
NAVER DAN 2025 Report
Introduction
Hello! I’m Sinhyun Park from the HyperAccel ML team. I’d like to share my thoughts after attending NAVER DAN 2025, held at COEX on November 6-7, 2025.
Motivation for Attending
The main objectives for attending this conference were:
Gaining insights on scalable storage infrastructure: Beyond sharing data between nodes within a computing cluster, I wanted to acquire technical insights for building storage infrastructure that enables data exchange across different clusters.
Learning efficient AI cluster resource utilization: At HyperAccel, we operate AI clusters composed of GPUs and FPGAs for AI workloads. To efficiently utilize resources within these AI clusters, I wanted to learn how other companies manage their AI clusters.
NAVER DAN 2025 Key Highlights
IDC Seamless HDFS
I’d like to share the contents of the IDC Seamless HDFS session, which I attended to gain insights on distributed storage infrastructure. This session covered the limitations NAVER’s search platform faced while handling massive data and traffic in a multi-IDC environment, and the distributed storage technology they built to overcome these challenges.
Problem: Data Silos and Data Recovery
NAVER operates large-scale Hadoop clusters (C3) across multiple IDCs including Pyeongchon, Pangyo, and Sejong. Due to the physical distance between IDCs, they encountered the following limitations:
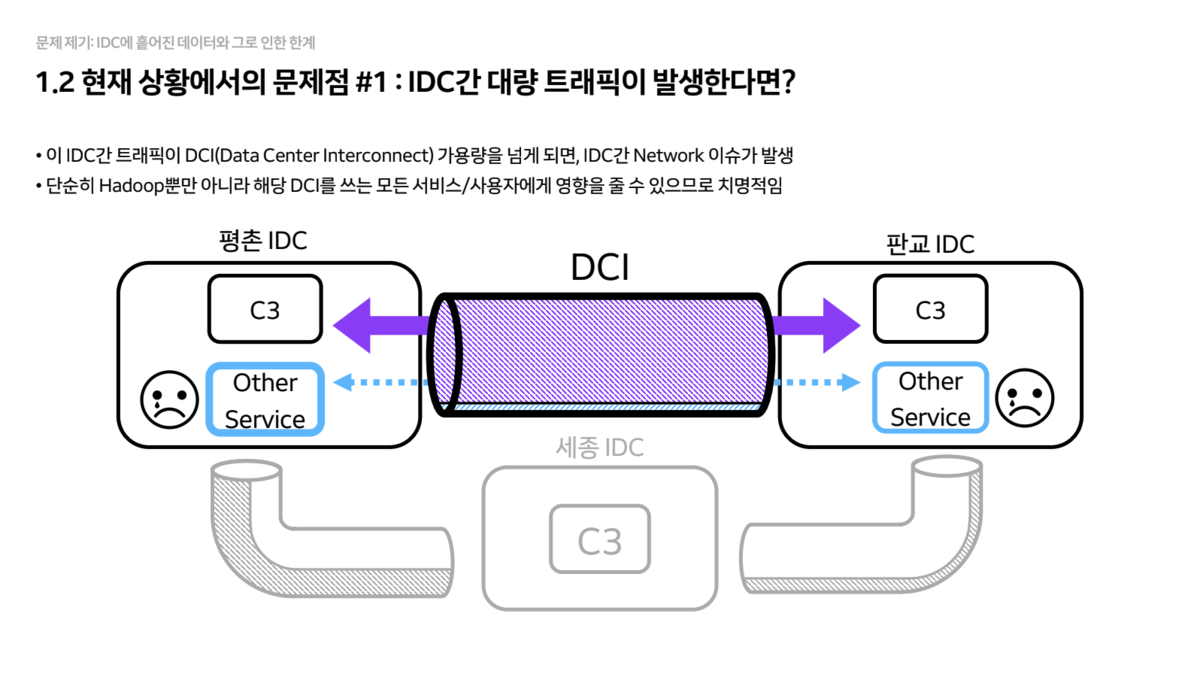
- Data Silo
- Since clusters are configured independently for each IDC, accessing data in other IDCs requires going through the
Data Center Interconnect (DCI). - If the traffic exceeds the DCI bandwidth, it can cause outages for all other services using that connection, making it extremely risky.
- Since clusters are configured independently for each IDC, accessing data in other IDCs requires going through the
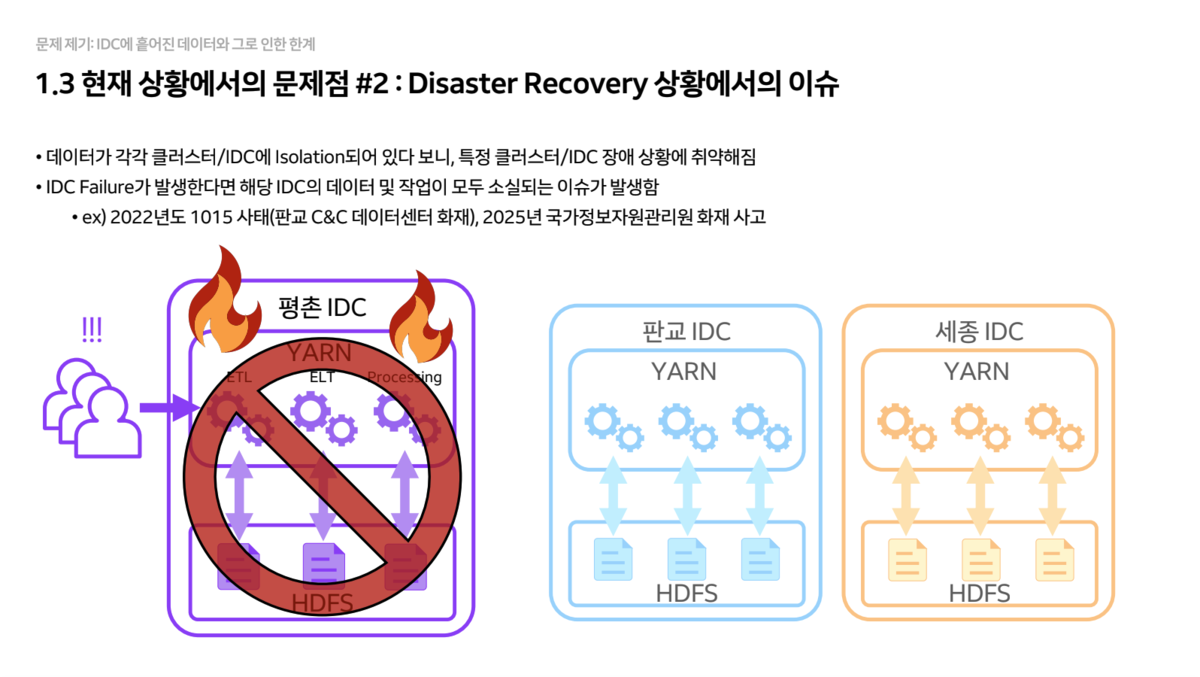
- Data Recovery
- Since data is stored in isolation at specific IDCs, there’s a risk of permanent data loss if that IDC is completely destroyed by events like fires.
Solution: IDC Seamless HDFS
NAVER introduced a new architecture called IDC Seamless HDFS to solve these problems.

- Logical Single Namespace
DataNodeslocated in different IDCs were logically unified into a single HDFS Namespace.- From the user’s perspective, they can use it conveniently like local storage without worrying about which IDC the data is in.
- Even if one IDC experiences an outage, services and data access continue uninterrupted through other IDCs.
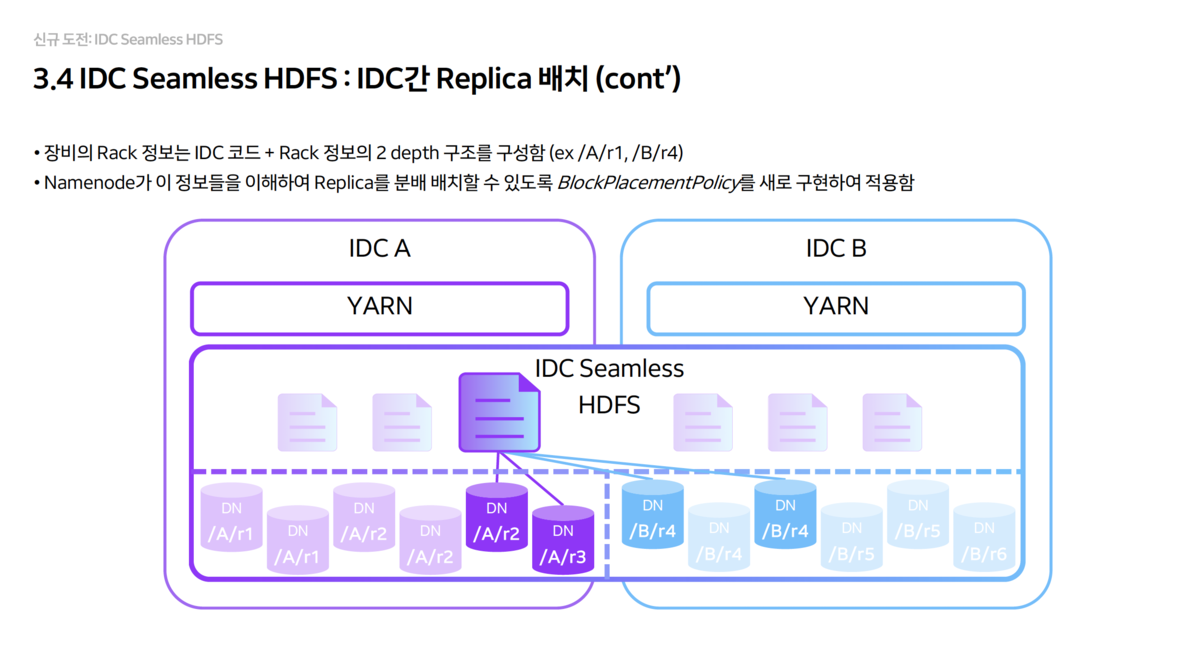
- Replica Placement Strategy (2+2 Structure)
- They set the default replica count to 4 and developed a new
BlockPlacementPolicyto enforce placing 2 replicas in each IDC. - Rack information was structured in 2 depths as
IDC Code + Rackformat so that theNameNodecan recognize physical locations.
- They set the default replica count to 4 and developed a new
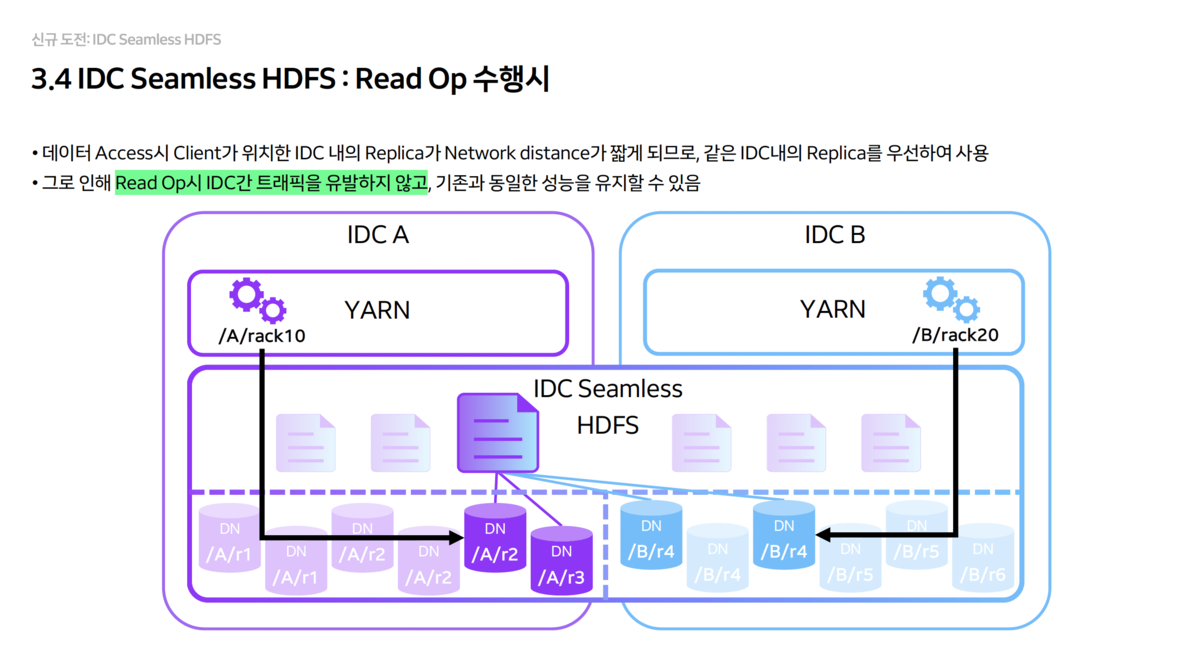
- Read Operation Optimization
- When clients read data, they are guided to preferentially read from replicas (one of the 2) within their own IDC.
- This ensures zero inter-IDC traffic during read operations, with no performance degradation.
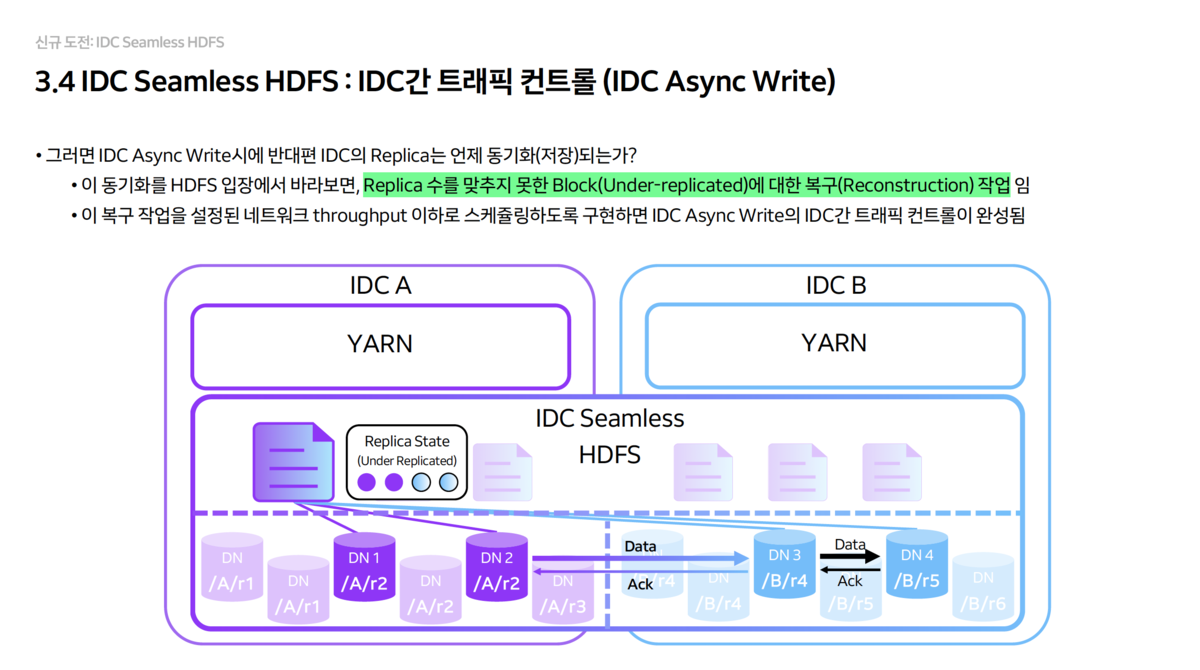
- Write Operation Optimization
- Sync Write: Used when data safety is critical. Writes are performed simultaneously to both IDCs with immediate synchronization.
- Async Write: Used when performance is critical. Writes first to the local IDC, then replicates to the other IDC in the background.
MLXP - Large-Scale MLOps Platform Leading GPU Efficiency
Next, I’ll cover NAVER’s MLOps platform, MLXP. I’ve organized how NAVER, operating thousands of GPUs, maximizes resource efficiency and reliably handles large-scale training/serving workloads into 2 key parts.
Company-wide GPU Resource Integration and Quota System
NAVER was operating GPU clusters using a Private Zone approach, allocating physical nodes to each organization.
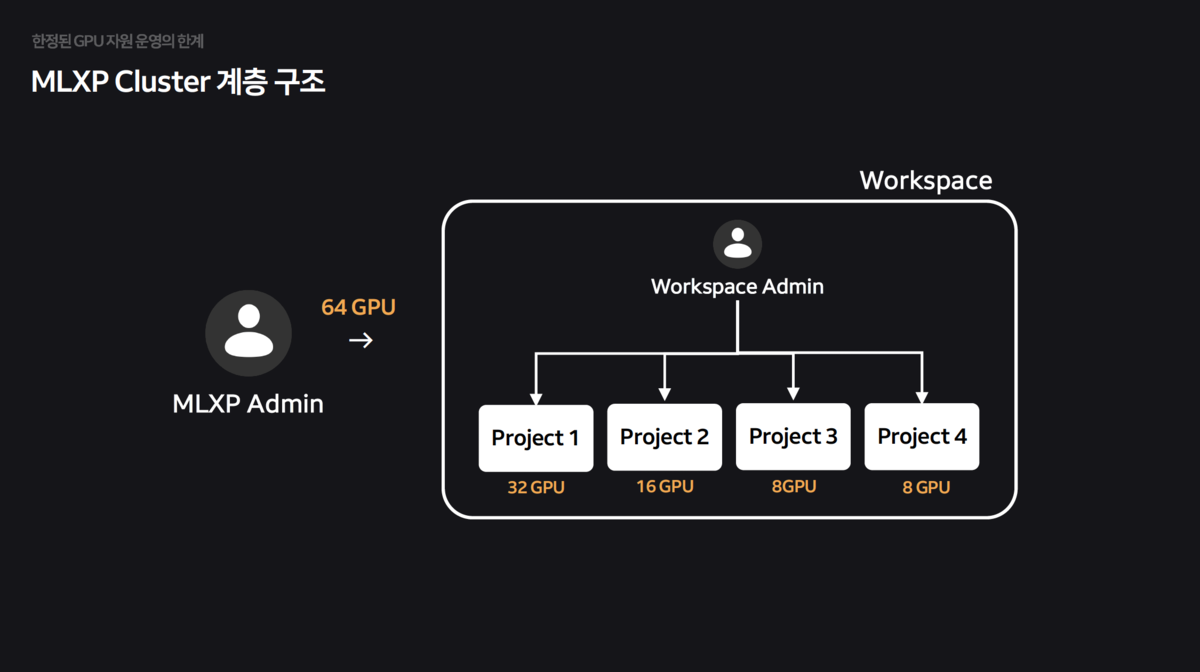
- Imbalances occurred where some teams had idle GPUs while others were waiting due to shortages. Additionally, resource fragmentation worsened as heterogeneous GPUs like A100 and H100 were mixed.
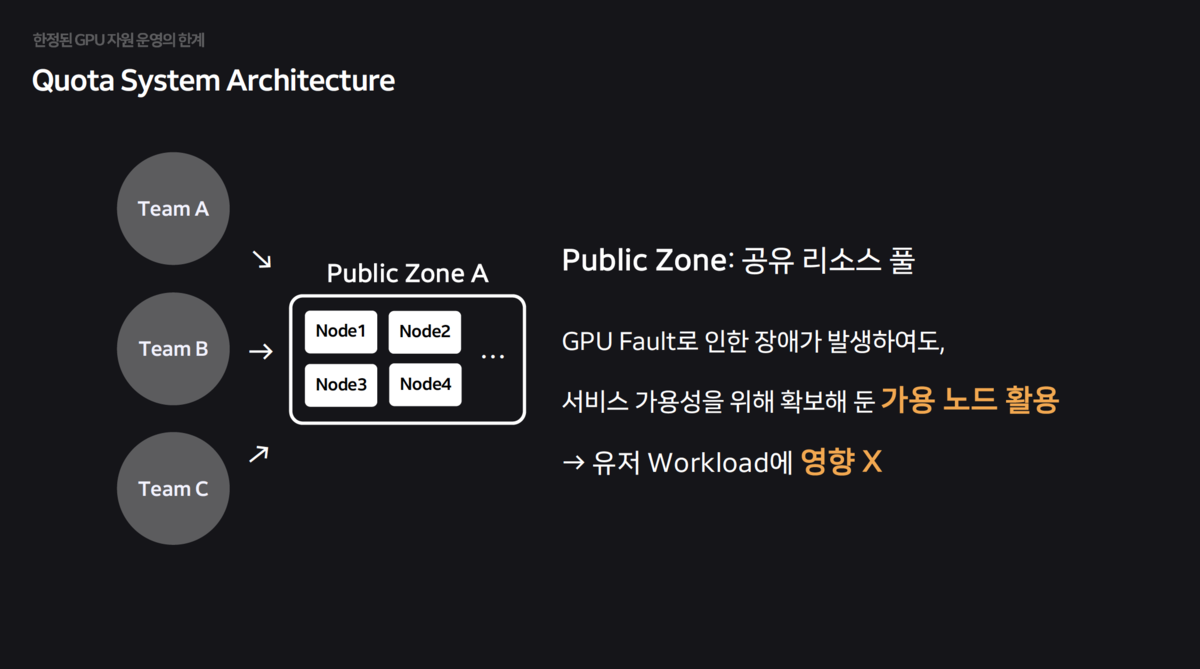
- They broke away from the physical monopoly structure and consolidated all GPUs into a single
shared resource pool (Public Zone)to minimize idle resources.

- Priority Class: Beyond simple consolidation, they developed and applied a systematic quota system.
- Provisioning Type: Workloads are classified as Reserved (guaranteed) or Spot (low-cost/preemptible) based on their characteristics.
- Category & Purpose: Priorities are subdivided by purpose—Serving (high availability), Training (batch), Interactive (development)—to ensure scheduling fairness.
Network Topology-Aware Scheduling Optimized for AI Workloads
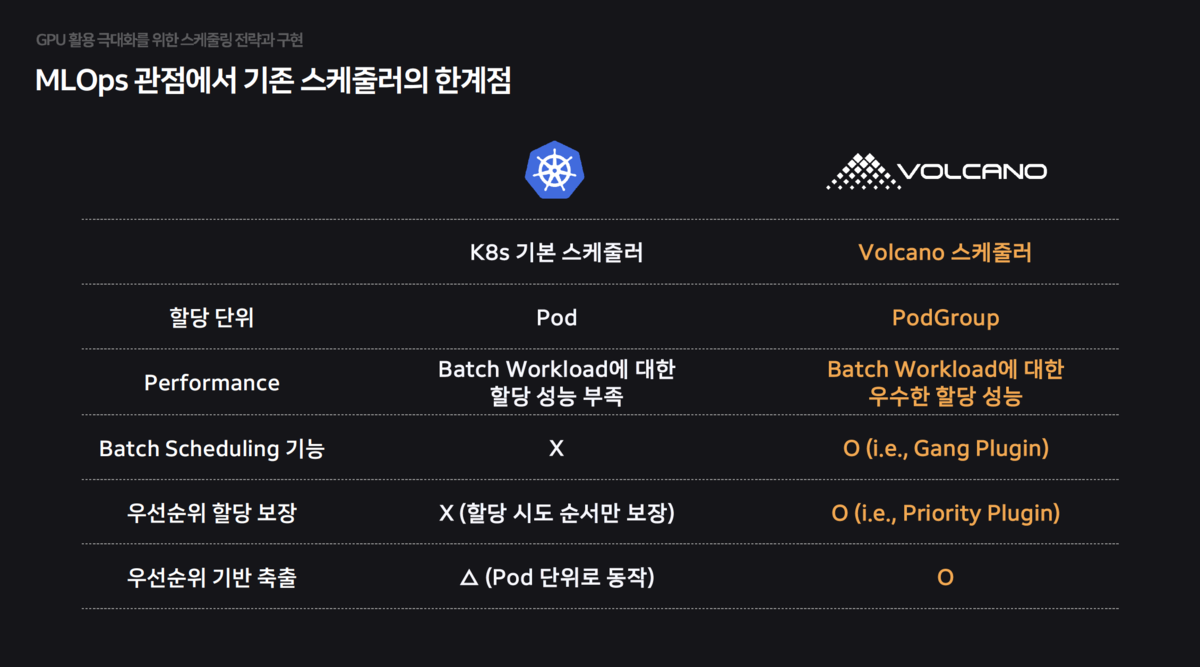
Kubernetes’ default scheduler is not optimized for AI workloads (Batch, Gang Scheduling), causing performance degradation. To address this, they enhanced functionality based on the Volcano scheduler.
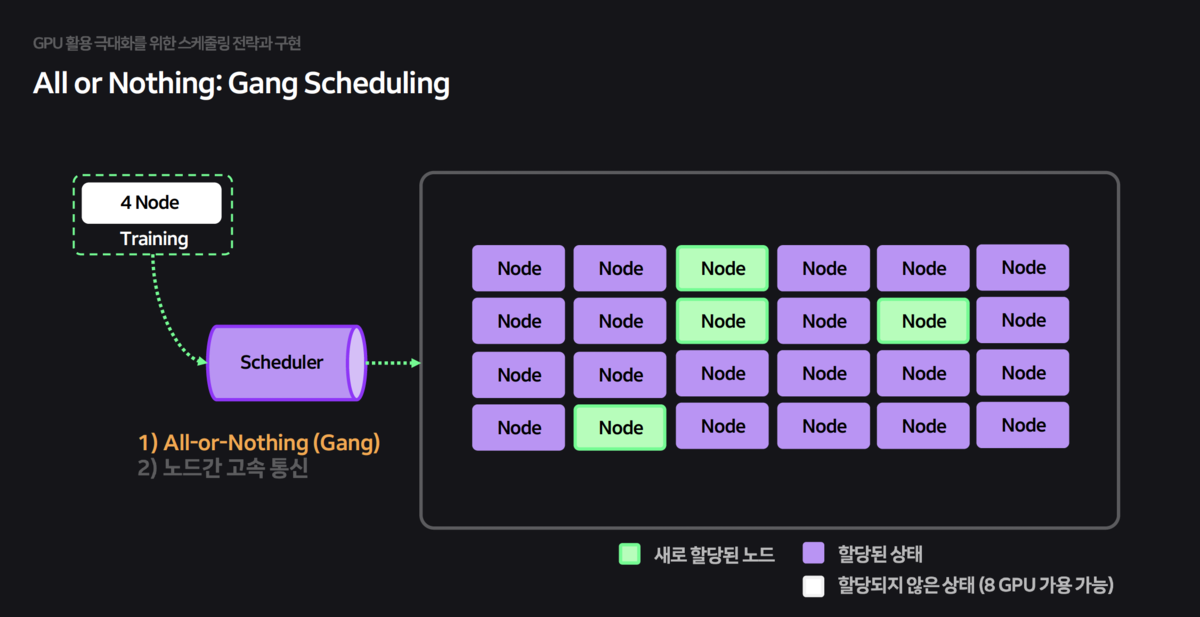
Gang Scheduling:Resources are allocated only when all Pods required for training are ready (All-or-Nothing), preventing deadlocks.
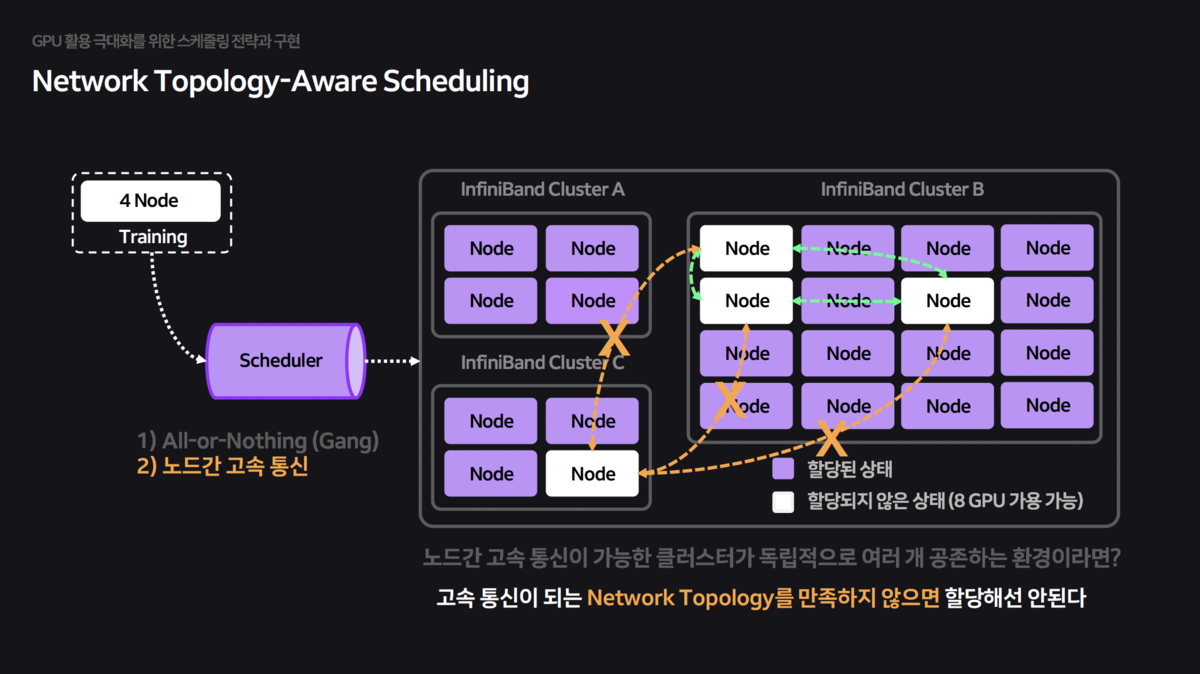
In distributed training, inter-node communication speed determines overall training speed. However, the default scheduler places Pods randomly without knowledge of the physical network structure (InfiniBand Switch connections, etc.), causing severe performance degradation.
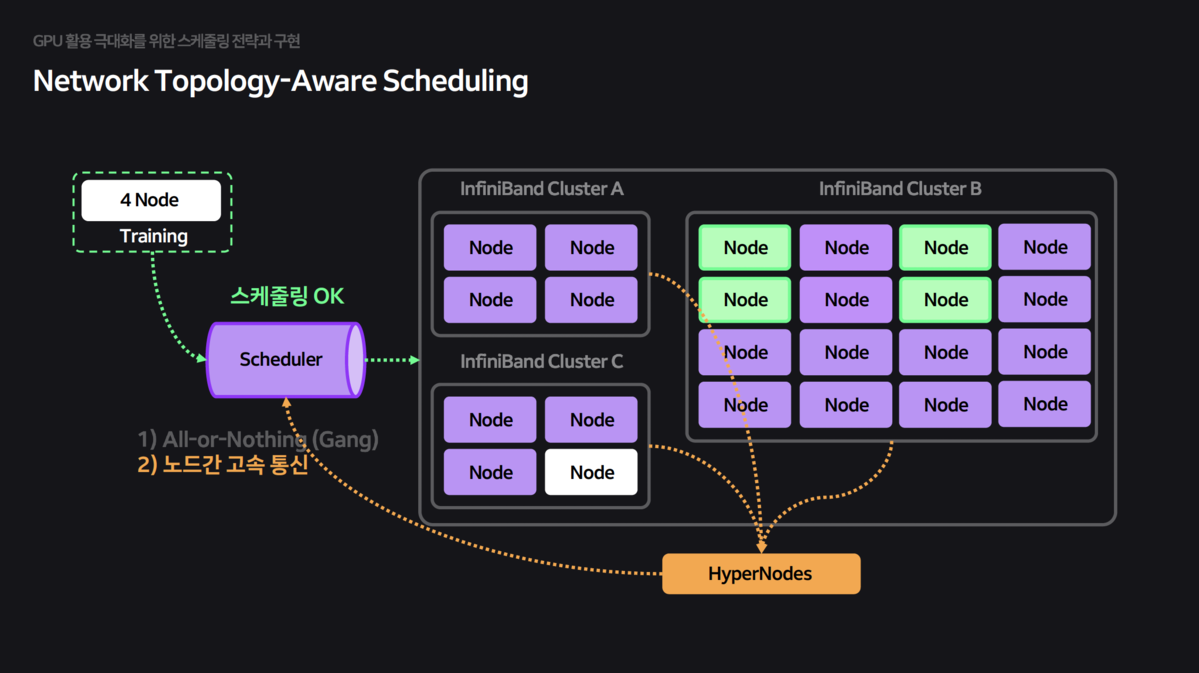
- HyperNode CRD: They implemented HyperNode CRD so that the scheduler recognizes physical network topology and groups Pods on nodes under the same switch for high-speed communication.
HyperNode:A CRD (Custom Resource Definition) containing network topology information was defined for the scheduler to reference.
Takeaways
Technical Insights
The most impressive part of this conference was IDC Seamless HDFS. Since HyperAccel’s development environment is also distributed across multiple clusters, building storage infrastructure that can share data regardless of physical location is an important challenge. NAVER’s 2+2 Replica placement strategy and Read/Write optimization methods will serve as good references for our future infrastructure design.
The MLXP session provided practical insights on operating large-scale AI clusters. In particular, network topology-aware scheduling considering InfiniBand is a key factor that directly affects distributed training performance. Running large-scale LLMs requires nodes equipped with our chips to be connected via high-speed networks, so random placement ignoring topology causes severe performance degradation.
Ultimately, making good AI chips alone is not enough. We reaffirmed that developing the SW stack including schedulers is essential to efficiently utilize our chips.
Reference
IDC Seamless HDFS: Reaching the World of Data Integration Beyond IDC Limitations
MLXP: Large-Scale MLOps Platform Leading GPU Efficiency
P.S.
HyperAccel Hiring
HyperAccel is developing next-generation AI chips for LLM inference. We have completed FPGA verification and will soon release ASIC chips and server solutions. We are creating solutions that developers can easily use through integration with the PyTorch ecosystem.
Career Site: https://hyperaccel.career.greetinghr.com/ko/guide
If you’re interested, please feel free to contact us!