This post is Part 3 of the Memory in the AI Era series. Part 2 covered where HBF can be effectively used (CAG, H³, and candidate workloads beyond them). This part walks through the new workloads HBF must confront and the remaining challenges it has to solve to reach commercialization.
Introduction
Hello. I’m Jaewon Lim from the HyperAccel DV team.
If we summarize the conclusion of Part 2 in a single sentence:
With the right workload, HBF’s weaknesses can be hidden.
We looked at HBF’s weaknesses, the workload conditions that can overcome them, and concrete examples such as SK hynix’s H³ and Georgia Tech’s HAVEN.
But this is a way to hide HBF’s weaknesses, not to overcome them completely. It is a conditional idea that depends on multiple assumptions about the workload. If LLM workloads evolve in a direction that doesn’t really need HBF, demand for HBF will stay limited no matter how mature the technology becomes.
On top of that, HBF’s weaknesses are also NAND Flash’s weaknesses. HBF is a Flash-based alternative proposed to overcome HBM’s capacity limits, and Flash memory is already used in many forms across LLM serving today. So we need to first look at how Flash is actually deployed in production — only then can we get a real answer for how HBF should be used.
In this part, we will look at recent LLM workload trends, examine how Flash memory (SSD) is used in LLM serving environments, and then walk through the challenges HBF still has to solve for commercialization.
Recent LLM workload trends
One of the conditions Part 2 identified for hiding HBF’s weaknesses was that the workload has to be deterministic — because only then can NAND’s long latency be hidden by prefetching. The H³ evaluation rests on exactly this assumption: if we can predict which weights and which KV cache entries the next layer will read, HBF’s weakness can be hidden.
But the way recent frontier models are being designed is starting to shake that assumption.
Sparse attention: using only part of the KV cache
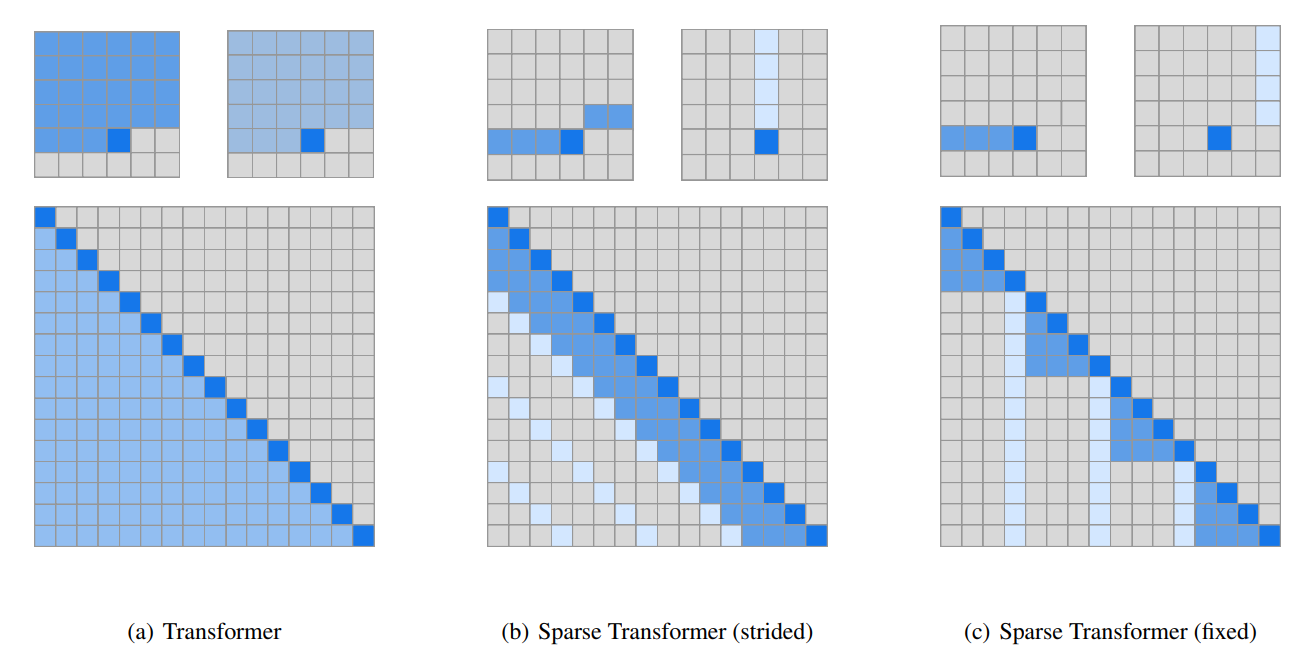
The biggest problem with the attention mechanism — the most important operation in Transformer models — is that compute grows as the square of the input length.
To work around this, recent frontier research reduces attention compute by using only a subset of the accumulated Key-Value pairs, or by using compressed versions of them, lowering both compute and memory traffic. The underlying intuition is that even though attention conceptually relates every pair of tokens, in practice only a small set of tokens truly matter for predicting the next one. Pictured:
The KV cache still has to be computed and stored, so capacity-wise HBF still helps. But each sparse-attention variant uses a different algorithm to select which KV entries are touched, which changes the read pattern.
StreamingLLM: attention sink + sliding window attention
The relatively simple StreamingLLM only computes attention against the first tokens of the sequence and a window of the most recent tokens around the current position. In this case the KV-cache access pattern is close to the original attention pattern, so the addresses to be read are still reasonably predictable.
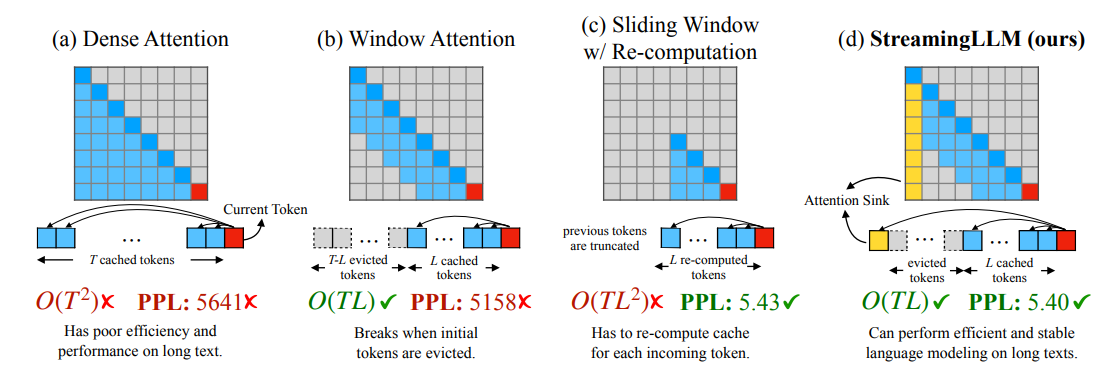
The trade-off is that the current token only sees the first tokens plus its neighbors; relationships with tokens in the middle of the sequence are dropped entirely.
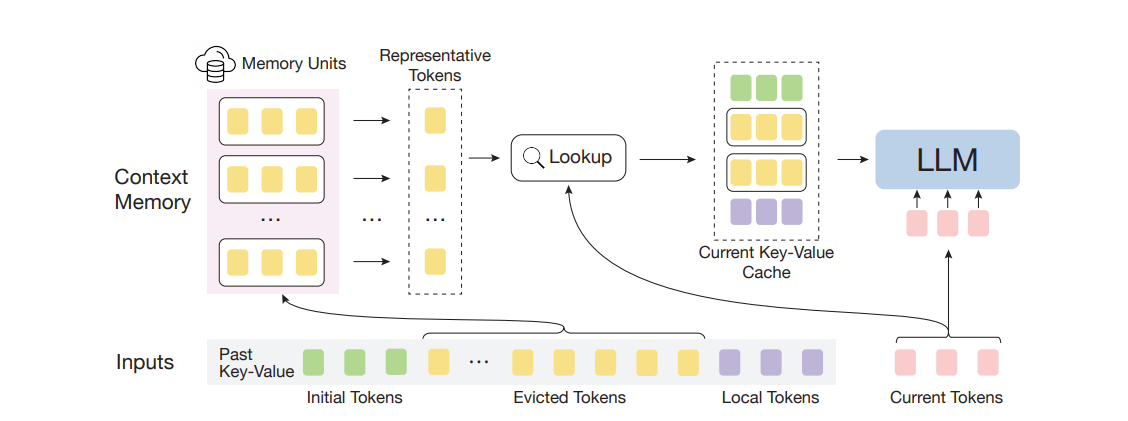
InfLLM & Quest: query-aware sparse attention
The later approaches InfLLM and Quest take a different path. They differ in details, but both use the query of the currently-processed token to compute a coarse score against a subset of the stored KV cache, derive the indices of the Key-Value entries that look most relevant, and then run the actual attention only over those indices. Unlike StreamingLLM, the selected positions change per token, which makes it much harder to predict the addresses to be read in advance. The Keys used to compute those indices also exhibit irregular access patterns.
Compressed Sparse Attention (CSA) & Heavily Compressed Attention (HCA): compressing the KV cache before storing it
The recently released DeepSeek-V4 goes one step further than the selection schemes above and compresses the entire KV cache along the token axis. This shrinks the KV cache that actually participates in attention. Because every KV entry passes through a projection matrix during compression, there is at least one read per entry, but the compressed KV can then be reused repeatedly afterward.
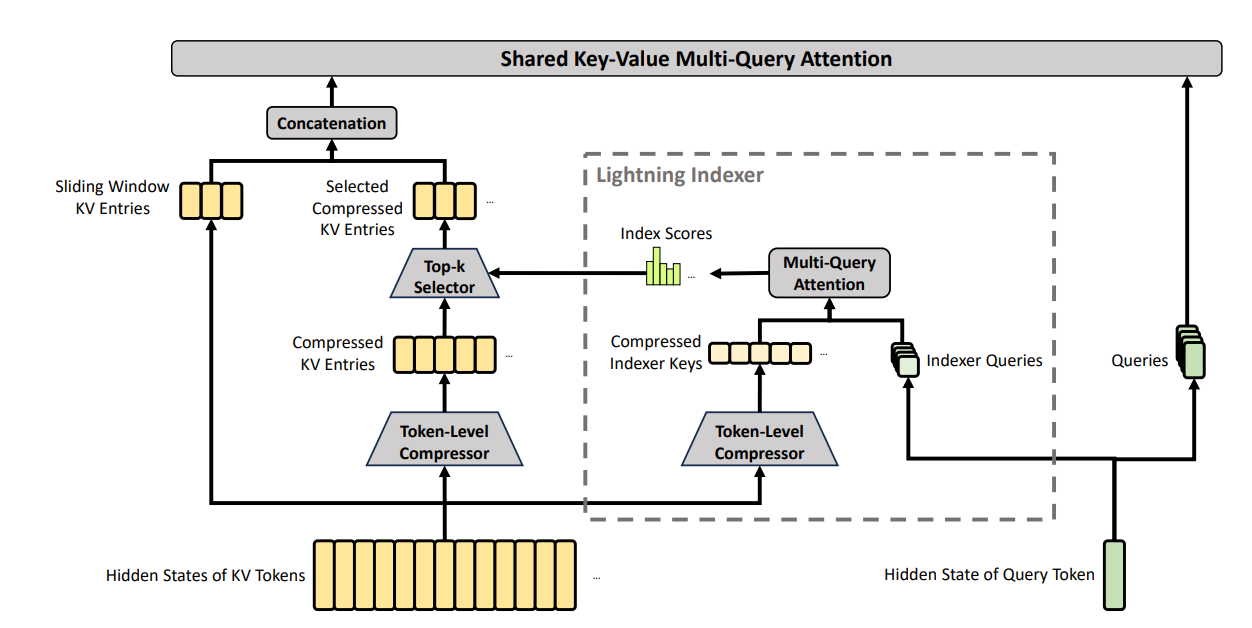
Summarizing the three approaches along two axes — the attention behavior itself, and the KV cache access pattern that matters for HBF prefetching:
| Technique | Attention behavior / limit | KV cache access pattern (prediction view) |
|---|---|---|
| StreamingLLM | Uses only the first tokens and a sliding window of recent tokens. Relationships with middle tokens are dropped | Positions are regular, so prefetch-friendly |
| InfLLM / Quest | Dynamically selects relevant KV indices via the current query. Preserves middle-token information | Indices change per token, so addresses are hard to predict ahead of time |
| CSA / HCA | Compresses the KV cache along the token axis and runs attention only on the compressed version. However, the added compression/reuse pipeline raises implementation complexity | The compressed cache has a deterministic location, so prediction is straightforward |
The emergence of these new software techniques can actually create a new bottleneck for HBF. When the addresses to read become hard to predict, prefetching either misses more often or pulls in more data than necessary. Either case prevents HBF from delivering its nominal performance. Software optimizations that tailor prefetch hints to the attention scheme in use, or hardware-aware model designs, become necessary.
Interestingly, the DeepSeek paper also discusses how this compressed KV cache should be managed in memory. They mention that, during inference serving, they store the compressed KV in SSD storage to take advantage of reuse. This kind of memory-aware optimization will translate directly into upside for Flash-based HBF as well.
This naturally leads us to ask how existing Flash-based SSD storage is already being used in LLM serving.
How SSD storage is used inside LLM services
As covered in earlier posts, the growing KV cache exceeds what GPU HBM can hold, even after applying the compression and sparsity techniques above. To work around this, a wide range of techniques offload the KV cache to CPU memory or even further out — to system memory outside the GPU. Among them, techniques that leverage SSD’s large capacity have been gaining traction.
Model loading: the most basic use of Flash storage
The most universal use of SSDs is storing and loading model weights. DRAM-based HBM is volatile and loses its contents when power is cut, but NAND-based SSDs are non-volatile and are therefore used as the persistent storage for trained model weights. When a service starts up, weights stored on SSD are read into GPU HBM — this is the baseline flow. In particular, environments where multiple GPU nodes serve the same model simultaneously practically require a shared SSD storage tier that every node can reach.
KV cache swapping: pushing inactive sessions to a lower-tier memory
Serving frameworks like vLLM swap inactive sessions’ KV caches out of the GPU when GPU HBM runs short. In a multi-user service, it is impossible to know in advance which session will become active when. A user of an LLM service can pause a question and resume it at any time. If a temporarily idle session keeps holding GPU memory, the system loses headroom to admit new requests. Swapping the inactive session’s KV cache to a CPU DRAM pool — or, for sessions with very large contexts, to SSD — relieves this pressure.
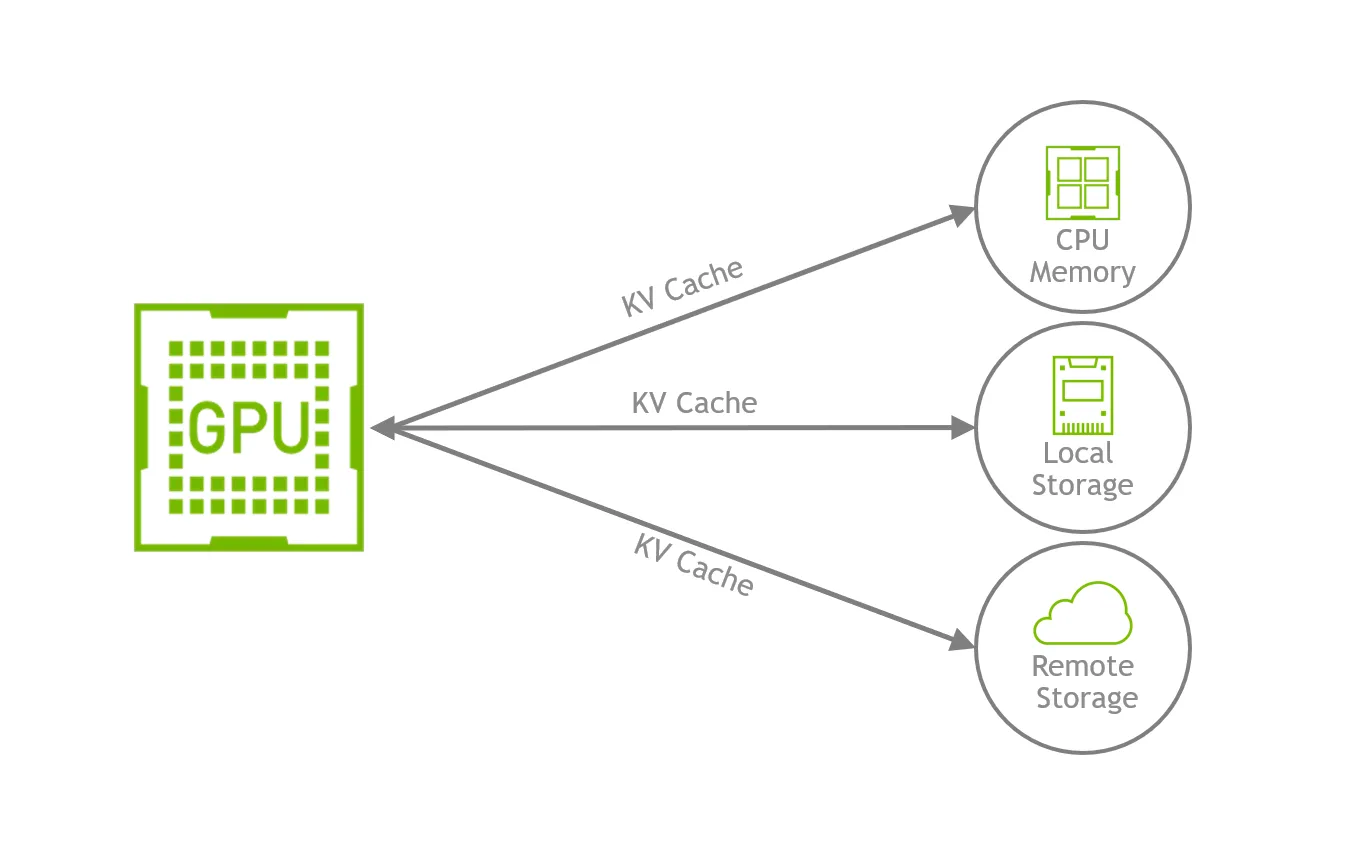
Pushing GPU memory itself onto SSD: offloading and GPU Direct Storage
Going one step further, there are active efforts to expand the dynamic memory used by the GPU onto SSDs. These approaches treat GPU HBM, CPU DRAM, and NVMe SSD as a single unified memory hierarchy and place each tensor at whichever tier best fits the situation.
The fundamental limit of this approach is the data path. The long route SSD → CPU DRAM → GPU, combined with the PCIe bandwidth bottleneck, materially hurts latency and throughput.
To shorten this path, NVIDIA provides GPU Direct Storage (GDS). GDS uses PCIe Peer-to-Peer DMA so that the NVMe controller can read/write directly into GPU memory. Because it bypasses host DRAM, it removes the CPU memory bandwidth consumption and cuts the PCIe traffic in half.
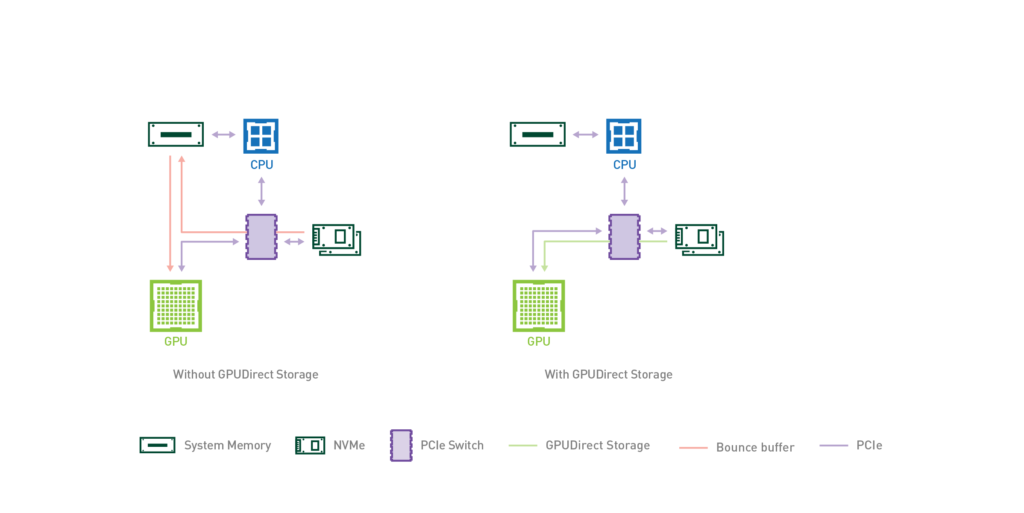
To summarize: SSD/Flash already plays multiple roles across every layer of the LLM serving stack, and a growing set of optimizations is treating HBM — DRAM — Flash as one continuous memory tier. But there is also a structural ceiling visible from these efforts. Moving data from Flash to the GPU still has to go through PCIe, and PCIe bandwidth is much lower than HBM bandwidth, so this segment is an unavoidable bottleneck. SSD’s read latency and the latencies added along the transport path are also limiting factors.
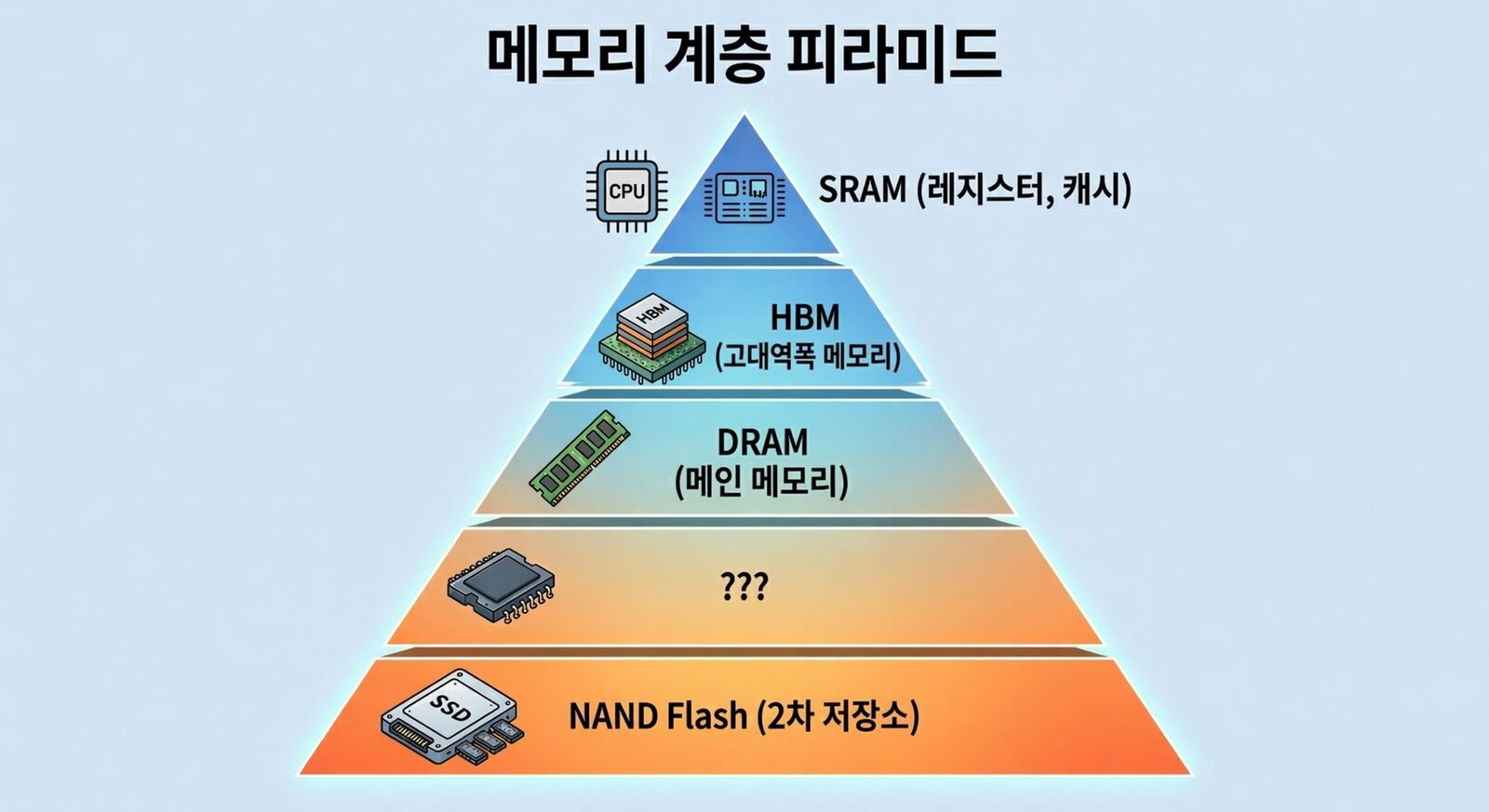
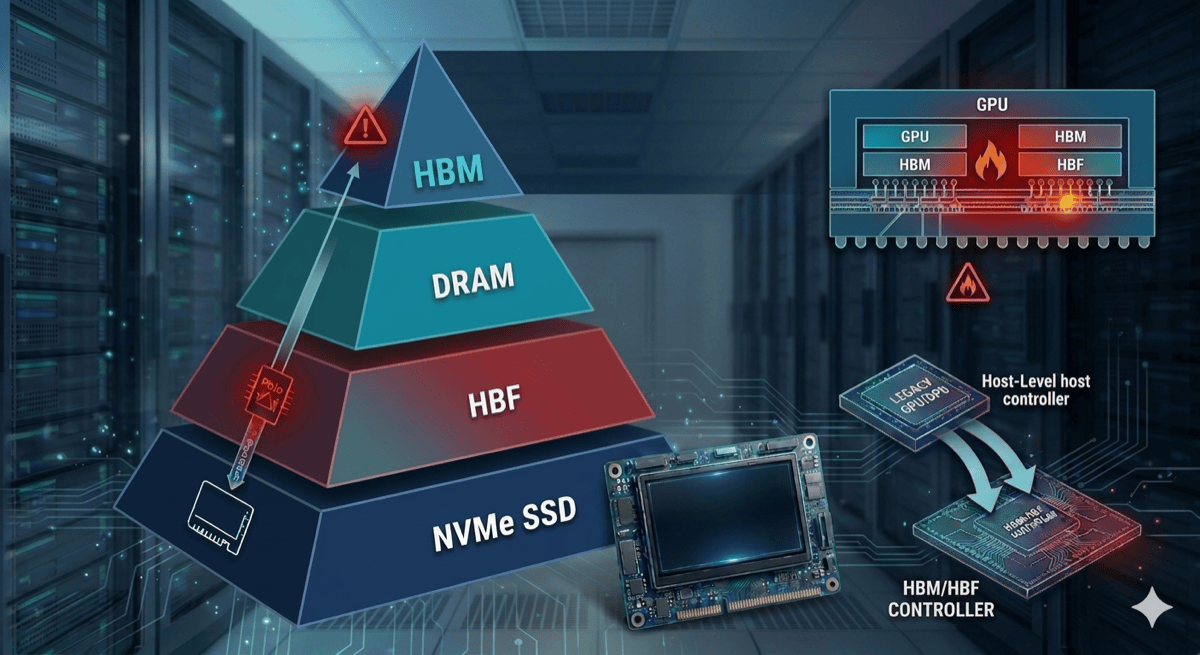
Let’s bring back the memory hierarchy pyramid from Part 1. The slot HBF is aiming for is the empty space between DRAM and SSD. By placing it close to the GPU package it cuts access latency, and by adopting HBM-style stacking + wide interfaces it raises the per-device bandwidth dozens of times above SSD. The point is to plug both structural weaknesses of SSD (distance and bandwidth) at the device level at the same time. If that picture is realized, many of the problems we saw with SSD-based approaches dissolve at the device level.
The catch is that, to make this picture real, HBF has to confront the inherent weaknesses of NAND. Part 2 covered NAND’s most painful one — latency — and the ways to route around it, and the first half of this post laid out why those workarounds don’t generalize cleanly. But there is more left to solve beyond latency. The next section walks through them.
The remaining real-world challenges of HBF
Mismatch between GPU/DRAM and NAND lifespans
The biggest issue is that NAND’s lifespan is not fixed — it depends on the usage pattern. The way data centers use SSDs today is relatively write-light, so SSD lifespan is rarely a serious concern. But if HBF is put in the same position as HBM and starts taking frequent writes, NAND cells wear out quickly, and the memory dies before the GPU/DRAM packaged with it, which typically last 5–7 years. With conventional SSDs, you can just swap a worn drive out. With HBF — what then? This question is tied directly to the still-unpublished packaging and interface standard.
Packaging and interface standards are still undecided
SanDisk, the most aggressive HBF proponent, kicked off standardization work for HBF together with SK Hynix earlier this year. Even with the first samples on the horizon, the detailed spec has not been published yet. What I’m watching more closely than capacity or bandwidth is the packaging and interface standard.
The choice boils down to two options. The first is a PCIe-based connection. PCIe is a battle-tested, low-risk option and can be deployed as a card separated from the GPU, which gives the benefit of replaceability. The catch is that a single PCIe link maxes out at about 64 GB/s even at Gen 5 x16. Compared to today’s SSDs, this brings HBF physically closer to the GPU, but reaching the TB/s class bandwidth HBF targets is physically impossible over PCIe alone.
The second option is HBM-style interposer integration into the package. Just as GPU and HBM are integrated via interposer today, HBF would either be connected GPU → HBF directly, or chained as GPU → HBM → HBF. This is essentially the only way to obtain HBM-class bandwidth, so it is the only path that lets HBF show its real strengths. But the moment GPU·HBM·HBF live in the same package, the lifespan mismatch from the previous subsection turns into no partial replacement possible, and the thermal and power budgets all have to be solved inside that same package.
What ultimately becomes necessary: a more capable controller and software optimization
In conventional SSD-based offloading, much of the data-path orchestration is done by the host CPU or DPU. The SSD’s internal controller only has to handle device-internal behavior, while operational policies like KV cache swap decisions or prefetch are the host’s responsibility. With HBF sitting inside the accelerator’s own package, however, asking the host CPU to mediate every access is no longer viable. Tasks that the CPU/DPU used to handle will likely move into the HBM/HBF controller or the base die itself. HBF will need to be more than plain memory — it will need to absorb part of the system-side policy and become a more capable memory tier.
Software has to evolve along with it. To exploit HBF effectively, applications and frameworks have to be able to tell the controller explicitly which data should sit where. Only when HW and SW are designed under the same assumptions will the lifespan problem and the bandwidth-utilization problem we just discussed actually go away, and HBF’s strengths translate into real-world performance.
Wrap-up
In this post we walked through:
- The evolving patterns in LLM workloads.
- How SSD storage is used in LLM services today.
- HBF’s structural limits and the challenges it still has to solve.
There is also a sense in which HBF’s position in the hierarchy feels a bit awkward. Its role doesn’t map cleanly onto the conventional memory hierarchy. Looking at its raw hardware characteristics, it appears to sit between DRAM and SSD, but in terms of physical placement close to the GPU, it could equally be argued to sit between HBM and DRAM.
The reason for this awkwardness is probably that the new forms of memory in the AI era (HBM, HBF) are fundamentally built on top of older memories — DRAM and NAND Flash. Both HBM and HBF are optimizing for AI compute by applying stacking as a process technique and packaging techniques like interposers and CoWoS to those existing cells. Perhaps this phenomenon is rooted in the fact that DRAM and NAND memories themselves were never fully optimized for AI compute in the first place.
NVIDIA and other established GPU/TPU vendors have been overcoming the memory bottleneck through HBM bandwidth scaling. Groq and Cerebras have showcased a new form of accelerator with on-chip SRAM and their bespoke hardware architectures. We at HyperAccel are overcoming the memory wall with LPDDR and our own hardware optimizations that get the most out of it.
All of them are solving an entirely new kind of problem — AI — with existing memories, existing process and packaging techniques, and HW/SW optimizations on top. But to relieve the more fundamental bottleneck, perhaps an entirely new form of memory — one more suited to AI than what we have today — needs to emerge. Of course, what counts as “AI-optimized memory” is by no means a problem with a single right answer, and an entirely new memory is admittedly a longer-term story. Even so, related discussions are beginning to surface in both academia and industry. I’ll get into more detail on this another time.
What’s next
Parts 1 through 3 of this memory series walked through HBF, a memory that emerged to relieve capacity bottlenecks. But HBF is not the only solution. In the next part, Seungbin Shin will introduce another alternative for the memory problem — CXL (Compute Express Link) technology. Please look forward to it.
Postscript: HyperAccel is hiring!
As the memory hierarchy gets more diverse, the problems an accelerator company has to solve become correspondingly more complex and interesting. Optimized accelerators can only be built when memory and compute logic, software and algorithms — domains that are usually kept separate — are designed as one integrated system. HyperAccel works across HW, SW, and AI. If you’d like to grow with us across a broad and deep range of topics, please apply through our hiring page.
Reference
Sparse Attention
- R. Child, S. Gray, A. Radford, I. Sutskever (OpenAI), “Generating Long Sequences with Sparse Transformers,” 2019. arxiv:1904.10509
- A. Gu, T. Dao, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,” 2023. arxiv:2312.00752
- G. Xiao, Y. Tian, B. Chen, S. Han, M. Lewis, “Efficient Streaming Language Models with Attention Sinks (StreamingLLM),” ICLR 2024. arxiv:2309.17453
- C. Xiao et al., “InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory,” NeurIPS 2024. arxiv:2402.04617
- J. Tang et al., “Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference,” ICML 2024. arxiv:2406.10774
- DeepSeek-AI, “DeepSeek-V4 Technical Report,” 2026. HuggingFace
SSD / Flash offloading
- Y. Sheng et al., “FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU,” ICML 2023. arxiv:2303.06865
- R. Ren et al., “An I/O Characterizing Study of Offloading LLM Models and KV Caches to NVMe SSD,” CHEOPS ‘25. DOI:10.1145/3719330.3721230
- K. Kyung, S. Yun, J. H. Ahn (SNU), “SSD Offloading for LLM Mixture-of-Experts Weights Considered Harmful in Energy Efficiency,” IEEE Computer Architecture Letters, 2025. arxiv:2508.06978
- I. Jeong, S. Woo, S. Namkung, D. Jeon, “HiFC: High-efficiency Flash-based KV Cache Swapping for Scaling LLM Inference,” 2025. OpenReview
NVIDIA technical resources
- NVIDIA GPUDirect Storage Documentation
- NVIDIA Developer Blog — GPUDirect Storage: A Direct Path Between Storage and GPU Memory
- NVIDIA Developer Blog — How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo
HBF