Know Your Enemy, Know Yourself, Part 6: The Agentic AI Era — The Revival of the CPU and the Dawn of the CPU Three Kingdoms
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.” This series aims to deeply understand competitors’ hardware for the sake of designing AI accelerators. In this sixth installment, we cover the datacenter CPU drawing attention again in the Agentic AI era, and the competition among the three vendors Intel, AMD, and NVIDIA.
Hello. I’m Jaewon Lim, a hardware verification engineer on the HyperAccel DV team.
Let me open today’s post with the stock charts of two companies.
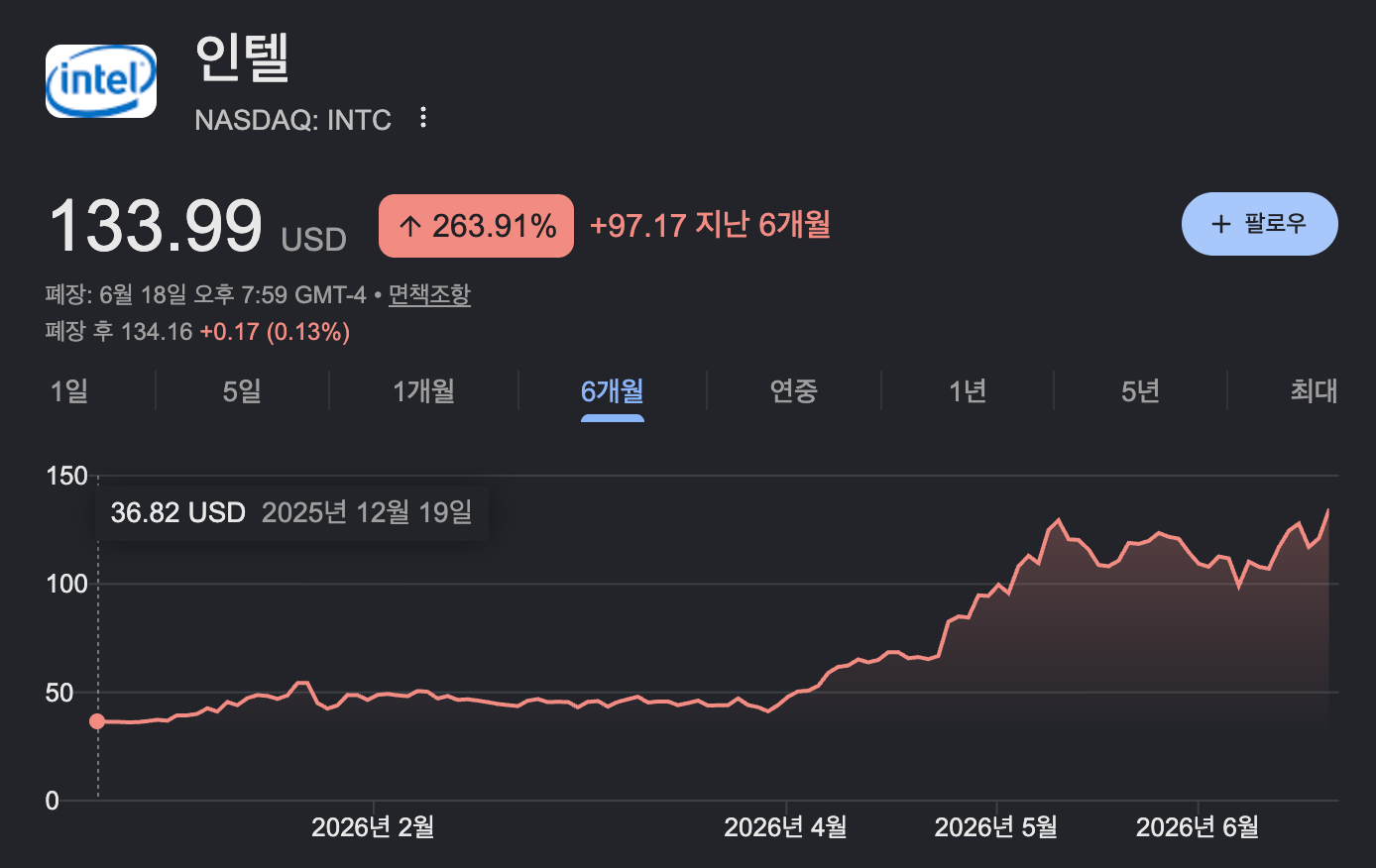
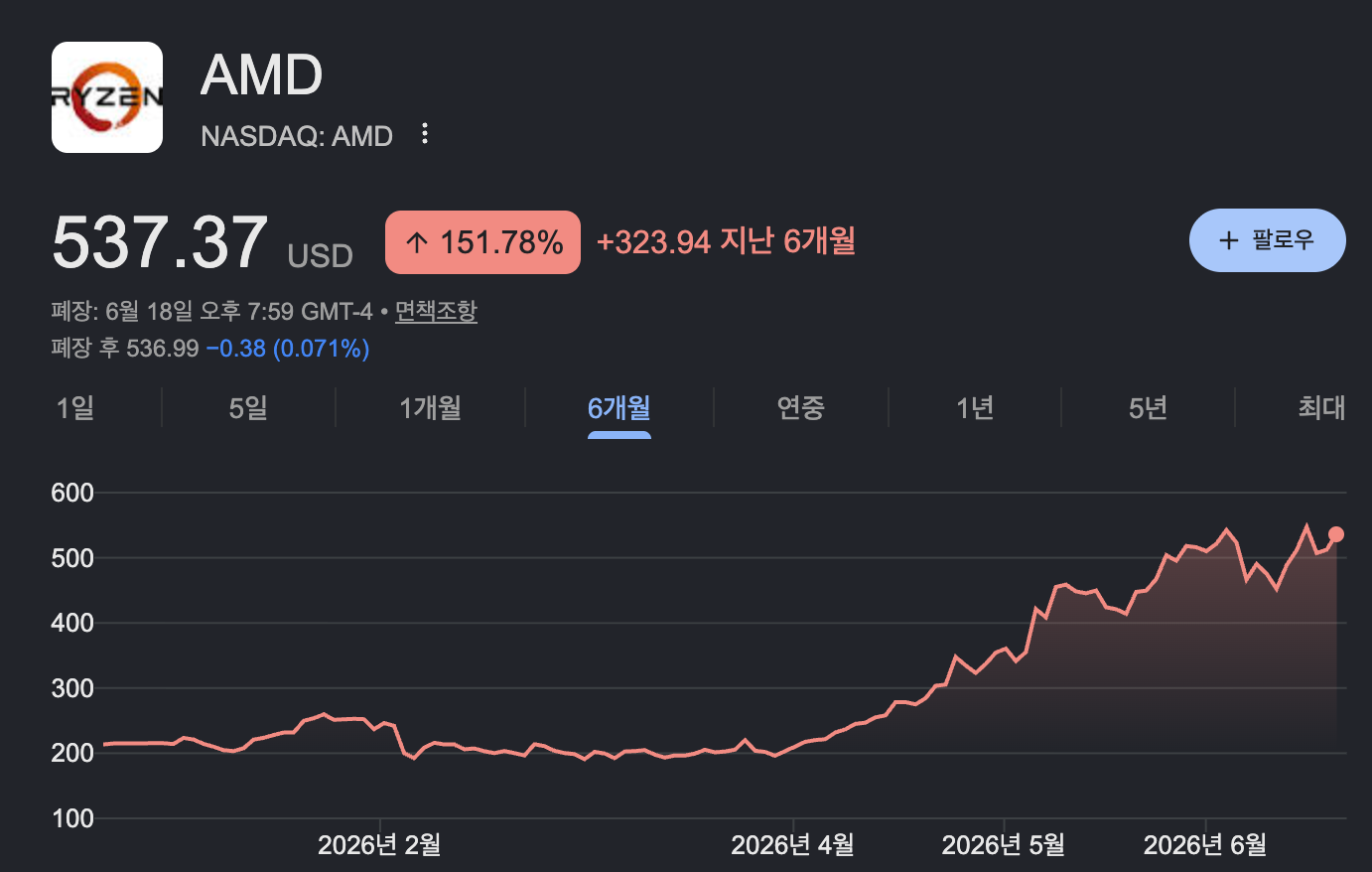
In late April, the day after Intel reported its Q1 earnings, its stock jumped 24% in a single day — its largest single-day gain since 1987. Two weeks later, AMD, which reported afterward, saw its stock rise 18.6% the next day. Behind both companies’ earnings growth was one thing in common: the CPU.
AMD’s datacenter revenue grew 57% year over year and Intel’s 22%, and both cited surging server-CPU demand as the driver. AMD CEO Lisa Su even projected that the server-CPU market would grow to $120 billion by 2030.
If GPUs are the center of AI, why are we talking about CPUs again?
That question is the starting point of today’s post. Everything this series has covered so far — accelerator architectures and various solutions — was about how to optimize the accelerator for AI computation. But as inference workloads shift toward Agentic AI, a paradox has emerged: the very accelerator we optimized so carefully ends up idling, waiting in a ready state. And sitting in that bottleneck is an unexpected component — the CPU.
In this post, we’ll first look at why the CPU has become a bottleneck again in the Agentic AI era, then compare the latest datacenter CPUs from Intel, AMD, and NVIDIA, and consider the CPU war that looks set to follow the GPU war.
Can We Just Add More GPUs? The CPU, Called Back to the Stage
Before we dive in, let’s briefly revisit the relationship between CPU and GPU. We tend to think of the GPU as the star of AI computation, but a GPU cannot execute a single line on its own. The GPU was originally an auxiliary device built to speed up the graphics computations that draw the screen; loading the OS, launching programs, and deciding what to do were the CPU’s job from the start. A CPU can run a computer by itself, but a GPU can do nothing without a host CPU to feed and direct it. From the days of plugging a graphics card into a PC until now, this dependency has not changed.

Later, GPGPU (General-Purpose computing on GPU), represented by CUDA, let the GPU take on general-purpose computation beyond graphics — but that was never an attempt to fully replace the CPU. Heavy, regular matrix computation went to the GPU, while the branch- and control-heavy remainder stayed with the CPU. Then, as the GPU’s price skyrocketed in the AI era, the CPU somehow came to be treated as “the less important part that feeds the GPU.” The lead and supporting roles seemed to have switched.
But the GPU is still not a general-purpose device. And Agentic AI endlessly demands the kind of general-purpose work needed everywhere: hitting search engines, running code in sandboxes, and orchestrating many tools. This is work the GPU cannot do and only the CPU does. This is the point where the CPU, long pushed into a supporting role, is called back to center stage, and a new war over datacenter CPUs begins.
When a bottleneck appears in AI computation, the most common solution that comes to mind is the GPU — a higher-performance GPU, or scaling the infrastructure with more GPUs. Back when running a model through a single pass was the entirety of an AI application, that was generally the right prescription.
But recent studies show a slightly strange picture. According to one study, the time an agent spends calling tools and processing their results took up as much as 88% of total response latency, depending on the workload. And almost all of this tool execution happens on the CPU. The expensive GPU, meanwhile, was idling that whole time, waiting for the CPU’s results.
Even more interesting is another study that showed how to solve this. Here, not a single GPU was added. Instead, the CPU cores assigned to one GPU were increased from 1 to 8. With that alone, time-to-first-token (TTFT) became up to 5× faster.
Without adding any GPUs, simply adding a few CPU cores produced a several-fold speed difference. Has the CPU returned to the front line of computing? Let’s look at the background in the next section.
Why the CPU Matters Again: From a Single Pass to the Agentic Loop
How could simply adding CPUs achieve this kind of performance gain? The answer lies in how the shape of inference has evolved.
Until now, LLM inference ended in a single pass. The CPU splits the input into tokens, the GPU runs it through the model to produce an answer, and the CPU turns it back into human-readable text. In this structure the GPU works almost without rest. The CPU’s job is just the light work of converting tokens at the front and back.
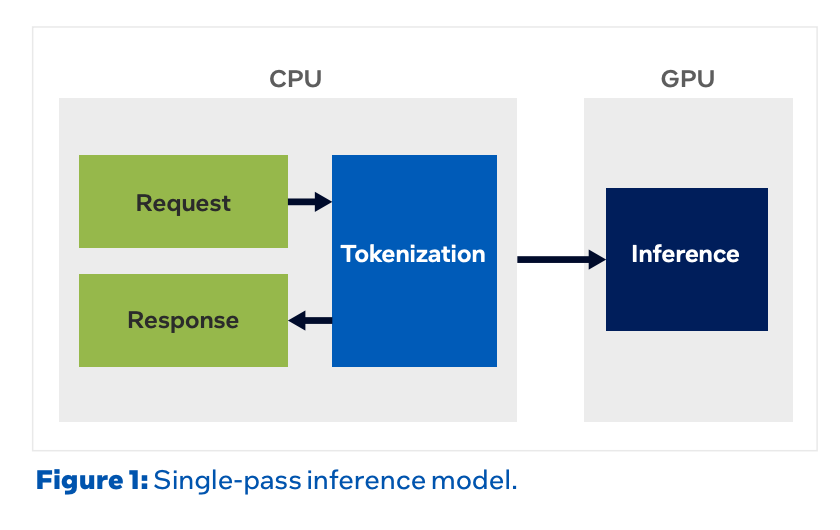
Agentic AI changes this picture. An agent doesn’t stop at producing the model’s answer; it directly creates artifacts like code, documents, and designs. To do so, it repeats a cycle of planning, calling tools, looking at the results, and judging again, many times over. In this process, tool execution, search, code execution, orchestration, and retries are all the CPU’s job. The GPU is specialized only for running the model quickly, so apart from that one moment, the CPU shoulders everything else. In the end, the GPU works only at the instant of passing through the model, and stalls — waiting — while the CPU runs the tools.
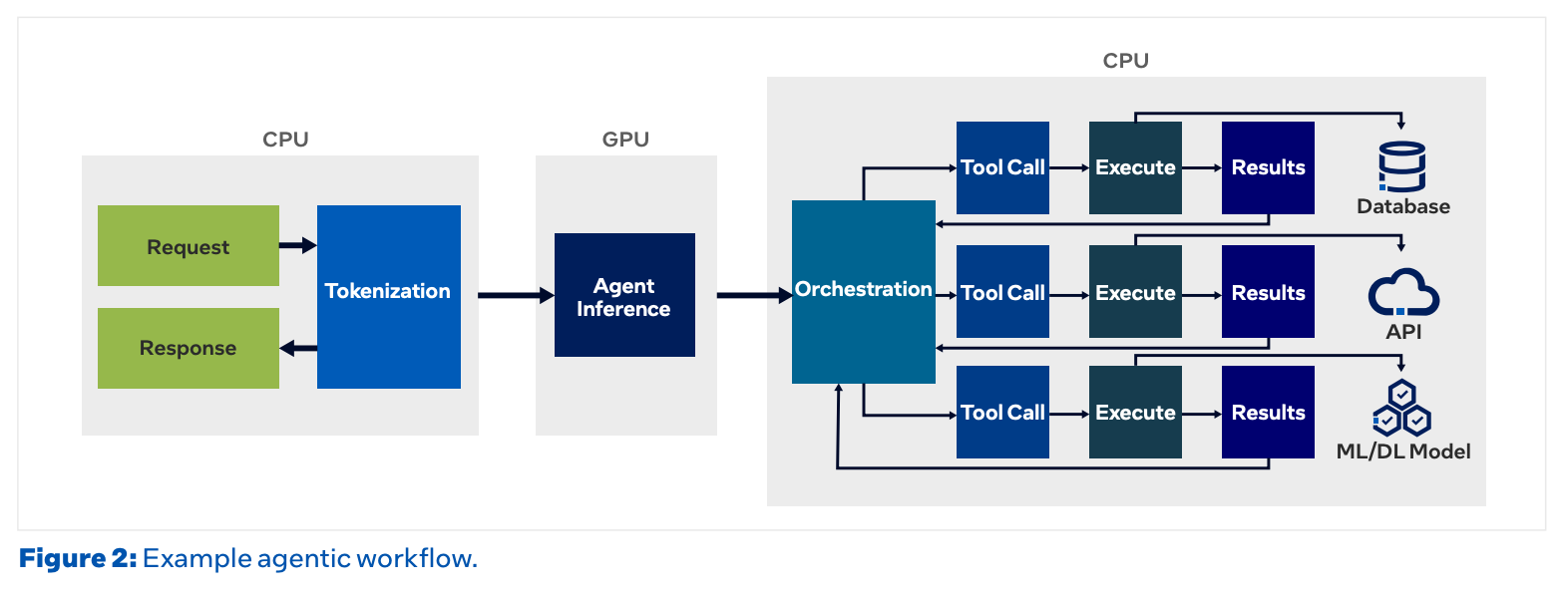
So what exactly does the CPU take on? Broadly, three things.
First is information retrieval. Tasks that fetch external knowledge, like RAG (Retrieval-Augmented Generation), vector-DB lookups, and database queries. Because they rummage through huge indexes and move back and forth across disk and network, they consume a lot of memory, and since the CPU performs better here, the CPU mostly handles them.
Second is code execution. Agentic AI is used especially heavily for coding tasks. Code the model produces goes through a step that checks whether it’s valid before being handed to the user. At that point, an isolated sandbox (a container or a separate process) is spun up to run Python or a shell inside it. This too is typical CPU/OS work.
Third is connecting task to task. Orchestration — preparing tool calls, parsing the returned results, deciding the next step, and retrying on failure — runs ceaselessly on the CPU.
To borrow Intel’s framing, Agentic AI makes inference less like one giant program such as an LLM and more like microservices in which many small services cooperate. Control flow, tool calls, retries, and coordination all happen on the CPU. As a result, a substantial portion of the time a single task takes — by some measurements 30–90% — stays on the CPU.
The Cost Paradox
The paradox is cost. Based on cloud-instance pricing, GPU compute is 100× to as much as 1,600× more expensive than CPU. Yet the cost of adding CPU cores to relieve this bottleneck came to only about 1.5% per server. Using a bit more cheap CPU to keep the expensive GPU from idling is by far the better deal.
Moreover, the earlier studies say that “the better the GPU gets, the faster the bottleneck shifts to the CPU.” The faster a next-generation GPU runs the model, the greater the relative burden on the CPU executing other work in the meantime. In the end, scaling the GPU alone won’t solve this problem; better CPUs and more CPUs become necessary. So now let’s turn our gaze to the CPU itself — and to the companies that make CPUs.
From a Two-Way to a Three-Way Race — NVIDIA Enters the CPU Fight
Traditionally, one CPU in a server commanded 4–8 GPUs. In the agentic era, this ratio flips. Intel claims that the faster next-generation GPUs get, the more CPUs — up to 7 — may be needed to properly operate a single GPU.
So every company that makes CPUs is shouting, “It’s the age of the CPU again.” And here a name that hadn’t been visible appears — NVIDIA, the GPU maker. NVIDIA has jumped directly into the CPU race.
This is actually half true and half false. NVIDIA walking into the middle of the datacenter-CPU race is clearly a new event, but it does not mean “NVIDIA is making a CPU for the first time.” A GPU can’t start anything on its own. Booting, and dividing up the work to compute, are all handled by the CPU (host) attached beside it. So NVIDIA has long built its own CPUs to command its GPUs.
It’s just that the stage wasn’t the datacenter. The traditional datacenter and PC markets were held tightly by Intel and AMD, who own x86, and there was almost no room for NVIDIA — which has no x86 license — to squeeze in. So NVIDIA’s CPUs mostly took the form of Tegra, an Arm-based SoC, settling into game consoles like the Nintendo Switch and into mobile and automotive embedded areas.
But NVIDIA, using the core-design know-how it accumulated along the way and its compatibility with its own GPUs, expanded the stage to datacenter CPUs sold “together with the GPU,” centered on the Arm ISA. Grace, paired with Hopper and Blackwell, was the first fruit. And finally, at GTC Taipei in June 2026, NVIDIA unveiled Vera — built with cores it designed itself, unlike Grace, which borrowed licensed Arm cores — declaring it was taking direct aim at the datacenter-CPU market. This is the moment the CPU war, long a two-way race between Intel and AMD, turns into a three-way race. In the next section we’ll take apart the three companies’ CPU architectures side by side.

A Close Look at the Three Companies’ CPU Architectures
① x86 vs Arm
The most fundamental line dividing the three companies isn’t how large they made the cores, but which instruction set (ISA) they built the cores on — Intel and AMD on x86, NVIDIA’s Vera on Arm. An ISA (Instruction Set Architecture) is the contract between software and hardware: it fixes the kinds and formats of instructions a program can give the CPU, and the register specifications. Within the same ISA, a program compiled once runs on any chip built on it; with a different ISA, the same program must be recompiled.
x86 and Arm differ from the very philosophy of how they write this contract. x86 started from the CISC (Complex Instruction Set Computer) family, where one instruction handles complex work and lengths vary (variable length). Arm is in the RISC (Reduced Instruction Set Computer) family, breaking instructions into simple pieces and fixing the length at 4 bytes. Today, both camps internally convert instructions into finely sliced micro-operations (µops) before executing, so this boundary has blurred considerably — but one difference remains to the end: the cost of decoding instructions. Because x86 has uneven lengths, it must first find instruction boundaries, making the decoder complex and more power-hungry; because Arm has fixed lengths, it’s easy to decode several instructions side by side at once, which is favorable for widening the decoder. This is why Arm-architecture processors were widely used as APs (application processors) back in the mobile era.

Then wouldn’t the efficient Arm architecture be advantageous even in AI computation, where power matters? Its performance has also risen enough not to lag behind x86 — but the reality isn’t easy. x86’s real moat is not performance but compatibility. Decades of operating systems, enterprise software, and drivers are all compiled to x86 binaries, and moving these assets costs enormously. On top of that, the companies that can actually make x86 are effectively just Intel and AMD, so that fence itself is a barrier to entry.
Arm’s weapons, by contrast, are efficiency and openness. Originating in mobile, it was designed with “performance per watt” as the top priority, and by opening its ISA via licensing, it let anyone design their own core on top of it. Apple’s M series, and NVIDIA’s Grace and Vera, were all made this way. In the datacenter, where performance-per-watt and core density are operating costs, this philosophy is gaining momentum — and it’s also why NVIDIA chose Arm over x86.
Parallel-Computation ISA Extensions
On top of this base ISA ride extension instructions for quickly processing vector/matrix computation. Most basic instructions process operations one at a time at scalar granularity, so computing multiple pieces of data requires that many instructions. To raise throughput by performing parallelizable work with a single instruction, SIMD (single instruction, multiple data) instructions were created. This is the concept we also explained in the GPU installment, and the CPU uses it for performance gains as well.
The x86 camp (Intel/AMD) uses AVX (Advanced Vector Extensions)-based SIMD units, which fix the vector length, as a common foundation, while the Arm camp uses SVE (Scalable Vector Extension), a variable-length vector extension. Up to here it’s a difference the ISA carved out, but even within the x86 camp, Intel’s and AMD’s approaches diverge.
Intel added a dedicated 2D tile matrix engine, AMX (Advanced Matrix Extensions), inside the core on top of AVX. AMX is a dedicated unit that processes multiply-accumulate at matrix granularity rather than 1D vectors; one core processes 2,048 multiply-accumulates per cycle at INT8 and 1,024 at BF16/FP16. With this dedicated matrix engine, small models (SLMs) can be inferred with the CPU alone, without a GPU.
AMD processes matrix computation with AVX-512 and VNNI (Vector Neural Network Instructions), without a dedicated tile engine. The hardware processing density is lower than a dedicated 2D matrix engine, but existing SIMD units can perform matrix computation well enough, and heavy computation is handed to the GPU.
In addition, Intel and AMD jointly announced the ACE (AI Compute Extensions) specification to standardize CPU-side AI matrix-computation extensions in the x86 ecosystem. This is a standard meant to let x86 perform AI computation with general-purpose compute units, without a dedicated unit like AMX.
NVIDIA’s Vera takes the path of Arm SVE2 plus native FP8. It has no dedicated tile engine, but uses variable-length vector units and FP8 support to handle part of the inference computation, handing heavy matrix computation to the GPU.
② Multithreading — Split Time, or Partition Space?
After ISA, the point where the three companies’ CPU-design philosophies diverge most clearly is multithreading. Here NVIDIA takes a fundamentally different path from the two x86 companies.
Multithreading (hardware multithreading) is a technique that puts multiple threads on a single core at the same time. If a core runs only one thread, then when that thread stalls waiting for memory, the expensive execution units idle entirely. So two threads are placed together on one core, so that while one is stalled, the other fills the empty units. Intel calls this Hyper-Threading and AMD calls it Simultaneous Multi-Threading (SMT), but the principle is the same. The crux is “how two threads share one core’s resources,” and here the path splits in two.
Time-shared SMT (Intel · AMD). Traditional 2-way SMT has two threads share core resources — decoder, execution ports, registers — dynamically over time. Because they split whatever is free each cycle, a single thread monopolizes the whole core when alone, and the two compete when running together. Average throughput is high, but if the neighboring thread uses a lot of resources, my thread slows down, so per-thread performance and tail latency become uneven.
Spatial multithreading (NVIDIA Vera). Vera’s Olympus core takes a different direction. Instead of taking turns by slicing time, it physically partitions core resources between the two threads, so each thread gets a fixed (and correspondingly reduced) set of resources. 88 cores split this way 2-way become 176 threads. The peak speed a single thread can reach may be lower than time-shared SMT, but its advantage is that my thread’s latency doesn’t waver no matter what the neighboring thread does.
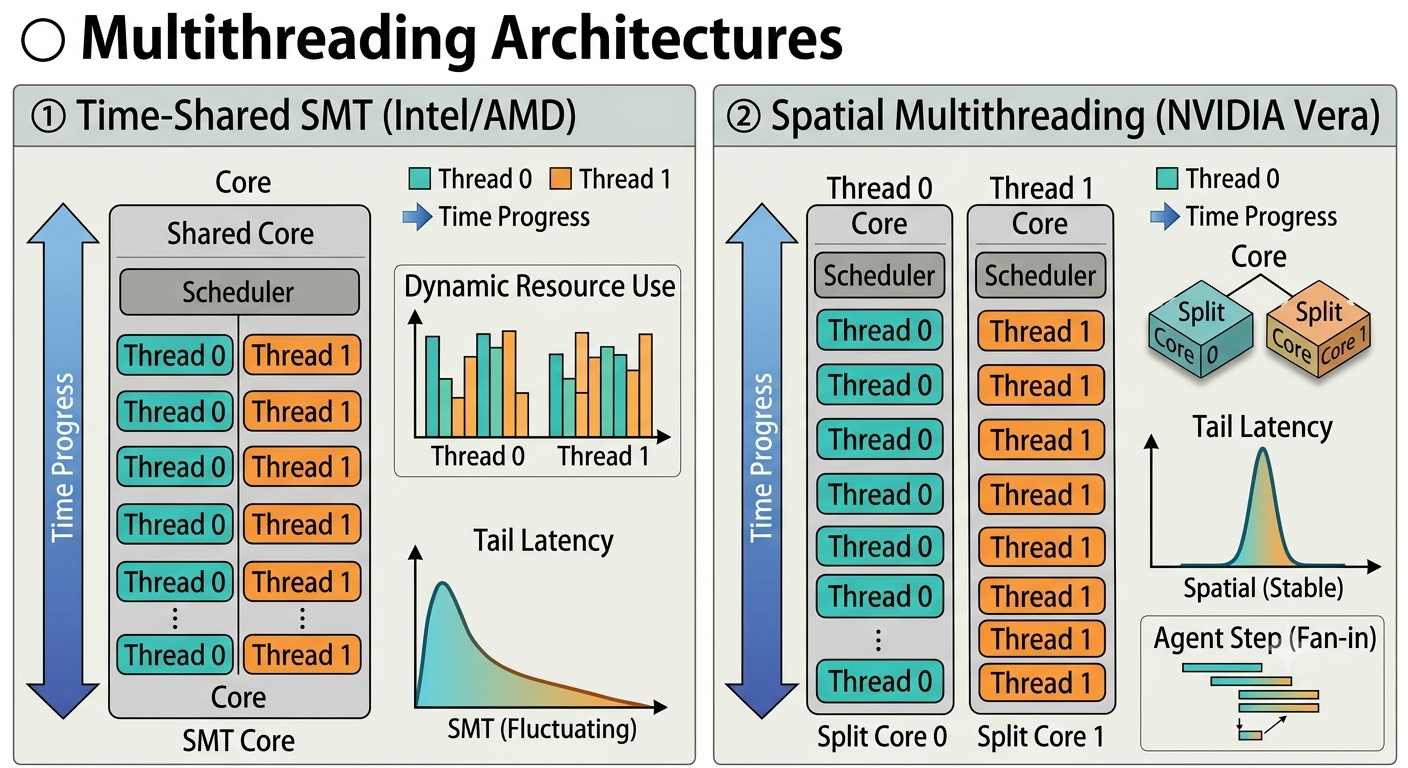
This difference matters in agentic workloads. A single agent step spreads out tens or hundreds of tool calls and sandbox sessions at once, and only after all their results gather does it move to the next inference (fan-out/fan-in), so the step’s completion time is determined not by the average of the sessions but by the single slowest one. In time-shared SMT this tail sways with the neighboring thread’s resource competition (noisy neighbor), but physically partitioning resources fixes each session’s latency independently of its neighbors, stabilizing tail latency. In the end, what matters becomes not a single thread’s peak speed but every session finishing within a predictable time.
③ CPU-GPU Link
The last is the link connecting CPU and GPU. Not only must results computed on the CPU be delivered to the GPU, but when KV-cache capacity exceeds the GPU’s HBM capacity, CPU memory must be used — so this link becomes even more important.
Intel and AMD use standard methods. Xeon connects CPU and GPU via PCIe 5 / CXL, and EPYC via PCIe 5 / Infinity Fabric. PCIe 5 is about 64 GB/s per direction on x16 lanes — roughly 128 GB/s even combining both directions.
NVIDIA uses its own specification. Vera becomes one body with the Rubin GPU through a coherent interconnect called NVLink-C2C, reaching 1.8 TB/s. This is a full 2× increase over the predecessor Grace’s 900 GB/s.
Summarizing the three axes we’ve looked at so far in one table:
| Category | Intel Xeon | AMD EPYC | NVIDIA Vera |
|---|---|---|---|
| Current-gen flagship | Xeon 6980P · Redwood Cove | EPYC 9755·9965 · Zen 5 / 5c | Vera · Olympus (custom Arm) |
| Instruction set (ISA) | x86-64 (CISC family) | x86-64 (CISC family) | Arm Armv9.2-A (RISC family) |
| Cores / threads | 128C / 256T | 128C/256T (9755) · 192C/384T (9965) | 88C / 176T |
| Matrix-compute ISA | AMX + AVX-512 (dedicated tile matrix engine) | AVX-512 / VNNI (SIMD-based matrix compute) | SVE2 + FP8 |
| ② Multithreading | 2-way time-shared SMT | 2-way time-shared SMT | 2-way spatial multithreading (physical resource partition) |
| ③ CPU-GPU link | PCIe 5 / CXL | PCIe 5 / Infinity Fabric | NVLink-C2C 1.8 TB/s (coherent) |
Wrapping Up
Today we looked at the CPU, risen again in the Agentic AI era. As inference shifted from a single pass to a loop that calls tools, control and tool execution came down to the CPU, and a new bottleneck appeared in between — the expensive GPU sitting idle. Several experimental results showed this clearly: tool execution took up a substantial portion of response latency, and simply adding CPUs instead of GPUs made things faster.
In this situation of growing CPU demand, NVIDIA has declared its entry into the market that Intel and AMD had split between them. With an approach very different from the two, and high performance achieved on the back of its GPU-infrastructure know-how, it is amplifying customers’ expectations. No benchmark directly comparing the three CPUs on the same agentic workload exists yet, but judging by the announced performance alone, I suspect the CPU market is heading toward a three-way structure.
What’s interesting is that this trend grows stronger the more you scale the GPU. The faster a next-generation GPU runs the model, the greater the burden on the CPU, which has to run tools and send back responses in the meantime. From the standpoint of designing an AI accelerator too, how to choose the host CPU and how to connect it is becoming an ever more important question.
P.S. HyperAccel Is Hiring
HyperAccel is on the verge of launching its first datacenter LPU product, and through hardware/software optimization, we’re developing technology that resolves the core bottlenecks of LLM inference and delivers efficient service.
If our technical journey interests you, apply right now through HyperAccel Career!
HyperAccel is waiting for your application.
Reference
Earnings & market reaction
- AMD Reports First Quarter 2026 Financial Results (official IR)
- Intel Reports First-Quarter 2026 Financial Results (official IR)
- Intel’s stock has best day since 1987, soaring 24% — CNBC (2026-04-24)
- AMD (AMD) Stock Price History — stockanalysis.com
Agentic AI and the CPU bottleneck (research & analysis)
- Ritik Raj et al., “Towards Understanding, Analyzing, and Optimizing Agentic AI Execution: A CPU-Centric Perspective” (arXiv:2511.00739)
- Euijun Chung et al., “Characterizing CPU-Induced Slowdowns in Multi-GPU LLM Inference” (arXiv:2603.22774)
- The CPU Bottleneck in Agentic AI and Why Server CPUs Matter More Than Ever — viksnewsletter
- SemiWiki, “Agentic AI Demands More Than GPUs” (2026-04-08)
CPU:GPU ratio rebalancing · supply/demand
- TrendForce, “The Great Rebalance: How Agentic AI Is Reshaping the CPU:GPU Ratio” (2026-04)
- Tom’s Hardware, “‘CPUs are cool again’ — agentic AI drives a surge in CPU demand and shortages” (2026-04)
- Tom’s Hardware, “Rising CPU demand for AI workloads drives shortages and price hikes” (2026-04)
Vendor materials
- Intel White Paper, “Agentic AI Requires More CPUs” (2026)
- AMD Blog, “Agentic AI Changes the CPU/GPU Equation” (2026)
- NVIDIA, “NVIDIA Unveils Vera, the CPU for Agents” — GTC Taipei 2026 (2026-05-31)
- NVIDIA Vera CPU product page — “The CPU for agents”
CPU architecture comparison