations, TPU was significantly better than L4, A100 in terms of Performance and Cost Efficiency.
System Level LLM Inference
There were presentations on LLM inference optimization at the system level.
llm-d
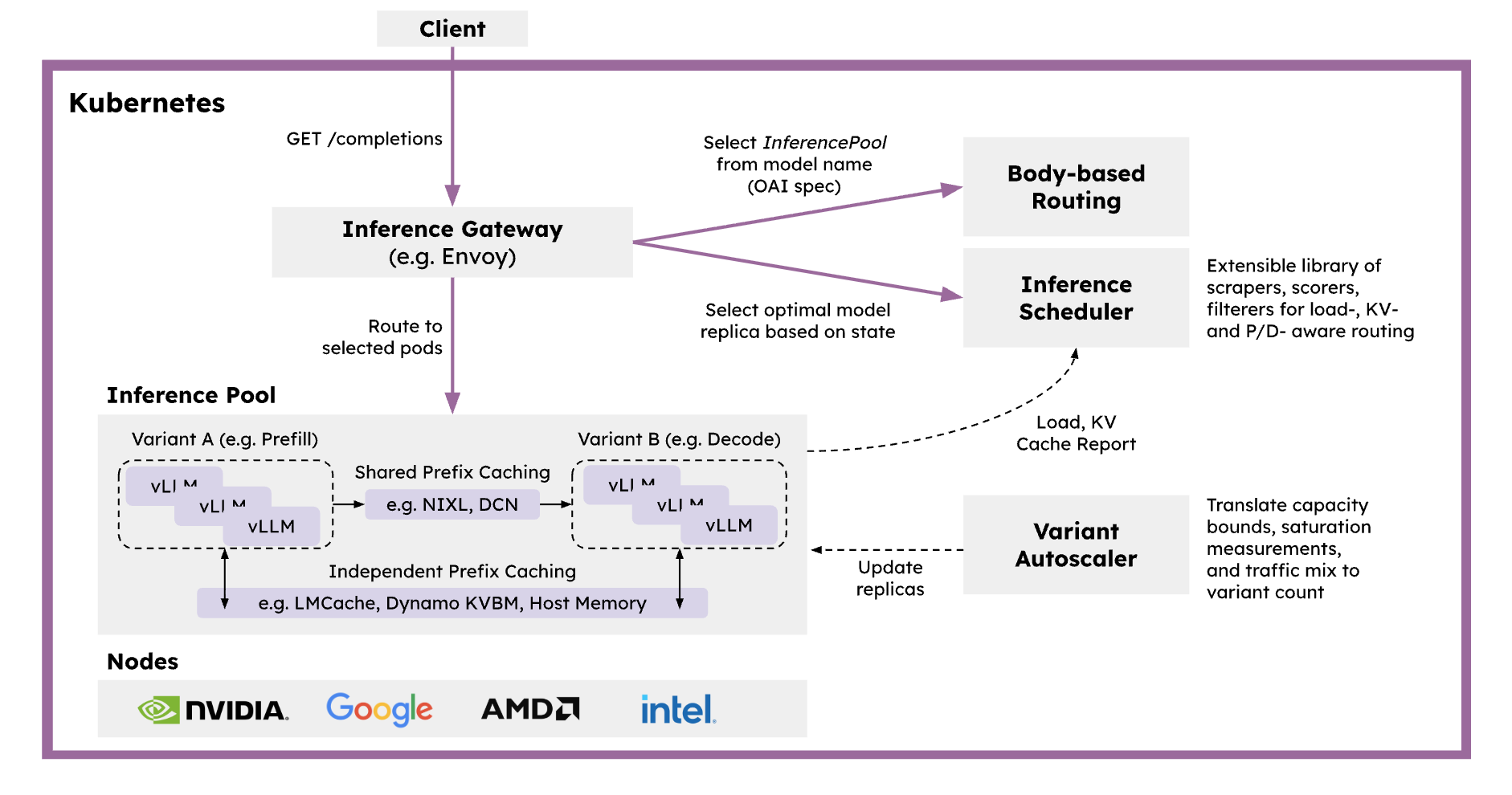
- llm-d is a Kubernetes-native distributed inference serving stack that provides a Production Ready solution for efficiently serving large-scale generative AI models.
- It’s configured by integrating vLLM as the base model server, Inference Gateway as a request scheduler and balancer, and Kubernetes as an infrastructure orchestrator.
- Key features:
- Intelligent Inference Scheduler: Provides P/D separation, KV cache, SLA, and load-aware routing through smart load balancing based on Envoy proxy.
- Disaggregated Serving: Separates Prefill and Decode stages into independent instances to optimize GPU utilization and improve TTFT (Time To First Token) and TPOT (Time Per Output Token).
- Disaggregated Prefix Caching: Provides a Pluggable KV Cache layer that off-loads KV cache to host memory, remote storage, LMCache, etc.
- Variant Autoscaling: An autoscaler that recognizes traffic and hardware, calculating optimal instance combinations for Prefill, Decode, and latency-tolerant requests.
- Supports various hardware accelerators (NVIDIA GPU, AMD GPU, Google TPU, Intel XPU) and provides production-validated Helm charts and guides.
Dynamo
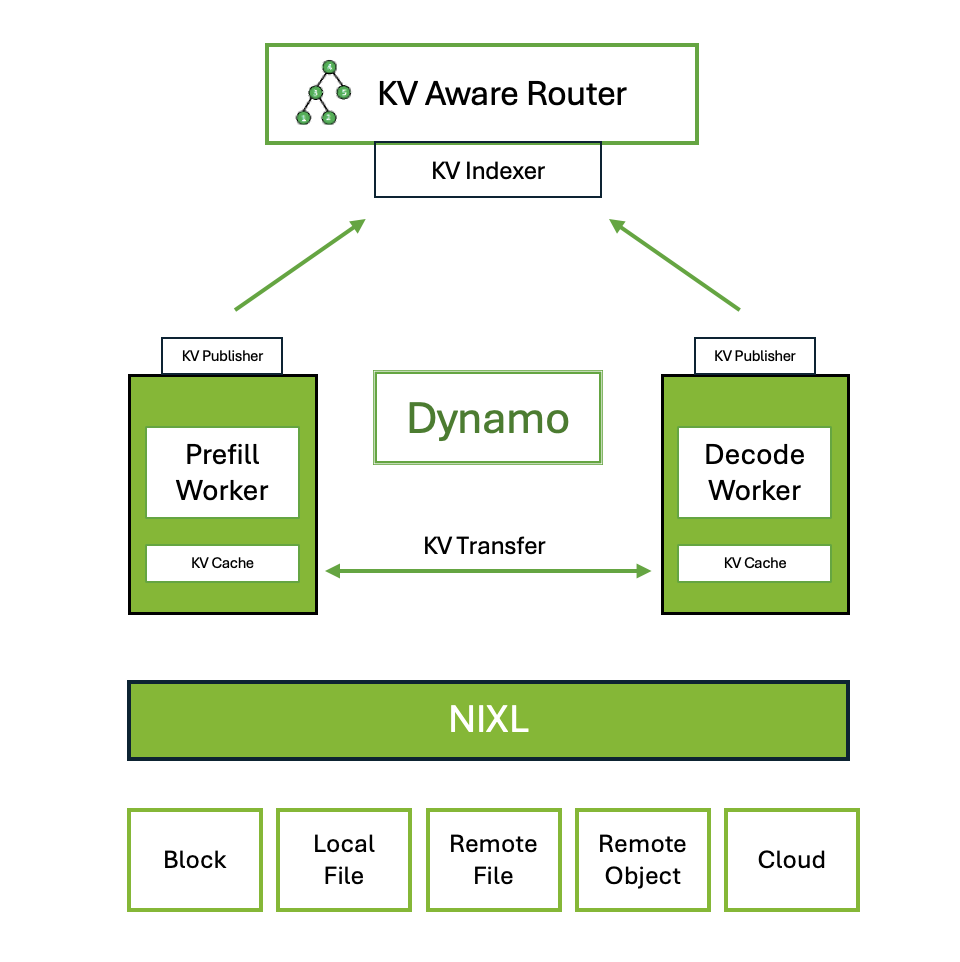
- Dynamo is NVIDIA’s high-throughput, low-latency inference framework, designed to serve generative AI and inference models in multi-node distributed environments.
- It’s inference engine agnostic, supporting TRT-LLM, vLLM, SGLang, etc., and is implemented in Rust and Python, considering both performance and scalability.
- Key features:
- Disaggregated Prefill & Decode Inference: Separates Prefill and Decode to maximize GPU throughput and balance throughput and latency.
- Dynamic GPU Scheduling: Provides performance optimization based on real-time demand.
- LLM-aware Request Routing: Routes requests to workers with the highest KV cache hit rate, eliminating unnecessary KV cache recomputation.
- Accelerated Data Transfer: Reduces inference response time using NIXL (NVIDIA Inference Transfer Library).
- KV Cache Offloading: Utilizes multiple memory tiers such as HBM, DDR, NVMe, or remote storage to increase system throughput and reduce latency.
Post-Conference Reflections
Technical Insights
The most impressive part of this conference was the PrivateUse1 and torch.accelerator APIs. These extensible interfaces are essential for porting PyTorch to the AI chip we’re developing. It was particularly useful to understand the details of implementing custom hardware backends through PrivateUse1.
I gained a lot of inspiration especially from the vLLM sessions. I was able to see how closely vLLM is integrated with the PyTorch ecosystem and how it serves as a Hub for supporting new hardware. This made me realize that it’s important not just to implement a PyTorch backend, but to systematically structure the entire software stack. The key challenge is to properly structure the overall SW stack, considering not only integration with high-level inference engines (vLLM, SGLang, etc.) but also system-level optimization, so that users can easily use our chip.
Community Engagement
Through meetings with PyTorch Foundation officials, we were able to discuss membership procedures and contribution methods. We are positively considering joining the PyTorch Foundation to participate in the Torch ecosystem together. I was also able to see the technical capabilities of other hardware vendors such as AMD, Rebellions, and Furiosa AI and gained a lot of inspiration.
Future Plans
Based on the insights gained from the conference, we plan to proceed with the following tasks:
- PrivateUse1 Backend Implementation: Implement a PyTorch backend for our chip through the PrivateUse1 interface
- Complete SW Stack Configuration: Systematic software stack configuration including vLLM/SGLang integration
- PyTorch Foundation Membership Review: Review official membership to participate in the Torch ecosystem
- Open Source Contribution: Share our hardware backend implementation experience with the community
Postscript
HyperAccel Recruitment
HyperAccel is developing next-generation AI chips for LLM inference. We have completed FPGA verification and will soon release ASIC chips and server solutions. We are creating solutions that developers can easily use through integration with the PyTorch ecosystem.
Career Site: https://hyperaccel.career.greetinghr.com/en/guide
If you’re interested, please feel free to contact us!